
This post will discuss the ideas and considerations behind graph databases such as their use cases, advantages and the trends behind this database model with several real-world case example.
A Social Network Scenario
Considering a social network scenario shown below, User can post, share their tweets or comment on other people or advertisers’ tweets, follow each other. It is essential for a data-driven company to use basic CRUD(Create, Read, Update, Delete) operations to add more people, add new messages to the current database or find associated information, help company to figure out certain user’s User portrait just like Jeff has many posts relating to AI and music thus we may suppose him a programmer etc.

It is some basic types of database operations. Sometimes the requirements for one analysis can be extremely tricky such as Find all direct reports from employees and count the number of reports up to 3 levels down.[1] Such an analytic problem is not purposely designed to create obstructions for data engineers, those things are quite common in current era of distributed computing.
Traditional Ways to Solve the Question Posted Above
Data model schemes and traditional queries
The traditional way to solve the problem is to build a relational data model for every user and store those relations in several tables in a Relational database such as MySQL and so on.
The basic relational schema is shown below.
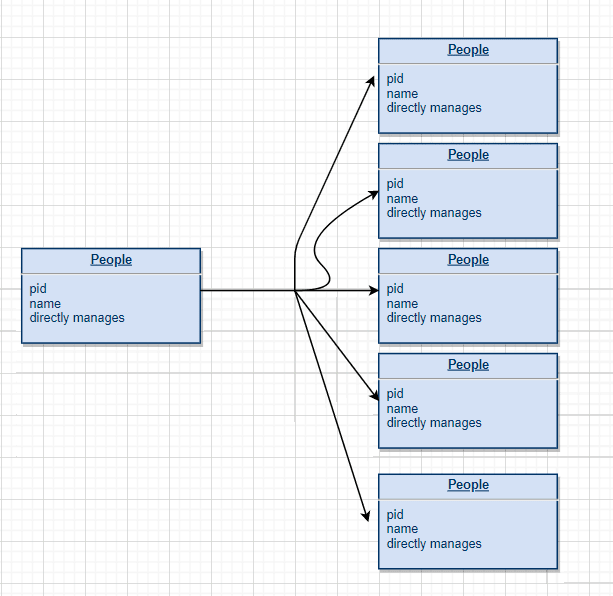
If we want to implement the query as the question listed above, it is inevitable that there will be a huge amount of JOIN and the length of query can be extremely long. [1]
(SELECT T.directReportees AS directReportees, sum(T.count) AS count
FROM (
SELECT manager.pid AS directReportees, 0 AS count
FROM person\_reportee manager
WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName")
UNION
SELECT manager.pid AS directReportees, count(manager.directly\_manages) AS count
FROM person\_reportee manager
WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName")
GROUP BY directReportees
UNION
SELECT manager.pid AS directReportees, count(reportee.directly\_manages) AS count
FROM person\_reportee manager
JOIN person\_reportee reportee
ON manager.directly\_manages = reportee.pid
WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName")
GROUP BY directReportees
UNION
SELECT manager.pid AS directReportees, count(L2Reportees.directly\_manages) AS count
FROM person\_reportee manager
JOIN person\_reportee L1Reportees
ON manager.directly\_manages = L1Reportees.pid
JOIN person\_reportee L2Reportees
ON L1Reportees.directly\_manages = L2Reportees.pid
WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName")
GROUP BY directReportees
) AS T
GROUP BY directReportees)
UNION
(SELECT T.directReportees AS directReportees, sum(T.count) AS count
FROM (
SELECT manager.directly\_manages AS directReportees, 0 AS count
FROM person\_reportee manager
WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName")
UNION
SELECT reportee.pid AS directReportees, count(reportee.directly\_manages) AS count
FROM person\_reportee manager
JOIN person\_reportee reportee
ON manager.directly\_manages = reportee.pid
WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName")
GROUP BY directReportees
UNION
SELECT depth1Reportees.pid AS directReportees,
count(depth2Reportees.directly\_manages) AS count
FROM person\_reportee manager
JOIN person\_reportee L1Reportees
ON manager.directly\_manages = L1Reportees.pid
JOIN person\_reportee L2Reportees
ON L1Reportees.directly\_manages = L2Reportees.pid
WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName")
GROUP BY directReportees
) AS T
GROUP BY directReportees)
UNION
(SELECT T.directReportees AS directReportees, sum(T.count) AS count
FROM(
SELECT reportee.directly\_manages AS directReportees, 0 AS count
FROM person\_reportee manager
JOIN person\_reportee reportee
ON manager.directly\_manages = reportee.pid
WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName")
GROUP BY directReportees
UNION
SELECT L2Reportees.pid AS directReportees, count(L2Reportees.directly\_manages) AS
count
FROM person\_reportee manager
JOIN person\_reportee L1Reportees
ON manager.directly\_manages = L1Reportees.pid
JOIN person\_reportee L2Reportees
ON L1Reportees.directly\_manages = L2Reportees.pid
WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName")
GROUP BY directReportees
) AS T
GROUP BY directReportees)
UNION
(SELECT L2Reportees.directly\_manages AS directReportees, 0 AS count
FROM person\_reportee manager
JOIN person\_reportee L1Reportees
ON manager.directly\_manages = L1Reportees.pid
JOIN person\_reportee L2Reportees
ON L1Reportees.directly\_manages = L2Reportees.pid
WHERE manager.pid = (SELECT id FROM person WHERE name = "fName lName")
)
I think that nobody has the patience to write such a huge amount SQL language for those analytic problems. It will also become a hell for debugging. The more serious problem is performance issues such a huge SQL language could potentially have.
Performance issues in traditional RDBMS
The most essential issue relating to such query comes from the size of the problem we faced in current era which is the scaling issues relating to the nature of huge social network associations.
The relation between users to users, users to items or items to items go exponentially.
Here are some basic facts: Twitter with A following B relationship has 500 millions users, Amazon with A buying B relationship has 120 million Users , AT&T cellphone network has who-call-whom relationship with 100 million users and so on. [2]
The open source graph benchmarking has billions of nodes and edge s listed below with O(TB) or even O(PB) amount of data: [3]

With such a big table challenge normal SQL operation can cause huge penalty on query performances:[4]
- JOIN operations. As we see in the query language above, a huge number of JOIN operations are used to find the exact result we want. However, join-intensive query performance deteriorates as the dataset gets bigger. That is because of the spatial localization in the essence of our data which is only a small proportional under the whole dataset but the JOIN operation intent to traverse through the whole dataset which is unacceptable.
- Reciprocal queries cost much as you thought. Here the cost of subordinate employees ruled by certain manager has few costs, however, if we do query reversely, such as get the manager of certain people which will introduce prohibitively high expense to the reversed one. It may not be an issue for current problem, but if we change the relationship from manager-employee to customer-products, it will make one recommendation system stay in stale.
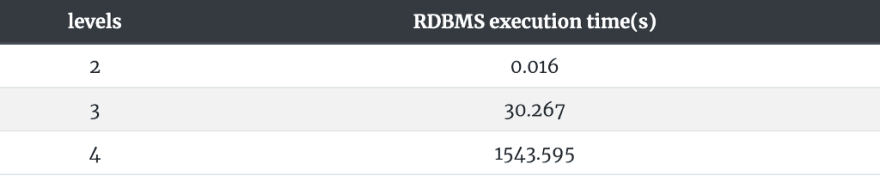
One unofficial benchmarking listed in here as we can see as level go up, the cost of this operation rise exponentially (based on a social network containing 1,000,000 people with approximately 50 friends for each one):[4]
Performance fine-tuning with indexing or caching and why it is not the best practice.
Indexing is to help SQL engine find and acquire data efficiently
Using indexing such as B-tree indexing or hash indexing is one way to solve the performance costs in table join operation, for example, we can create a unique id for every person and B-tree which is a balanced tree will sort all items by their unique id which is perfect for range query and the cost for find curtain item can be limited to O(logN) where N is the number of indexed items.
But indexing is not a panacea for all situations. If items update frequently or have many repeated items, the indexing will attend to perform a huge number of space overhead due to indexing.
Plus, disk IO in a large HDD disk will be critical for JOIN operations, even if one seek operation costs a few milliseconds, and one B-tree indexing just need 4 seek operations to traverse the whole indexing table, but once the JOIN operations become larger, seek operations need to happen hundreds of times.
Caching is designed to use the essence of spatial locality of dataset for read intensive analytic scenario.
It is a widely used architecture named lookaside cache architecture. Here is a simple demo with memcached and MySQL which is used in Facebook before the introducing of graph database: [5]
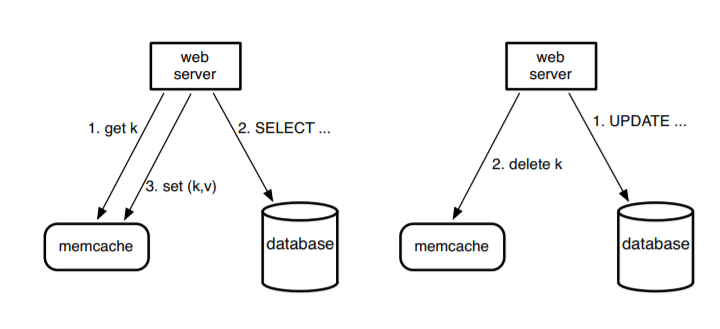
The assumption behind the architecture is that the user consumes much more contents than they create, thus using memcached which serve just like hashtable with CRUD operations can serve as a building block and process billions of requests per second.
The basic workflow is that when a web server needs data, it first request on cache and if it is not cached, it will look for SQL database, and for write requests, client will delete key in memcached which put the data in stale and then update database.[5]
However, such an architecture will introduce several fundamental problems:[6]
Firstly, key-value cache is not a good semantic for graph operations, look-ahead architecture will require the queries fetch the entire edge and changes to a single edge require the entire list to be reloaded because they deleted before, this is the bottleneck for concurrency performance. As in facebook the connected components have thousands of connections in average and such an operation costs a lot of time and memory.
Secondly, visibility of updated data needs inter-regional communication because of the asynchronous master/slave replication for MySQL. The original model uses something called remote markers to track staled keys and asynchronously forward read from those keys to the master region which needs many inter-regional communication.(just like travel from California to New York by walking)
The Key to the Solution is Modeling Data Through Graphs
Lacking relationships is the key failure of other kinds of database modeling [4]
Relational database works well if data is in codify paper forms and tabular structures. However, if we want to model the ad hoc relationships that will crop up in the real world, the RDBMS can handle them poorly.
As we discussed above, the relational data model become burden with a very large of join tables with sparse populated rows where there are billions of different tables across databases. With the growth of dataset and the increased number of JOIN operations which greatly impede the performance of existing RDBMS and exactly not fit current business requirements.
Dealing with recursive queries such as the manager’s subordinates’ report number can perform badly due to the computational and space complexity of recursively joining tables.
Nodes, associations and graph modeling
As we mentioned above, it is true that traditional databases have implicit graph connections between different schemas, but as we analyze the semantic dependencies such as A controls B, A buys B, as the data model defined, we need to check on the data table and are blind to these connections.
If we want to make the connections visible before check on the node, we need to define objects and their connections separately.
The key difference between graph databases and other databases is to represent nodes and paths separately. For example, we can represent people, or manager as separate nodes. Associations capture the users’ friendships, belongings’, authorship of the checkin and comments and the binding between the checkin and its location and comments.
We can add new nodes and new associations in a flexible way without compromising the existing network or migrating data (original data remains stateless.)
Based on this modeling technique, we can model the original social network problem in this way:

Here we can construct nodes and their corresponding paths separately and build path as association in an obvious way.
Building the graph model in nGQL (graph query language developed by Nebula Graph) can be followed as here:
-- Insert People
INSERT VERTEX person(ID, name) VALUES 1:(2020031601, ‘Jeff’);
INSERT VERTEX person(ID, name) VALUES 2:(2020031602, ‘A’);
INSERT VERTEX person(ID, name) VALUES 3:(2020031603, ‘B’);
INSERT VERTEX person(ID, name) VALUES 4:(2020031604, ‘C’);
-- Insert edge
INSERT EDGE manage (level\_s, level\_end) VALUES 1 -> 2: ('0', '1')
INSERT EDGE manage (level\_s, level\_end) VALUES 1 -> 3: ('0', '1')
INSERT EDGE manage (level\_s, level\_end) VALUES 1 -> 4: ('0', '1')
And the query which we previously implemented with the extremely long SQL can be rewritten in an elegant way using Cypher or nGQL.
Here is the simple nGQL version:
GO FROM 1 OVER manage YIELD manage.level\_s as start\_level, manage.\_dst AS personid
| GO FROM $personid OVER manage where manage.level\_s < start\_level + 3
YIELD SUM($$.person.id) AS TOTAL, $$.person.name AS list
And the Cypher version is in here: [1]
MATCH (boss)-[:MANAGES\*0..3]->(sub),
(sub)-[:MANAGES\*1..3]->(personid)
WHERE boss.name = “Jeff”
RETURN sub.name AS list, count(personid) AS Total
GQL greatly reduced the query length which is essential for performance and debugging. For a comparison among Cypher, Gremlin and nGQL, refer to this post.
Why Graph Databases Have Better Performance
Graph databases have designed special optimizations for highly connected, unstructured data. Different kinds of graph databases have different implementations targeting for different scenarios.
Here we will introduce several different kinds of graph databases, all of them natively support graph modeling.
Neo4j [4]
Neo4j is one of the best known graph database, and widely adopted in industry such as in eBay, Microsoft and so on.
Native graph processing
A graph database has native processing capabilities if it exhibits a property called index-free adjacency. A database engine that utilizes index-free adjacency is one in which each node maintains direct reference to its adjacent nodes and each node will therefore act as a micro-index for other nearby nodes, which is much cheaper than using global indexes. It means that query times are independent of the total size of the graph, and are instead simply proportional to the amount of the graph searched.
In simple word, index-lookups could be O(logN) in algorithmic complexity versus O(1) for lookup immediately from key-value relationship and traverse m steps.
If we use index approach, it costs O(mlogn) which only costs O(m) with index-free adjacency solution.
As we discussed above, relational databases perform poorly when we move away from modestly sized JOIN operations which is mainly resulted from the number of index-lookups involved.
In contrast to relational databases, where join-intensive query performance deteriorates as the dataset gets bigger, with a graph database performance tends to remain relatively constant, even as the dataset grows. This is because queries are localized to a portion of the graph.
In-memory cache
At Neo4j 2.2, it uses an LRU-K page cache. The page cache is an LRU-K page-affined cache, meaning the cache divides each store into discrete regions, and then holds a fixed number of regions per store file.
Pages are evicted from the cache based on a least frequently used (LFU) cache policy, nuanced by page popularity. That is, unpopular pages will be evicted from the cache in preference to popular pages, even if the latter haven’t been touched recently. This policy ensures a statistically optimal use of caching resources.
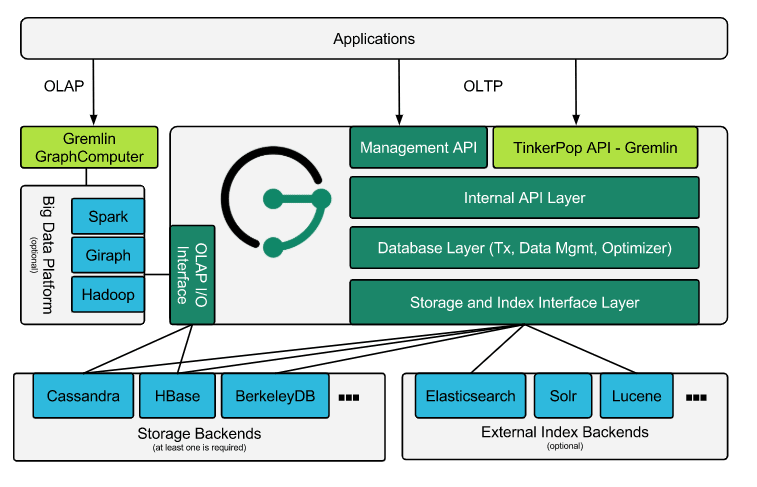
Janus Graph [7]
Janus Graph itself does not focus on storage and analytics functionalities. The main purpose of this frame is to serve as a graph database engine which focuses on compact graph serialization, graph data modeling and efficient query execution.
Supporting robust modular interfaces for data persistence, data indexing and client access is the main purpose of this frame, it can be a preeminent solution for companies that just want to use graph modeling as their architecture solutions.
JanusGraph can use Cassandra, HBase and Berkeley DB as its storage adapter and using Elasticsearch, Solr or lucene for data indexing.
Broadly speaking, applications can interact with JanusGraph in two ways:
- Embed JanusGraph inside the application executing Gremlin queries directly against the graph within the same JVM. Query execution, JanusGraph’s caches, and transaction handling all happen in the same JVM as the application while data retrieval from the storage backend may be local or remote.
- Interact with a local or remote JanusGraph instance by submitting Gremlin queries to the server. JanusGraph natively supports the Gremlin Server component of the Apache TinkerPop stack.
Nebula Graph [8]
Here we listed several bird’s view on the system design of Nebula Graph which is specially optimized for graph modeled data.
Key value store graph processing
Nebula graph adopted vertexID + TagID as key for local storage and store out-key and in-key separately in different location which support O(k) look up and partition ensures high availability in a large distributed cluster.
In contrary to other storage designs, Nebula natively support distributed partition or sharding, which greatly increased the processing speed and fault tolerant capability.
The help migrating data and provide modular level storage engine by using own kv store library, thus it supports storage service for third party kv store such as HBase and so on.
Nebula Graph manages the distributed kv store in a unified scheduling way with meta service. All the partition distribution data and current machine status can be found in the meta service. User can add or remove machines from console and execute balance plan. Plus Multi-cluster Raft group with atomic CAS and read-modify-write operation are fully used by raft serialization which enabled immediate consistency.
Stateless query layer
As in the query layer, nGQL will be pared to Abstract Syntax Tree and be converted to LLVM IR, the IR code can be passed to execution planner for edge-level parallel execution and Just In Time execution.
Complied query will be stored and if user adopted the same query again, it will reuse the cached commands with no need for further parsing.
Graph Database is the Trend and That is Not Just My Opinion
For the current time, graph databases have already attracted many attentions made by analyzers and consulting companies:
Graph analysis is possibly the single most effective competitive differentiator for organizations pursuing data-driven operations and decisions after the design of data capture. — — -Gartner
“Graph analysis is the true killer app for Big Data.” — — — -Forrester
The current trend of graph database is the highest based on db-engine ranking:[9]
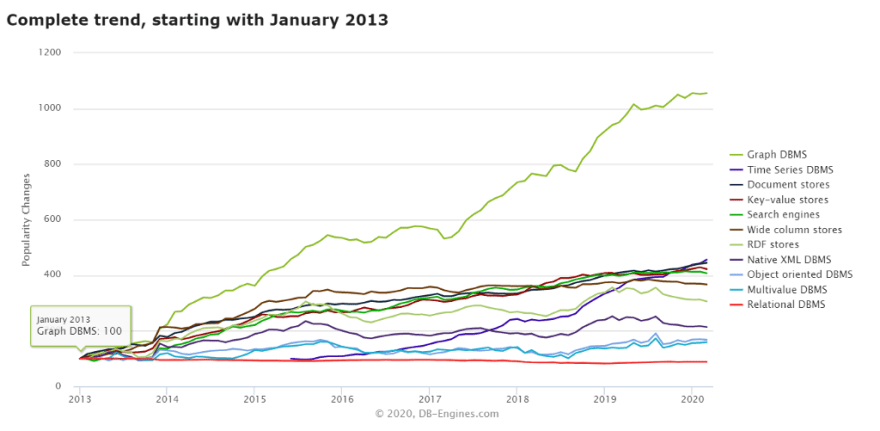
Graph Database with More Than Social Network
Netflix Cloud Database engineering [10]:
Netflix adopted JanusGraph + Cassandra + Elasticsearch as their graph database infrastructure.
The usage of graph database is in digital asset management. Entities such as Assets, Movie, Display Sets and so on are vertex, and all relations are edges.
The current stats is that there are 200 M nodes in PROD cluster, hundred queries and updates per minute, 70 asset types and test clusters with over 200 M nodes.
Plus, they also adopted graph database in authorization, distributed tracing, and visualize the Netflix infra and relations like how code gets committed to stash, built on Jenkins, deployed by spinnaker.
Adobe [11]
There is a prejudice to new coming technologies that such a technology may not suit for large company which may have many legacy systems and it do not make sense to take the risk to change from old stable system to new and unstable new technologies.
Adobe did some transfer from old NoSQL database Cassandra to Neo4j.
The overhauling system’s name is Behance, which is a leading social media platform owned by Adobe and launched in 2005 which have more than 10 million members.
Here people can share their creative works to millions of daily visitors.

Such a large legacy system was built upon Mongodb and Cassandra and due to historical design problems, there are some daunting facts need to be fixed.
Mongo has very slow reads because of data model and Cassadra either because of the fan-outs design policies and large overhead in web infrastructure. Plus, Cassandra needs babysitting by a huge number of ops team. As the original infra shown below, fan-out to feed new project message to followers needs a huge number of writes which will hamper performance tremendously:
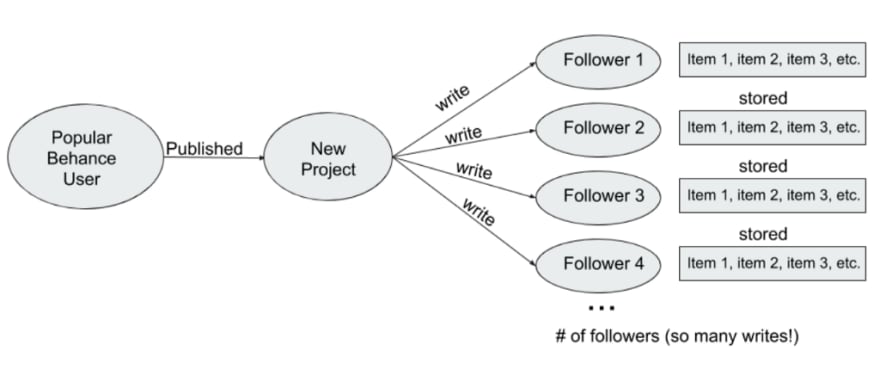
Here in order for flexible, efficient robust system with fast feed loading and minimal data storage, Adobe decided to migrate from original Cassandra database to Graph database Neo4j.
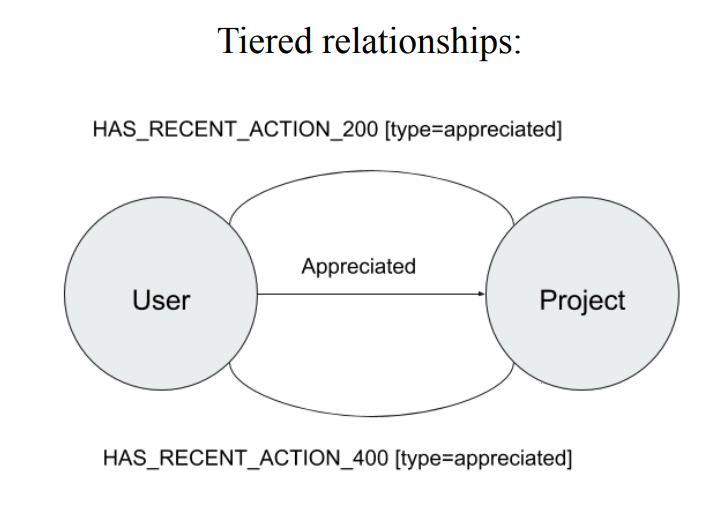
The relationship here, separated one operation such as appreciation to different types of status such as enable to visit or not and so on named Tiered relationships.(btw, those status information supported by Nebula Graph with just one edge.)
Here is the data-model shown below:
By adopting a simple Leader-follower architecture shown below, a huge profit has been acquired:

In specific, by adopting graph database with master-slave architecture for fault tolerance, Adobe team acquired a huge number of performance improvement:[11]
- Human maintenance hours down well over 300% with Neo4j
- 1/1000 storage required — 50GB with Neo4j vs 50TB with Cassandra
- Simple: powered by 3 instances instead of 48
- Easy extensibility thanks to clean graph data model
Conclusion
Graph database have many low hanging fruits for big data era. Using graph databases as a technical solution can promote not only the rise of new coming AI, IoT, 5G applications’ thriving, but also the reformation of old legacy systems.
A graph database may have many different infrastructure implementation but they all support graph modeling which interconnect different components with their associations. As we discussed before, such change in data modeling will be an extremely simple and straightforward solution for many daily system scenario with much faster throughput and lesser DevOps requirement.
References
[1] An Overview Of Neo4j And The Property Graph Model Berkeley, CS294, Nov 2015 https://people.eecs.berkeley.edu/~istoica/classes/cs294/15/notes/21-neo4j.pdf
[2] several original data sources from talk made by Duen Horng (Polo) Chau (Georgia tech) www.selectscience.net、 www.phonedog.com、 www.mediabistro.com、 www.practicalecommerce.com/
[3] Graphs / Networks Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know Duen Horng (Polo) Chau(Georgia tech)
[4] Graph databases, 2nd Edition: New Opportunities for Connected Data
[5] R. Nishtala, H. Fugal, S. Grimm, M. Kwiatkowski, H. Lee, H. C.Li, R. McElroy, M. Paleczny, D. Peek, P. Saab, D. Stafford, T. Tung, and V. Venkataramani. Scaling Memcache at Facebook. In Proceedings of the 10th USENIX conference on Networked Systems Design and Implementation, NSDI, 2013.
[6] Nathan Bronson, Zach Amsden, George Cabrera, Prasad Chakka, Peter Dimov Hui Ding, Jack Ferris, Anthony Giardullo, Sachin Kulkarni, Harry Li, Mark Marchukov Dmitri Petrov, Lovro Puzar, Yee Jiun Song, Venkat Venkataramani TAO: Facebook’s Distributed Data Store for the Social Graph USENIX 2013
[7] Janus Graph Architecture https://docs.janusgraph.org/getting-started/architecture/
[8] Nebula Graph Architecture — A Bird’s View https://nebula-graph.io/en/posts/nebula-graph-architecture-overview/
[9] database engine trending https://db-engines.com/en/ranking_categories
[10] Netflix Content Data Management talk https://www.slideshare.net/RoopaTangirala/polyglot-persistence-netflix-cde-meetup-90955706#86
[11] Harnessing the Power of Neo4j for Overhauling Legacy Systems at Adobe https://neo4j.com/graphconnect-2018/session/overhauling-legacy-systems-adobe
Johhan is currently working at Nebula Graph as Software Engineer Intern, researching and implementing large-scale graph query engine and storage engine components. As a contributor of Nebula Graph database, he aims to contribute openly available learning resources about databases, distributed systems and AI through blogs.
Like what we do? Star us on Github!
Originally published at https://nebula-graph.io on March 31, 2020.

Top comments (0)