
Over the past few years, I have been interviewing hundreds of software developers for various positions in tech companies. One question that tends to come up rather frequently is how you pick which package you should depend on. Given that NPM alone currently has around 1 400 000 public packages, chances are that whatever your problem, there are multiple packages that all claim to solve it - leaving you to figure out the best way forward.
Let's dive into how seemingly most people claim to choose packages, then I will share my alternatives and why any of this matters at all.
Github ⭐️ stars and other vanity metrics
Taking the expression "100 Billion Flies Can't Be Wrong" to heart, by far the most common answer I've gotten is that they simply look at the number of stars the repository has on Github.

Stars, for those who are unaware, is the version control platform equivalent of a Facebook "like". Clicking the ⭐️ Star button on a repository adds it to your list of starred repository and potentially shares that activity with your followers.
The theory goes that if other people have deemed this package worthy of a star, it must be good enough for you as well. The benefit of this approach is naturally that it takes very little effort to simply compare a few numbers and pick the highest.
There are of course other similar metrics that people use. Npm Trends primarily uses number of downloads to compare package popularity over time.
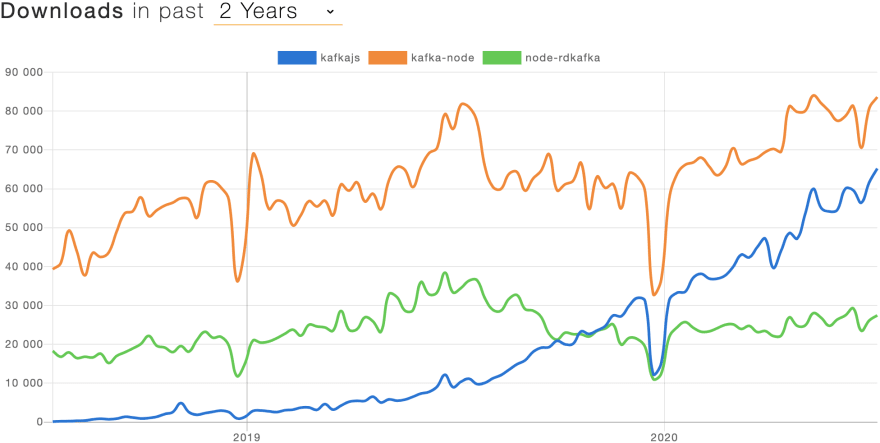
The downside is that these numbers really says nothing about the quality of this package, whether it is still actively maintained (who goes back and removes stars?) or if it has bugs and edge cases that might not affect the majority but could affect you.
In short, these types of metrics aim to measure the popularity of a package.
Blogs, articles and tweets 🐦
Another common criteria that I have heard is to look on Twitter or to read blogs to see what other people are recommending.
This is again a form of external validation of a package's popularity, but this time rather than relying on the wisdom of the crowd, we are choosing to rely on "expert opinion".
At a surface level, this may perhaps sound fine. We expect that these experts on the internet have done a proper evaluation so that we don't have to. I do the same when choosing which barbecue to buy - I don't try out every one of them, I look at reviews.
The issue here is that as evidenced by this very article, anyone can put their opinion on the internet - there's no peer review to ensure that my methodology was sound or that I don't have a vested interest in any particular product.
However, even when an endorsement is done in good faith and a thorough evaluation was done and the facts properly presented, that person simply does not know the context of your project. Just because something was a good fit for them, that doesn't necessarily mean that it's a good fit for you.
Activity metrics - the BPM of the maintainer
The MBAs of the development world shun popularity metrics like downloads and stars, and instead looks at "activity metrics", such as number of pull requests and issues, number of commits over time, number of releases and such.
At the time of writing, Openbase.io was just released to the public, which aims to use these metrics to compare how well-maintained different packages are. For example, it can tell you that redis (the NodeJS client) has on average 1 commit every 6 days, that the average PR takes 20 days to close and that the average issue stays open for 8 hours.
These types of metrics all serve to measure activity. No one wants to deal with a project where the maintainers are impossible to reach or where bugs stay open for years.
However, without context, these metrics are not terribly informative.
- Some packages are simply done and need no further activity. Simple packages that perform their task well and don't need to be kept up to date with moving targets very rarely need any maintenance - so why would a lack of commits be a negative?
- Depending on the target audience of your package, the issues you receive will be of varying quality. Even the most dedicated maintainer will struggle to close issues that require extended back-and-forths with unresponsive reporters that don't provide repro cases or failing tests.
- A simple way for a package author to improve their metrics is to simply close issues as "wontfix" as soon as possible. Or to integrate services like Dependabot, which keeps your dependencies up to date by creating pull requests that are very easily merged.
- Constant change isn't necessarily a good thing. For complex projects, landing a significant change may require careful thought and discussion over many months. Rushing to release something that's not quite thought through may just introduce bugs or churn as public APIs change.
As an open-source maintainer, this sort of evaluation criteria, while not without its merits, also has a tinge of entitlement. The vast majority of small (and not so small) open source projects are maintained without compensation by a single author. Expecting that person to be on call and to resolve every issue promptly is an awful attitude that is shockingly common. Later we will come back to what approach we can take to mitigate this risk in a responsible way.
Determining quality with this one weird trick...
All of the criteria we have looked at above -popularity and activity- have all been about looking at abstractions or high-level metrics to indicate something else - quality.
Determining quality requires you to do something that seemingly very few people actually resort to doing - reading code.
Depending on the size and complexity of the project, as well as your familiarity with the subject, you may or may not be able to judge the technical merit of every single piece of software that you interact with. For example, I may be able to make use of Tensorflow to detect faces in an image, but I couldn't without some serious time investment compare the quality of Tensorflow to other competing solutions.
However, I think people overestimate how complex most software really is. I bet your average developer could come to an informed decision on the quality of for example express or pg in just a few hours if they weren't so reluctant to even try.
Seriously, this is my secret. Try it next time. Actually sit down and read through the code and understand at least at a high level what it's doing and why. If you don't understand why it's doing something, read up on the subject until you get a decent understanding. Pretty soon you will notice similarities and differences between projects, understand what tradeoffs they made and how easy it will be to evolve the project.
Be aware, however, that you are looking at a snapshot, not necessarily trajectory. When I first read through pg I saw that the protocol code was intermingled within all the other code, and thought that this would make it really hard for the project to evolve. If there was a competing postgres driver at the time, I would at least have had a serious look at that as an alternative. However, nowadays the protocol has been refactored and separated out into a separate package and the remaining codebase looks a lot better. If I had relied only on the quality metric at the time, I would most likely have made a poor choice.
Picking a dependency, the hard way
When you choose to take on a new dependency in a project, you are marrying that dependency until death do you part, or you go through a messy and expensive divorce. If the dependency is central enough to your project (ORM, server or DI framework), replacing it may be almost equivalent to a full rewrite. Especially if the project has not been very well structured to isolate different layers, as is often the case. Therefore, it makes sense to invest time in understanding your dependencies and learning about them before it's too late.
- Does the dependency have a sustainable development model (sponsorships, part-/full-time developer, commercial value added services or components)?
- Do I feel confident that if the maintainer stops maintaining the dependency, I could maintain it myself?
- Does an entity with resources have a vested interest in the future of the dependency, and could I or my company be that entity?
- Does my use-case fit with the goals of the dependency?
- If there are significant bugs that affect me, do I feel confident that I could fix them myself?
The above points are primarily concerned with sustainability. As we saw from the pg example, a project being sustainable and having a positive trajectory is more important in the long run than quality at any particular snapshot in time. Or in the words of John Ousterhout:
A little bit of slope makes up for a lot of y-intercept
Promoting sustainability
Sustainable projects don't happen without either corporate or community support. If a project provides value for you or your company, and you want that project to continue to be supported, you have to contribute with your support.
- Contribute to open-source projects on OpenCollective
- Become a Github Sponsor of projects you depend on (shill alert: Sponsor my work on KafkaJS)
You can also contribute your time by providing issue triage and pull requests to address bugs, however, be aware that code contributions also take the maintainer's time, not just when reviewing your contribution, but also because they have to continue to maintain your code for the lifetime of the project. Contributing financially to allow the maintainers to spend more of their time on the project is in many cases more impactful for the long-term health of the project.
How about no dependency?
So far we have learned that tying the fate of your project to a dependency is risky business, and mitigating that risk by careful evaluation not just of popularity and activity, but also of quality and sustainability, can be a lot of work. And even when you do put in the work, there is always the risk that you make the wrong choice anyway.
With this in mind, I propose that we shift our mindset from "which dependencies should I choose" to "should I use a dependency".
One of the core design choices we made when building KafkaJS was that we would have little to no runtime dependencies. We chose that because we knew that KafkaJS would be a core part of our users' applications, and as such any dependency that we take on, our users would also have to take on as a transitive dependency. We also knew that these applications would live for quite a long time and power important business processes, so if we chose to take on a dependency that would no longer be maintained, it would be up to us to make sure that our users would not be exposed to new security issues.
As such, we adopted our "no dependencies" approach - with one small exception, long.js. That exception we chose to allow for because the scope of the dependency was small, we knew that native 64-bit integers for NodeJS was on the horizon, at which point we could get rid of it, and we were confident that we could maintain the library or our own fork ourselves if need be.
Shifting the mindset from "which dependency should I choose" to "should I use a dependency" meant that we don't need to worry about any of the issues listed above. The downside is of course that we have to maintain more code ourselves - but a lot of the time the code that we actually need is so much less than what dependencies provide. Since we know the context of our project, we can implement just the bit that we need, not cater for the needs of the many.
Conclusion
In short, taking on a dependency has a bigger impact than most people tend to consider. If you are working on a long-term project with actual consequences in case of failure, this is a responsibility you should take seriously. Evaluate your options carefully and weigh the risk vs reward for each dependency.
And ⭐️s don't matter.
Cover image from Russ Cox's excellent article on the same subject

Top comments (2)
This was my bottom line for deciding to write and maintain my own functional programming library over another library. It's tough to find quality nowadays.
I appreciate your article because it gives such a holistic and realistic take on the state of how we choose quality and what quality really means. At the end of the day, it comes down to the code. In my experience, tests have also helped in determining the quality of a library.
Another benefit of no dependencies - it is really easy to ship your stuff in both browser and common JS node environments. Also less tooling = faster development cycles
How about last updated, and possibly issues to popularity ratio?