When I was a software developer manager, there were a lot of questions. Questions that my boss asked me. Questions that I had myself. Questions that arose when discussing work with my team. And most of these were questions to which I did not have a good answer. I couldn’t respond well to them because I didn’t have the data necessary to give a definitive answer.
The data was there, but without a way to get at it, I often felt like I was stumbling in the dark. But all is not lost. Here are eight questions that I had, and ways that data inside your tools can be used to answer them.
How quickly is work moving through our pipeline?
One of the most important things that you need to know as a Dev Manager is how long things are really taking to get done. Not how many hours something is worked on, but rather how much actual calendar time it is taking to get a given user story or project from start to finish.
Most often, success was defined as completing things by a certain date. I’d break things down into sub-tasks, estimate those tasks, and then keep an eye on things. We’d make mid-course corrections by the eyeball test. But it was all an imprecise science at best.
First, breaking things down into workable chunks is hard. The chunks may or may not be appropriately sized, and they may or may not be correctly estimated. And of course, a given sub-task isn’t really done until it’s code reviewed, merged, and deployed.

This is where Cycle Time comes into play. Cycle time measures the amount of calendar time that happens from the moment that a branch is created until the moment that branch makes it into production. Along the way, it measures four sub-items:
- Coding Time
- Pull Request Pickup Time
- Pull Request Review Time
- Deploy Time
Cycle time is useful in a number of ways. First, it helps you see if you are breaking your work into the correct size chunks. If Coding Time starts rising, perhaps you are making those code chunks too big or too challenging.
Second, the process of creating, reviewing, and completing Pull Requests can become a bottleneck. Being able to see how that process is moving along is valuable information. Seeing it rise let’s you know that there is an issue and enables you to do something about it before it becomes a problem.
Finally, knowing how long it takes to deploy your code — actually get it to the place it needs to be — is critical. For some sites, that might actually be production code. For others, it might just be a delivery to QA. Either way, knowing the time that the whole process takes can give you good insight into how to manage it.
Overall, Cycle Time gives you keen insight into how things are progressing and can provide a “canary in a coal mine” warning of project trouble.
What’s stopping us from focusing on our priority work?
One of my great frustrations as a dev manager was when my team ended up doing non-project work. Sometimes they were asked to do things outside of their sprint work — often by people with positional authority to get the team to do those things. Occasionally they would venture off on their own to try something that wasn’t necessarily productive. In any event, I wouldn’t always know about it, and I would have liked to have known.
Specifically, I would have liked to know if code was being worked on that didn’t relate directly to a project ticket. Interestingly, the information is there in the repository, but not necessarily easy to find. Normally, branch names have some relation to the project ticket identifier — or at least they should. If you maintain a standardized way to name your branches, you can track code branches that aren’t linked to project work. And you can see that and check in on things.

Now an unmatched branch might not be a big deal — maybe it’s just some refactoring or rework of project work — but at least with this statistic, you can see what is going on in your repository and check into it.
Is our work aligned to business priorities?
A development team does a number of different kinds of work: new feature work, bug fixing, refactoring, etc. I always had a hard time figuring out exactly how much time was spent on what type.
Again, that information is there in your repository and your project management tool, but is hard to suss out. Well, computers can do the sussing pretty easily, and so it is quite possible to tell at a glance how your team is dividing up work:

And even cooler? This is up-to-the-minute information. Not lagging — completely current. It’s pulled right from the current status of your existing tools and code. With this information you can make inflight adjustments as necessary, armed with precise information and not guesswork.
Who is overworked?
One of my big frustrations as a Dev Manager was seeing people get burned out. It’s something that is hard to track and you usually find out too late to do anything about it. It is especially challenging in a remote work environment.
But yet again, that information is available and hard to retrieve. Measuring things like number of projects a dev is working on, how many branches she is working in, or how many consecutive days he has committed code all can be great indicators of overwork. The view below can point you in the right direction and help you see people that may be working too much.

Here, you can see right away that Jacob has too much on his plate (Work in Progress), and has worked for the last 16 days straight. Not good, and you could recognize a problem well before it gets this bad. Just as you can’t run a car’s RPM’s in the red for long periods of time, so you can’t have developers working “in the red” for long stretches. Being able to see it before it happens will help you head such things off at the pass.
Are my developers context switching?
Context switching sucks all around. Breaking concentration is frustrating. It takes time to go from one setup to a different one. I always worked hard to make sure that my team is working on — and finishing — one thing at a time.
But it’s hard to know, right? You can’t monitor people 24/7, especially in this new remote world. And sometimes developers might not even realize that they are jumping around from thing to thing — they are just trying to be helpful.
Do I need to say it? The information is there and only needs to be mined.

Here, you can see a developer’s commit pattern indicates that they’ve been context switching — checking in code from different work tickets over a period of time. Maybe they have competing priorities. Maybe the Product Manager is pulling them in multiple directions. You can’t tell from the graph why, but you sure can see that it’s happening, and so you can do something about it.
Are our pull requests useful?
Pull Requests are great. They let your team have control over what goes into git. They let people comment about what and why things were done a certain way. They can serve as permanent documentation about a chunk of code that can be useful down the road. They can help the whole team understand what is going on in the code base.
I used Pull Requests for all the above reasons. But tracking them and making sure they were moving properly through the system was not always straightforward. I wanted to be sure that Pull Requests weren’t too big, that they were reviewed promptly, and that there was adequate discussion about the code. Again — hard to track, see, and gain insight about.
But of course, as always, the information is available. Above you can track the quality of your Pull Requests and how they are moving along.
Join us in our Discord Community where every weekday we discuss a topic of interest in the arena of software development leadership.
What areas in my code base are problematic?
Some code flows off the fingertips and doesn’t need to be changed all that much. But, as we all know, some code doesn’t. Sometimes a developer is struggling to get things right. Sometimes code is buggy and gets worked over pretty hard. And often, you don’t hear about it until things are well along and convoluted.
As a Dev Manager, I would have liked to have some insight into what a developer was doing and how they were getting along with a given project and branch.
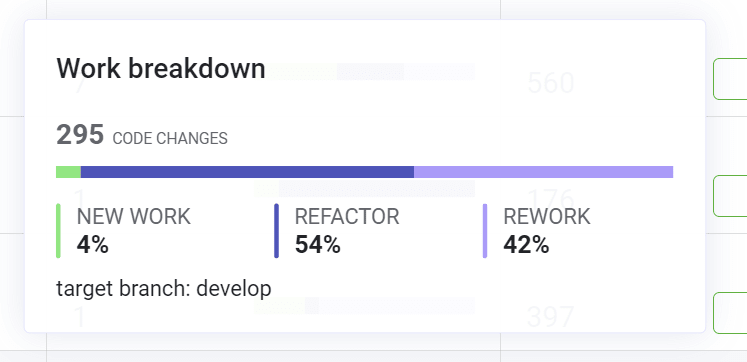
For instance, here’s a branch that is really working hard. In other words, this branch is very little new work and mostly refactoring and reworking. (“Rework” is really just refactoring code that is within the sprint or some other predefined length of time). 295 code changes is probably a lot. So basically this sub-task might be considered at risk. And that’s good to know — definitely worth investigating.
What is really going on in our sprint?
I’ve always done Scrum as a development methodology. We would break our work up into sprints. We would have standups to track progress, But the notion of progress can be difficult to track. It can also be very objective. We didn’t want to have to track down manually the status of every task and sub-task in git or from the team themselves.

Instead I would have loved to have the view above for all the tasks in my sprint. Here I can see at a glance a given task, who is working on it, how much effort has been expended, and how all the associated branches are. Such a view for each branch in use in the sprint would prove invaluable.
Eyes opened
We are very data driven at LinearB — we drink our own champagne, using our own tool to answer those questions that I previously couldn’t answer. No more stumbling in the dark when your boss asks you a question about the status of a project.
The data is available and we reveal it. All those screenshots above are from our product — they provide all sorts of critical information and insights into what our development teams are doing. You can sign up for a free LinearB account today and start seeing insights into your team that will answer your questions and help your team continuously improve.
My eyes were opened. Having all this data certainly would have made my job as a software development manager a whole lot easier.

Top comments (0)