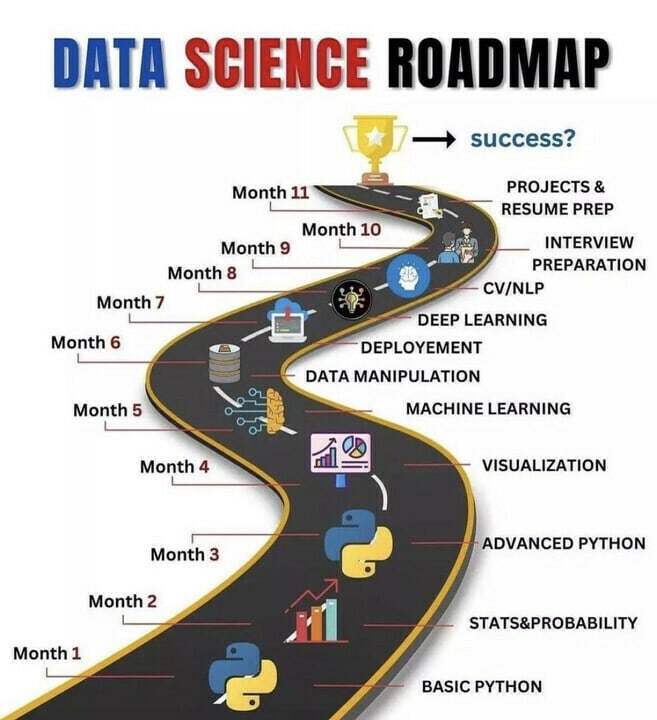
According to Havard Bussiness Review, Data Science is the Sexiest Job in the 21st century (Patil, 2012). Data Science has emerged as a transformative field that empowers individuals to extract valuable insights from data, driving informed decision-making across various industries. Embarking on a journey to become a data scientist can be both exciting and overwhelming, given the vast array of skills and knowledge required to excel in this field. As a beginner, this comprehensive data scientist roadmap gives the essential concepts, tools, and techniques that are necessary to achieve mastery in data science.
What is Data Science?

Let start first by looking at what Data Science is. Data Science has different meanings based on different people. At core, Data Science is using data to answer questions. Data scientists are responsible for collecting, cleaning, and analyzing large datasets to extract valuable insights and make data-driven decisions. They use various machine learning and statistical techniques to build predictive models and solve complex problems.
Data scientists often work closely with business stakeholders to identify opportunities for leveraging data to drive business growth.
According to IBM, data science combines math and statistics, specialized programming, advanced analytics, artificial intelligence (AI), and machine learning with specific subject matter expertise to uncover actionable insights hidden in an organization’s data. These insights can be used to guide decision making and strategic planning (IBM, 2022).
Basically, Data Science involves:
Statistics, Probability, and Mathematics
Data Preprocessing
Data Visualization
Machine Learning
Artificial Intelligence
Understanding the Basics
Before delving into the complexities of Data Science, it's crucial to grasp the foundational concepts. You can Start with understanding what data is and the types of data (structured, unstructured, and semi-structured). Learn the basic statistical concepts, probability, and algebra, as these form the backbone of many Data Science algorithms.
Learning Programming Languages
Proficiency in programming languages is a cornerstone of Data Science. Python and R are two widely used languages in the field. Learn the basics of these languages, including data types, loops, and conditional statements.
Python
Python is a widely used open-source programming language. Python is extensively used in scientific and research groups because it is simple and has simple syntax. It is also more suited for rapid prototyping. Python has a huge set of libraries (Crist, 2016). The most important Python libraries for data science are NumPy, Pandas, Matplotlib, and Scikit-learn.
NumPy: The NumPy library simplifies various mathematical and statistical operations. It also serves as the foundation for many aspects of the Pandas library.
Pandas: The Pandas package is designed specifically to make dealing with data easier. It is developed on top of NumPy, which supports multidimensional arrays.
Matplotlib: Matplotlib is a visualization library that allows you to quickly and easily create charts from your data.
Scikit-learn: Scikit-learn is a well-known and powerful machine learning package that includes a large number of algorithms as well as tools for ML visualizations, pre-processing, model fitting, selection, and evaluation. It includes a variety of efficient algorithms for classification, regression, and clustering. Support vector machines, gradient boosting, k-means, and other algorithms fall under this category.
R
R is another powerful language, just like Python. It is a commonly used open-source programming language for data science. For classification, clustering, statistical testing, and linear and nonlinear modeling, R includes a wide range of statistical and graphical tools. The top R libraries are as follows:
dplyr: The dplyr package is used for data wrangling and data analysis. This package is used to perform various tasks with the R’s dataframe. The five functions Select, Filter, Arrange, Mutate, and Summarize form the foundation of the dplyr package.
Tidyr: The tidyr package is used for cleaning or tidying up data.
ggplot2: R is well known for its ggplot2 visualization package. It offers an interesting collection of interactive graphics.
Exploratory Data Analysis, Visualization and Data Preprocessing
Data Science is about deriving meaningful insights from data. Thus, it is crucial to learn tools like Pandas and NumPy in Python for data manipulation and analysis. After learning the basic data manipulation, you can explore the further through data visualization using libraries like Matplotlib and Seaborn to communicate insights effectively, In R language you can use ggplot. Then equip yourself with the necessary skills to clean your data, and extract new features, to help in the modelling stage. Data preprocessing is crucial in the modelling stage, to ensure an effective machine learning, and as always, garbage in garbage out. You need to train your model using clean data.
Diving into Machine Learning
Machine Learning is a critical component of Data Science, enabling computers to learn patterns from data. Start with supervised learning algorithms (linear regression, decision trees) and progress to unsupervised learning (clustering, dimensionality reduction). Scikit-learn and TensorFlow are valuable libraries to explore. This stage helps you to predict values based on the patterns that are in the dataset.
Understanding Big Data Technologies
With the exponential growth of data, understanding Big Data technologies is essential. Familiarize yourself with tools like Hadoop and Spark for processing large datasets efficiently.
Diving Deeper into Specialized Areas
Data Science encompasses various specialized areas such as Natural Language Processing (NLP), computer vision, and deep learning. Choose a domain that aligns with your interests and delve deeper into its intricacies.
Creating a Portfolio
Create a portfolio showcasing your Data Science projects. This not only serves as a testament to your skills but also provides a tangible representation of your learning journey. Host your projects on platforms like GitHub, or a portfolio website for visibility.
Conclusion
Embarking on a journey in Data Science requires dedication, curiosity, and a strategic approach. By having a clear goal, as a beginner you can build a solid foundation, progressively advancing your skills and contributing meaningfully to the dynamic and ever-evolving field of Data Science. Remember, the key lies in continuous learning and practical application.
References
Crist, J. (2016). DASK & Numba: Simple libraries for optimizing scientific Python code. 2016 IEEE International Conference on Big Data (Big Data). https://doi.org/10.1109/bigdata.2016.7840867
Thomas H. Davenport and DJ Patil. (2012, October 1). Data scientist: The sexiest job of the 21st century. Harvard Business Review. https://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century
What is data science? (2022). IBM. https://www.ibm.com/topics/data-science

Top comments (0)