VMware introduced RESTful APIs with their vSphere 7.0 release train; migrating from the old MOB APIs is a welcome choice. REST clients provide a powerful tool for automating processes, but it's important to embody reliable practices when interacting with infrastructure.
The neat thing about published and documented REST APIs is that you're no longer restricted to a specific toolset to automate - both a blessing and a curse.
In the following section, I describe how I prefer to develop reliable infrastructure automation with integrated checking. The code is here, and the guide on how to use it is here.
How Much Automation?
The industry often provides persuasive guidance on the fact that automation should be a conscious choice at work (usually to sell automation products). The title of this blog article is also indicative of this trend - imagine the difference in Google Search hits for "How much automation is good for me and my company". This "peer pressure" alienates people who haven't researched much on automation before they can resolve any subconscious issues present.
The issues I hear are typically from infrastructure engineers, and the concerns raised with automation are common and valid. That doesn't mean we're all off the hook, though - the issues raised are all solvable :
- How Safe: Automation safety is a huge concern - and rightly so. Taking the wrong action rapidly produces disastrous results. This is the highest priority when developing an automation practice, so peer review fundamentals and executing proofs are so important.
- Which Things: Discussions like "This highly custom and variable process can't be automated" indicate that a company's IT Architecture doesn't fit well with automation approaches - prioritizing repetitive solutions on automatable infrastructure should buy companies time to redesign themselves. This is particularly true in networking, where automation models and tools may require hardware upgrades to implement. Infrastructure has always moved slowly , but we stand to benefit from a redesign incorporating everything we've learned since the last time around (~2014 for most).
-
How Much: Do you think you'd know the difference between a company with one engineer coding it all with Python , a company that broadly uses Chef/Puppet/Ansible, or one that uses commercial automation tools exclusively?
- Going "hard mode" may be the right choice, or it might not - it's a better choice to make IT work fluidly with the business.
- A company that typically accepts tools as-is and doesn't modify them much (commercial farming, manufacturing as examples) would benefit more from vendor-provided automation
- A startup trying to rush an initial product to market is going to "code it all".
- Most of us live somewhere in the middle.
Automation Requirements
%20-%20Visual%20Studio%20Code.png)
Let's assume that the agreement is set appropriately. I frame this as a critical ability for my home lab - creating disposable virtual machines to avoid suffering consequences for my mistakes. We start by constructing a plan or requirements for our code:
-
Deploy a vSphere Virtual Machine
- Without OVFtool. OVFTool deployments are slow, even if originated from tools like vRealize Orchestrator within the data center
- Leverage host-storage copying optimization if available (vSAN, NFS Server-Side Copy, VAAI, etc)
- Build a VM from a central image repository
- If the VM isn't possible to build, perform best-effort checking prior to deployment
- Validate that the VM is successfully deployed
- Return a pointer to enforce further customization
The final requirements may be present in a canned solution, but we quickly find that companies with multiple unlinked vCenters/clusters find unique challenges propagating a VM template to each compute resource in their administrative domain. VMware's Content Library feature enables enterprises to create a "build stack" that production clusters can subscribe to (and sync) for standardized images. The Publish Once, Sync Everywhere approach simplifies administration, in part because more complex automation doesn't need to be developed to perform these tasks.
Note: The approach of publishing a VM template requires a specific type of template to automatically populate in vSphere. Clicking " Clone as Template to Library" completes this conversion in one step:

Note: This post assumes that a usable template is already available for use in a content library.
Reviewing Canned Offerings
Always explore the easy path before the difficult one. In this case, Ansible and VMware's REST modules do not yet support template deployments - nearly everything after the deployment is covered.
When compared to Ansible or other idempotent commercial automation tools, self-authored API code has some heavy lifting to do.
- Ensure it's safe to "do": This is difficult for a developer; it requires a level of infrastructure understanding not normally present.
- Implement the "do" thing: With RESTful APIs, this part isn't particularly difficult. Implicitly trusting an endpoint's API reduces most code to "send this document to this IP", resulting in small code bases and little development effort (a handful of PowerCLI or Python lines)
- Ensure the "do" was executed correctly: It's notably straightforward to verify with a REST call after the fact, once the correct checks are
Developing the Code
If it's useful to self-develop code, we need to keep a few things in mind. Anyone with formal software development experience will be familiar with this routine.
Begin by developing an outline/pseudocode: Getting a team to agree on the "what" with actual code may be feasible for experienced developers, but the rest of us could use a little help. Flow diagrams are well supported with Visio/Omnigraffle/Draw.io/Inkscape. Coding with a software diagram is like having a map to guide you while writing code. The C4 Model helps by defining personas and interaction types with a common framework:
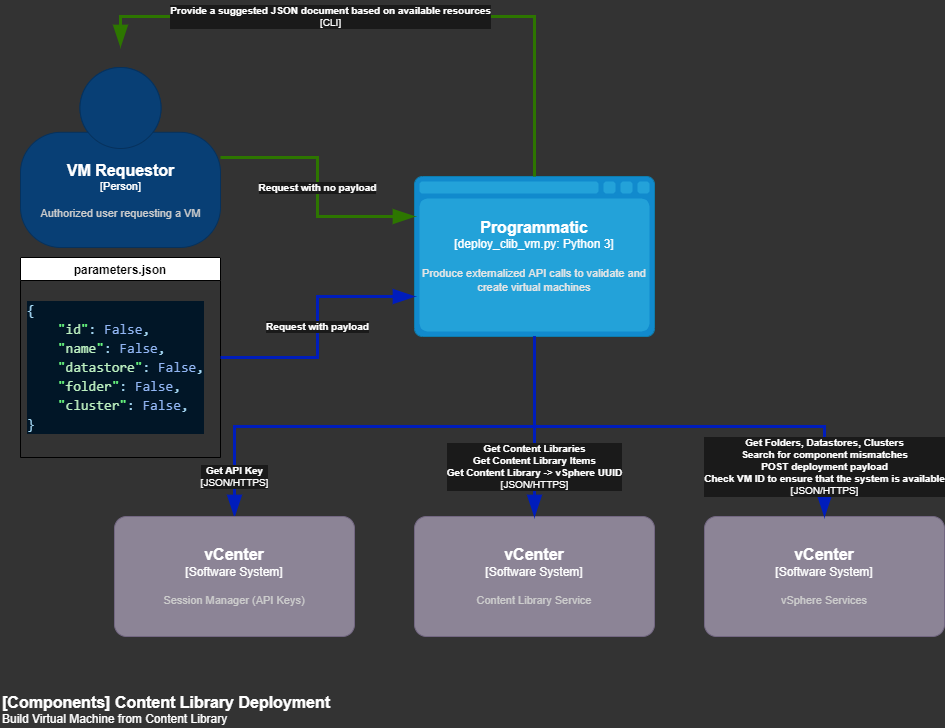
Develop the tests before the actions. Data structures and formatting magically lose their ability to change after users start consuming automation, and testing will improve the diagrams and data structures before the code is actually usable.
Develop the user interactions, documentation, and formatting after the tests. This would include any use of argparse, json.loads/dumps, or environment variables. Users and their inputs should be on the diagram created and relatively easy to code. CI/CD tooling should also come into play here.
Develop the action code. This should be a single-digit percentage of the overall effort!
The Python code to deploy from a content library is here.
Maintaining the code
Most of the effort to automate exists in maintaining code , not creating it. It takes considerably more skill to improve on yesterday's effort and to perform routine work like:
- Steering/Directional choices for the code
- Documentation
- Logging any reported issues
- Prioritizing issues
- Allocating resources to develop solutions to functional issues
- Allocating resources to any problems that may occur operationally
Making responsibilities clear is a critical part of any automation solution - a common approach is to establish a RACI chart or to formally elect a maintainer to decide product direction more centrally in community projects.
In short, if you're in the maintenance phase, Congratulations, you made it! 99% of the work is ahead of you!
TL;DR, Let's use the code!
Now that we covered the development practice, let's cover how to use this code with Jenkins!
We create a new "Freestyle Project", and set input parameters:

Configure Git Hooks (but not "Poll SCM", because this work is to be performed on-demand):

Configure Credential Injection (vCenter Credentials):

Finally, command execution:

This will create a new button - Build with Parameters:

Executing with a properly formatted, short JSON file then results in a new VM build. The tool also supports simple CLI invocation, and will suggest resources for each field (except name, which is up to the user:
Fetching vSphere Details...Payload:{ "id": { "description": "The Content Library object to clone", "suggestions": { "05886bd8-7389-49e1-a53f-29353cd70186": { "name": "debian11-base", "guest_OS": "DEBIAN_11_64" }, "ac6d7f50-0f50-4a1d-b9b5-0e6326f95bb2": { "name": "suse15.4-base", "guest_OS": "SLES_15_64" }, "a26bb731-3ef6-4045-bf7f-3c0514fa343f": { "name": "ubuntu-22.04-base", "guest_OS": "UBUNTU_64" } } }, "name": "Example", "datastore": { "description": "The vSphere datastore to put virtual disks on", "suggestions": { "datastore-1023": { "name": "datastore1" } } }, "folder": { "description": "The vCenter folder to place the VM into", "suggestions": { "group-v1002": "vm", "group-v1095": "Infrastructure", "group-v1096": "Services", "group-v1097": "NSX", "group-v1098": "Management Plane", "group-v1099": "Edges", "group-v1100": "Experiments", "group-v1101": "Templates", "group-v1102": "Monitoring", "group-v1103": "Routing", "group-v1104": "CI-CD Pipeline", "group-v2001": "vCLS", "group-v26010": "Security", } }, "cluster": { "description": "The vSphere compute cluster to put the VM into", "suggestions": { "domain-c1008": "cluster01" } }}Operation Complete!
As a footnote, I created this "suggestions" tool in multiple projects at this point - my major issue with most DevOps toolsets is that they don't effectively document ingress/egress schemas , leaving a user of their code "stuck" if they didn't write it. Even when using a tool like Ansible, I would probably create accompanying tools to "discover" or "suggest" inputs to help the user along.

Oldest comments (0)