
Kubernetes Kube-scheduler is a container scheduler, not a job scheduler.
The function of Kube-scheduler is to dispatch the newly created Pod to the most suitable worker Node. In this process, the Kube-scheduler will monitor all the worker nodes in this cluster, and select the most ideal worker node according to the Filtering and Scoring policies set by the user. In addition, we talked about Kube-scheduler currently mainly based on the running status of the server itself, to dispatch machine learning work, and did not consider the use of GPU accelerators. So Gemini designed a scheduler CRD of share Pod for the function of GPU Partitioning.
The Kube-scheduler dispatch container mode is relatively simple, it just dispatches sequentially according to Create POD request queue. Kube-scheduler does not consider the correlation of tasks and resources between POD and POD. But in the actual environment, an overall job (Job) often includes multiple related tasks (Task). How these tasks are assigned to different worker nodes has a great impact on performance. In other words, the preset scheduler of Kubernetes only considers the scheduling of individual tasks based on resource conditions, and does not consider the overall work.
Scheduling only for individual tasks, without taking into account the lack of resources for other related tasks to dispatch in time, may affect the overall work efficiency. Another possible situation is the problem of resource fragmentation, which will lead to a decline in overall resource utilization. But in the worst case, if the application's timeout recovery is not done well, it is more likely to cause a deadlock situation.
Figure 1 is a simple example:
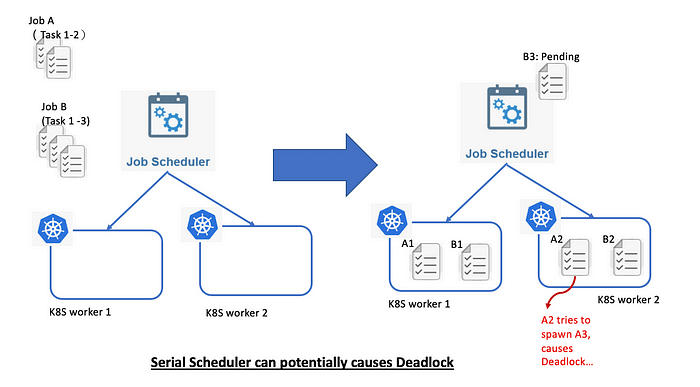
The Scheduler wants to schedule Job A and Job B. Job A has two Tasks and Job B has three Tasks. Assume that our two worker nodes can only dispatch two Tasks. In this way, Task B3 of Job B will be pending and wait for dispatch. Now if Task A2 wants to spawn off another process on worker 2, but the worker node has no resources at this time. In case Job A does not handle this situation properly, then the system will not be able to release resources to send Job B's Task B3, lead to a deadlock situation in the system.
Machine learning and HPC workload requirements for schedulers
Cloud native container architecture is undoubtedly the most popular environment for artificial intelligence, but in recent years, as the complexity of the machine learning process has increased, it has begun to expose some of the deficiencies of the Kube scheduler. From the perspective of the deep neural network of the AI model, more and more data scientists need to transmit large amounts of training data and use distributed cluster training tools such as Spark, MPI, and Horovoid (see Figure 2). The Kube-scheduler does not automatically collect these clusters. The training container is dispatched to the K8S worker adjacent to the dataset, which increases the training data transmission time.
In addition, in the development process, artificial intelligence scientists often need to perform repeated training on Jupyter IDE in the process of defining the training model (model definition). Although there is not much data for the adjustment of these model parameters, it requires multiple related containers to be dispatched quickly at the same time. The standard Kube scheduler also does not have a mechanism for dispatching a group of related PODs (PODGroup) at the same time.
Another interesting area is HPC. HPC has always been a heavyweight user of IT resources. In recent years, the rise of containers, from certain perspectives, such as mirroring tools for data analysis and CI/CD processes, is very attractive to some HPC users. But from the perspective of other technologies and usage scenarios, the philosophy of HPC and Kubernetes is quite different.
Kubernetes is different from some traditional HPC workload management tools (such as LSF, Slurm, etc.). The main reason is that Kubernetes pays more attention to deploying microservices. Each container is usually not too big and very modular. Relative HPC applications usually include various software libraries. HPC users also have many deployment scenarios that need to be topology sensitive, and they need to reserve resources, dynamically preempt running processes and other functions. . These are functions that kube scheduler does not have.
Kube Scheduler's customized solution
In view of the above-mentioned machine learning and HPC application scenarios, many people in the cloud native community have proposed various customized Kube Scheduler solutions in the past few years. The following briefly introduces two types:
- Scheduler Extender
- Multiple schedulers
Scheduler Extender
The cloud native community published Scheduler extender as early as 2018. In simple terms, Scheduler extender allows users to define some webhooks in the Filtering phase, Scoring phase, and Binding phase of Kube scheduler to extend the functions of Kube-scheduler.
Before Kubernetes launched the Scheduler Framework, the Scheduler extender was a popular way to customize the Kube-scheduler, but the Scheduler extender still had the following limitations:
Because webhook is used for customization, it is necessary to go through the RPC program of the HTTP server when the Scheduler calls out, which affects performance.
Webhook is called out after the original filter, Scoring, and Binding phases of the kube scheduler, so customization is restrictive. For example, a worker node that has been filtered out is difficult to change back.
Multiple Schedulers
This approach is considered the most flexible, because there are no limitations of the original scheduler architecture. The most famous implementations of Multiple scheduler include Volcano and Kube-Batch. Coincidentally, these two are designed to be independent schedulers for Batch job.
Multiple schedulers means that it will coexist with the original Kube scheduler. It is usually based on the POD kind to decide which scheduler to use. The advantage of course is that you can play freely. But it also has two disadvantages:
Because the two schedulers jointly manage all k8s workers, there may be conflicts in the scheduler policy, resulting in underutilized resources.
When upgrading Kubernetes, users must do additional testing to ensure that there is no incompatibility or regression testing.
More extensible Scheduler Framework
The Kube-scheduler preset by Kubernetes is dispatched one by one to the most ideal K8S Worker node to deploy containers and PODs according to the order of individual task requests. In other words, Kube-scheduler only schedules tasks and does not consider the overall job (Job) or performance. As applications in different fields, such as AI, ML, GPU, Batch Job, HPC, etc., have different workload characteristics, users have increasingly strong demands for customization of Kube-scheduler.
Scheduler extender and multiple coexisting Multiple schedulers are very popular scheduler customization methods, but they also have their limitations. In view of this, Kubernetes has proposed a more complete set of customized plugin solutions than Extender, called Scheduler Framework.
The Scheduler Framework no longer uses webhooks. Users can write their plugins in different languages, and then write these plugins in the scheduler profile to customize the behavior of Kube-scheduler.





Top comments (0)