New Players: Something You Should Know When Reading NebulaGraph Source Code

When I saw the NebulaGraph code repository for the first time, I was so shocked by its huge size that I didn’t know how to dig into the source code. Then I worked up the nerve. After reading the code and running the use cases over and over, I finally gained some experience worth sharing with you, hoping that all my experience could push you to give NebulaGraph source code a shot to know more about the graph DBMS, to improve your graph database knowledge, and to fix some bugs that are not so complicated of this repository.
In this article, I took the SHOW SPACES statement as an example to show you how NebulaGraph processes an nGQL statement after it was input on the client side. GDB, the GNU Project debugger, was used to trace the execution.
Additionally, some open-source libraries are used in NebulaGraph. For more information, see the Libraries section.
Architecture of NebulaGraph
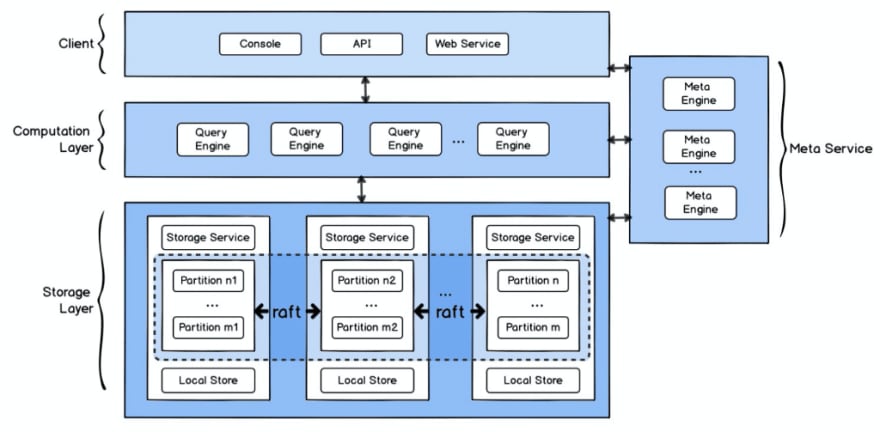
A complete NebulaGraph DBMS contains three services: Query Service, Storage Service, and Meta Service. Each service has its own executable binary files.
Query Service is responsible for these tasks:
- Managing connection to the client
- Parsing an nGQL statement input from a client into an AST (Abstract Syntax Tree) and then parsing the AST to an execution plan
- Optimizing the execution plan
- Executing queries with the optimized execution plan
Storage Service is responsible for distributed data store.
Meta Service is responsible for these tasks:
- Operating CRUD on graph schema objects
- Managing the cluster
- Performing user authentication
In this case, I used Query Service as an example to show you some experience.
Source code directory hierarchy
When we get the source packages and have them unzipped, we should do a check of the source code directory hierarchy. Each package has its own functions. Here is how the src directory looks like.
|--src
|--client // Provides the code for the client
|--common // Provides some common basic components
|--console
|--daemons
|--dataman
|--graph // Contains most codes of Query Service
|--interface // Contains some communication interfaces for meta, storage, and query services
|--jni
|--kvstore
|--meta // Relates to meta service information
|--parser // Contains modules for lexical parsing (Lexer) and semantic analysis
|--storage // Contains codes about the storage layer
|--tools
|--webservice
Code tracing
In the scripts directory, use the scripts to start the metad and the storaged services.
When the services are started, run the nebula.service status all to do a check of the service status.

Start GDB and run the nebula-graphd binary program, which is in the bin directory.
gdb> set args --flagfile /home/mingquan.ji/ 1.0 /nebula-install/etc/nebula-graphd.conf //specify the arguments
gdb> set follow-fork-mode child // This is a daemon, so the new process is debugged after a fork and the parent process runs unimpeded.
gdb> b main // Set a breakpoint at entry to main
Use the run command to start the nebula-graphd program under GDB, and then use the next command to execute the code line by line until the command stops at the gServer->serve(); // Blocking wait until shut down via gServer->stop() line. It means the thread to receive the connection from the client is blocked and the server is waiting for the connection, so we need to find the function that processes the request sent from the client.
Nebula Graph uses FBThrift to define the communication interfaces for different services, and in the src/interface/graph.thrift file, you can find the communication interface definition for GraphService as follows.
service GraphService {
AuthResponse authenticate(1 : string username, 2 : string password)
oneway void signout(1 : i64 sessionId)
ExecutionResponse execute(1 : i64 sessionId, 2 : string stmt)
}
The gServer->serve() line is preceded with the following lines.
auto interface = std::make\_shared<GraphService>();
status = interface->init(ioThreadPool);
gServer->setInterface(std::move(interface));
gServer->setAddress(localIP, FLAGS\_port);
From these codes, we know that the GraphService object is the one that processes the connection and request sent from the client, so we can set a breakpoint at the GraphService.cpp:future_execute line to trace the execution.
Now, let’s launch another terminal and change the path to the nebula installation directory. Run ./nebula -u=root -p=nebula to connect to the nebula services. And then, run the SHOW SPACES statement. You will see that no result is returned. It is because the services are blocked for debugging on the server side. Let’s go back to the server side and run the continue command, and the following lines are returned.
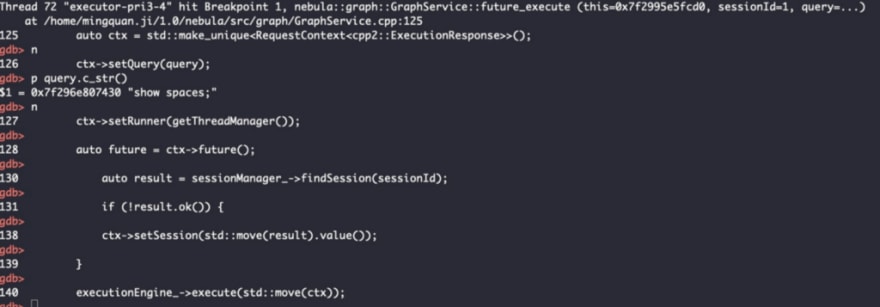
After session is verified, go to the executionEngine->execute() and run the step command to step inside the function.
auto plan = new ExecutionPlan(std::move(ectx));
plan->execute();
Run the step command to step inside the execute function of ExecutionPlan and then run the following command.
auto result = GQLParser().parse(rctx->query());
The parse module is mainly composed of Flex and Bison. Flex, working like regular expressions, is used to divide the input statements into tokens, and the src/parser/scanner.lex file is used as the lexicon data file. Bison is used to parse the tokens into an AST, and the src/parser/parser.yy file is used for semantic analysis. The semantic analysis works as follows.
go\_sentence
: KW\_GO step\_clause from\_clause over\_clause where\_clause yield\_clause {
auto go = new GoSentence();
go->setStepClause($ 2);
go->setFromClause($ 3);
go->setOverClause($ 4);
go->setWhereClause($ 5);
if ($ 6 == nullptr) {
auto \*cols = new YieldColumns();
for (auto e : $ 4 ->edges()) {
if (e->isOverAll()) {
continue;
}
auto \*edge = new std::string(\*e->edge());
auto \*expr = new EdgeDstIdExpression(edge);
auto \*col = new YieldColumn(expr);
cols->addColumn(col);
}
$ 6 = new YieldClause(cols);
}
go->setYieldClause($ 6);
$$ = go;
}
When GO statements are matched, applicable nodes are constructed for an AST, and then the nodes are handled by Bison and the AST is generated.
After lexical analysis and semantic analysis are done, the execution module works. Still inside GDB, go inside the execute function and run the step command line by line and stop at the ShowExecutor::execute line.

Run the next command line by line, and when it comes to the showSpaces() function, run the step command to step inside it.
auto future = ectx()->getMetaClient()->listSpaces(); auto \*runner = ectx()->rctx()->runner();
'''
'''
std::move(future).via(runner).thenValue(cb).thenError(error);
From the instructions above, we see that Query Service obtained the spaces data through the communications between metaClient and Meta Service, and then used the cb callback to return the data. Till now, the SHOW SPACES statement is executed completely. Other nGQL statements, even those more complicated ones, are executed in the similar way.
For a running service, it is recommended that you have the process ID and then run the gdb attach PID command to debug this process.
If you don’t want to launch both the server and the client for debugging, you can use the test directory. Each function under the src directory has its own test directory. It contains all the code for unit testing of the applicable function or module. These codes can be used to compile the functional module, and the execution can be traced. The test directory can be used as follows:
- Under a directory for a functional module, find its CMakeLists.txt file and find the module name in this file.
- In the build directory, run the make command. The applicable binary program is generated in the build/bin/test directory.
- Start GDB to debug and trace the execution.
Libraries
Before reading the NebulaGraph source code, you may need to know something about these libraries:
- Flex & Bison: tools used for lexical analysis and semantic analysis. They parse the input nGQL statements into an AST.
- FBThrift: an open-source RPC framework, developed by Facebook. It defines the communication process among the Meta, Storage, and Graph layers of NebulaGraph DBMS.
- folly: an open-source library of C++14 component, developed by Facebook. It offers functions like the Boost and the std libraries, but with optimized performance.
- Gtest: an open-source framework for C++ unit testing, developed by Google.
I hope you found this article helpful. And if you did, consider giving some 50 claps :)
You might also like
- Nebula Graph Architecture — A Bird’s View
- An Introduction to Nebula Graph’s Storage Engine
- An Introduction to Nebula Graph’s Query Engine
Like what we do ? Star us on GitHub. https://github.com/vesoft-inc/nebula
Originally published at https://nebula-graph.io on August 4, 2020.

Top comments (0)