
In NebulaGraph, there are some long-running tasks in the background, which are named jobs. Some DBA commands at the storage layer fall into this category. For example, the global compaction operation after importing data is regarded as a job.
Since NebulaGraph Database is a distributed system, jobs are handled by different storage services. We call the sub-job running on a single storage service a task.
Jobs are managed by the Job Manager on the meta service while tasks are managed by the Task Manager on the storage service.
In this post, we will explain how to improve database performance by optimizing the management and schedule of the long-running tasks.
The Problems Task Manager is Trying to Solve
In NebulaGraph, Task Manager is expected to solve the following two problems:
- Modify the transmission from HTTP to RPC (Thrift) In general, users will turn off the firewall for the Thrift port when building clusters because they are already aware that storage services in NebulaGraph communicate with each other under the Thrift protocol. However, they often ignore the HTTP port.
- Enable storaged to schedule tasks. We will discuss it in detail later in the post.
The Overall Workflow of Task Manager
The query engine (graphd) sends a job request to the meta engine (metad) where the Job Manager resides. Then the Job Manager selects the corresponding storage engine (storaged) host based on the job request and then composes a task request accordingly to be sent to the storage engine.
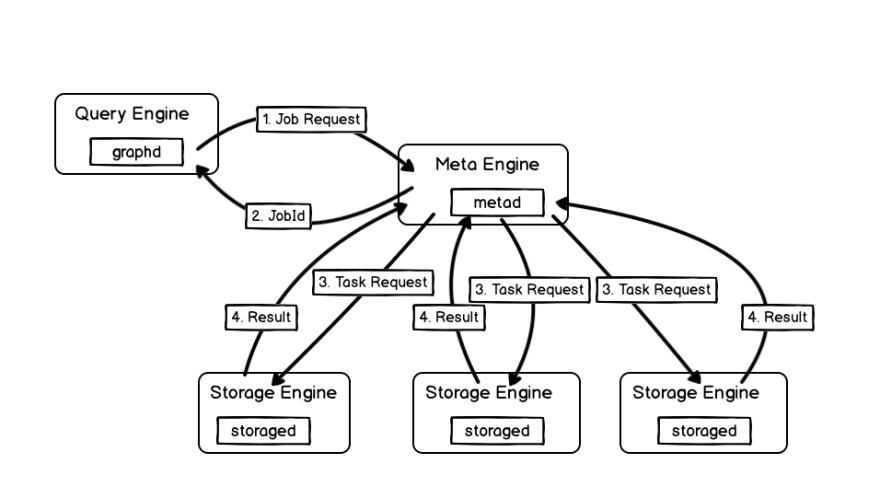
Seen from the chart above, for different jobs, the steps in the meta service such as receiving job requests, composing and sending tasks and receiving responses from the storage engine are the same. However, how to compose a task and which storaged to send them to vary.
The Job Manager allows the future expansions with the template method and simple factory.

We accomplish this simply by making the future jobs inherit from the MetaJobExecutor and implementing the prepare() and execute() methods.
Task Manager Scheduling
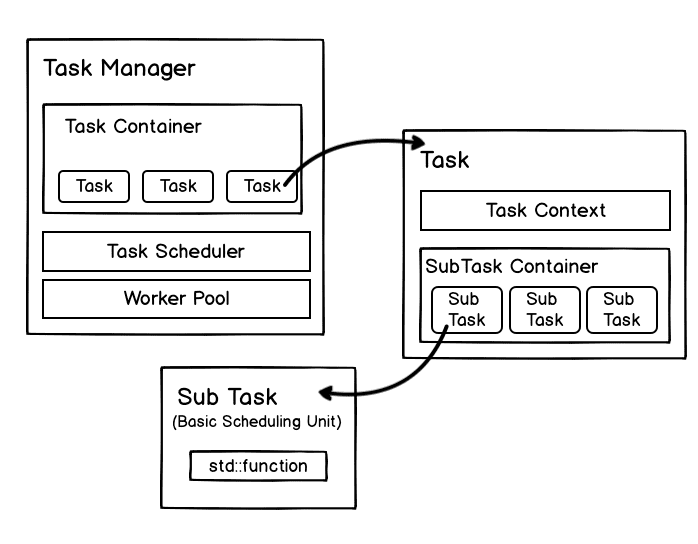
As mentioned above, the goals of Task Manager scheduling are:
- When there is sufficient system resource, execute as many concurrent tasks as possible
- When there is not enough system resource, execute the tasks within a predefined resource threshold
Executing Concurrent Tasks
Task Manager defines the processes it holds as worker.
You can think of the bushiness hall of a bank as a real-life example. The steps you go through when going to the bank:
- Get a number at the Queue Management Machine
- Wait for your turn
- Go to the specified window when it’s your turn
Meanwhile, you may encounter the following problems:
- VIPs jump the queue
- You may have to give up the number for some reason
- The bank closes before it’s your turn
Based on the above scenario, we can extract the essential requirements for the Task Manager design:
- Execute tasks in FIFO order. Different tasks vary in priorities. Tasks with high priorities can jump the queue.
- You can cancel a task in a queue.
- The storage engine may shut down anytime.
- To improve the concurrency as much as possible, a task will be split into multiple sub tasks. It’s the sub task that each worker actually executes.
- Because the Task Manager is the only global instance, you must take multiple-thread security into consideration.
Based on the above requirements, we have come to the following design thinking for the Task Manager:
- Identify a task with the Task Handle (JobId and TaskId in Thrift).
- The Blocking Queue in the Task Manager is responsible for queuing the Task Handles, which is similar to the Queue Management Machine in a bank. The Blocking Queue itself is thread safe.
- Blocking Queue supports scheduling tasks based on priorities, which is similar to VIPs jumping the queue.
- The Task Manager maintains the globally unique Map, with the Task Handle as its key and a specific task as its value (similar to a bank hall). In Nebula Graph, we have introduced a thread safe Map, i.e. the Concurrent Hash Map from folly.
- When a task is cancelled, the Task Manager will locate it in the Map according to the Handle, tagging cancellation to it while doing nothing to the Handles in the queue.
- If a storaged is shut down while there are still running sub tasks, the result will not be returned until all the sub tasks are completed.
Executing Tasks within a Resource Threshold
It is easy to ensure that the threshold is not exceeded because the Worker is a thread. Simply ensure that all the workers come from the same thread pool.
However, how to evenly distribute the sub tasks to the Worker is a bit tricky. Here are some alternative solutions:
Solution One: Add tasks by Round-robin
The simplest way to add tasks following the Round-robin rule. The task is split into sub tasks and added to each Worker one by one.
But there may be some problems here. For example, when there are three Workers, two Tasks (blue for Task 1, yellow for Task 2):

If the sub tasks of Task 2 execute much faster that those of Task 1, the following parallel strategy will be better:
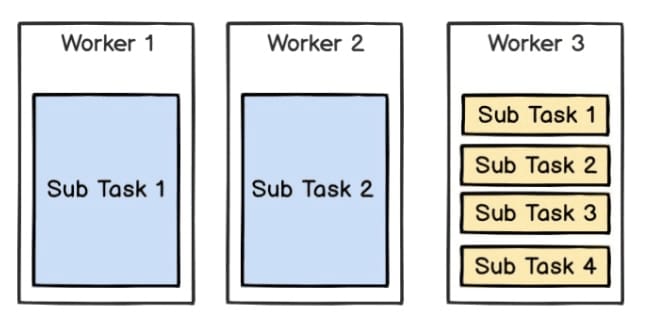
The Round-robin solution makes the execution time of Task 2 dependent on Task 1 (see Fig.1 Round-robin).
Solution Two: Handling One Task With a Group of Workers
To address problems in Solution One, we can set a special Worker to handle certain Tasks, so as to avoid the interdependency among multiple tasks.
But the performance is not good enough. Consider the following example:
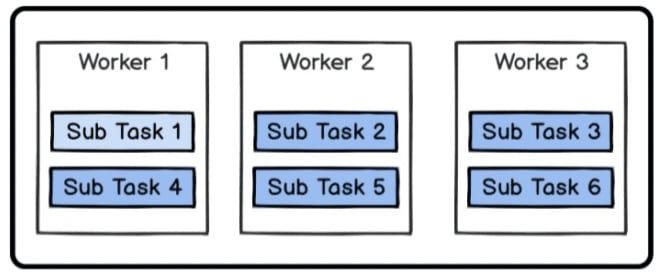
It’s hard to ensure the execution time of each sub task is basically the same. Assuming Sub Task 1 executes significantly slower than other sub tasks, then the following execution strategy will be a good one:
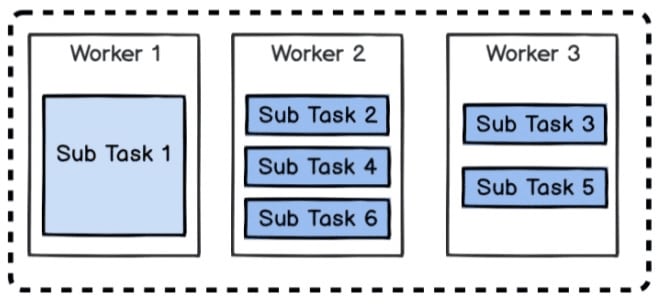
But such strategy can’t avoid the fact that when one core is in trouble, other cores can do nothing, either.
Solution Three: What we have actually introduced in Nebula Graph
In NebulaGraph, Task Manager will pass the Handle of a Task to N Workers. The number N here is determined by the total number of Workers, the total number of sub tasks and the concurrent parameters specified by the DBA when submitting the Job.
Each Task maintains a Blocking Queue (the Sub Task Queue in the following figure) to store the sub tasks. When the Worker is executed, it will first find the Task according to the Handle it holds, then obtain the sub tasks from the Block Queue of the Task.
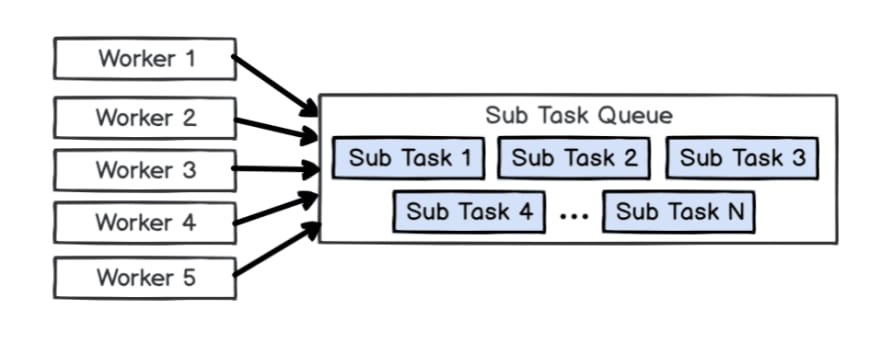
Some Frequently Asked Questions about the Design
Question 1: Why not put the Task directly into the Blocking Queue, but split it to two parts, store it to the Map, and make the Task Handle wait in the queue?
The main reason is that basic C++ multiple threads don’t support such design. Tasks needs to support cancellation. If putting Task in the Blocking Queue, the Blocking Queue must support to locate the tasks. However, there is no such interfaces in the Blocking Queue of the present folly.
Question 2: What kind of jobs enjoy the VIP priority?
The compaction / rebuild index currently supported by the Task Manager is not sensitive to the execution time. But it supports queries like count() in development. Considering that users expect count() is done in a relative short time, when storaged is operating multiple compactions, we hope the count(*) runs first instead of running after all the compactions are finished.
Here comes to the end of Nebula Graph Task Manager introduction. If you encounter any problems in usage, please tell us on our forum or GitHub.
You might also like
- D3-Force Directed Graph Layout Optimization in Nebula Graph Studio
- How Nebula Graph Uses Jepsen to Detect Data Consistency Issues in Raft Implementation
- How Nebula Graph Automatically Cleans Stale Data with TTL
Like what we do ? Star us on GitHub. https://github.com/vesoft-inc/nebula
Originally published at https://nebula-graph.io on May 26, 2020.

Top comments (0)