
What is SQS?
Amazon Simple Queue (SQS) is a highly scalable managed message queue service. It lets you decouple different parts of your application and eliminate throughput bottlenecks, for example high frequency write operations from your application to your database (like in our case with MongoDB). SQS really is a simple service to use with just a few API functions and you can get up and running quickly.
It’s important to note SQS is billed by the number of requests and that you would need to optimize at high scale.
Why We Started Using SQS
At PurpleAds we work mainly with AWS EC2. It was easier for us to start with, it keeps costs low compared to managed services and you get more control over your infrastructure albeit at the cost of rising complexity as you grow.
Since we like to keep things simple and use technologies we are familiar with - we use a 2x a1.xlarge mongodb replica set for all our database needs.
Running an ad network requires storing a lot of analytics and recently, our mongo servers were having a hard time keeping up with increasing numbers of write and update operations as our network grows.
After some research, looking a lot at outputs of mongostat and mongotop, it seems that mongo is not so great when it comes to updating hundreds of fields in hundreds of documents per minute. Imagine a daily analytics document keeping data per asset, per device, per geo, per os, etc.
 The MongoDB CPU Average, at peak times it was at 97% average and crashed daily
The MongoDB CPU Average, at peak times it was at 97% average and crashed daily
So we decided to queue these ops and do periodical bulk writes instead, this would cut down the number of upsert operations by at least 10x.
Several solutions came to mind, among others we though about queueing operations in our Node application memory.
Finally we decided to go with something that we can implement quickly, easily and will give us peace of mind for a long period - AWS Simple Queue Service.
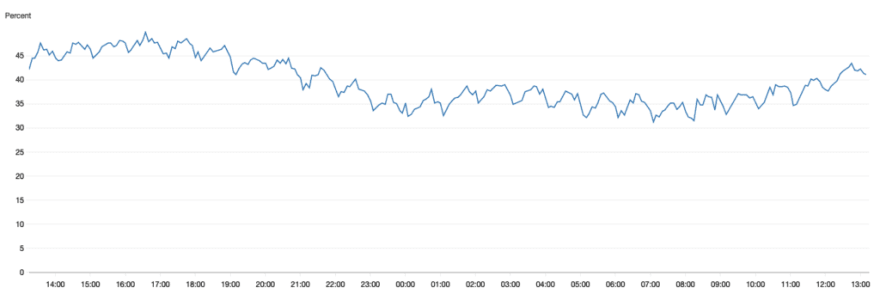 MongoDB CPU Average with SQS queued bulk writes, never crosses 50% average
MongoDB CPU Average with SQS queued bulk writes, never crosses 50% average
Having your main Node app write thousands of upsert operations to MongoDB not only overloads the database and creates locks, it also makes your Node app less responsive as it has a lot of open connections to your database.
This is not going to be one of those generic articles about SQS, we’re going to dive into how we used it to improve our mongo write performance.
The main idea was simple - send payloads to SQS and process it later in bulk with a separate worker application (a microservice if you will).
Since SQS pricing model is based on the number of requests you make. A message has to be sent, read and deleted - a total of 3 requests per message batch.
A single request can contain up to 10 messages/payloads and a maximum of 256 KB payload. So we're going to try to leep costs to minimum and offload the heavy lifting from our main app and database.
Sending Messages
The first and simple cost and performance optimization on SQS is queueing message sends.
We can send 10 messages per request, so we'll stack them up before sending them over to SQS.
You should also setup a scheduler to send messages periodically if you don’t reach the 10 message threshold in a given time. This will help you avoid losing messages on process interruptions (e.g. auto scale events, crashing, etc)
Here’s how we went about handling that:
const messages = [];
// setup a simple scheduler
setInterval(() => {
_sendQueue();
}, 10 * 1000);
// use this when you want to send a JSON message
function queueSend(object) {
messages.push(object);
if(messages.length >= 10) {
_sendQueue();
}
}
// this should not be called directly
function _sendQueue() {
if(!this.messages || !this.messages.length) {
return;
}
// max batch size is 10
const toProcess = messages.splice(0, 10);
let i = 0;
const entries = toProcess.map((mes) => {
i += 1;
return { Id: `${i}`, MessageBody: JSON.stringify(mes) };
});
sqs.sendMessageBatch({ QueueUrl, Entries: entries }).promise();
}
In case your payloads are small, you can really bring down your costs by “fooling” SQS and sending an array of payloads in a single message.
Our JSON payload was around 500 bytes on average of a JSON string. Basically we could send around 100k payloads in one message, sending 1000x less requests/messages. You would need to write a more complex processing algorithm that extracts the multiple payloads from a single message when pulling those, but that’s for another article.
Pulling Messages
Now that you have your messages in your SQS queue, you need a worker, a micro-app that would process those messages and write them into MongoDB in bulk.
SQS allows to pull up to 10 messages from the queue at a time (it can be less or even zero, more on that later), MongoDB on the other hand can send up to 1000 operations in a single bulk transaction.
A good approach here would be:
- concurrently pull 1000 or more messages in batches of 10
- process / transform / map those messages to mongodb update/upsert operations
- bulk write these operations to mongodb
- delete the messages from the SQS queue
Here’s how you can go about pulling those messages:
function sqsPull() {
return sqs.receiveMessage({
QueueUrl,
MaxNumberOfMessages: 10,
WaitTimeSeconds: 20,
}).promise();
}
const multiPulls = await Promise.all(
Array(100).fill(0).map(() => sqsPull())
);
const messages = multiPulls.map((res) => res.Messages).flat().filter((i) => !!i) || [];
// you need these to later delete the messages from the queue
const receiptIds = messages.map((m) => m.ReceiptHandle);
const json = messages.map((m) => {
try {
return JSON.parse(m.Body)
} catch(err) {
return null;
}
});
Pulling messages is nice, but what if our queue is empty? Or if we get a lot of small batches with less than 10 messages? We are paying for those requests but not maximizing our cost effectiveness.
It’s important to note that sometimes SQS will return less than 10 messages per request even if you have hundreds of messages in-flight, probably these are still being processed by SQS and not ready to be pulled.
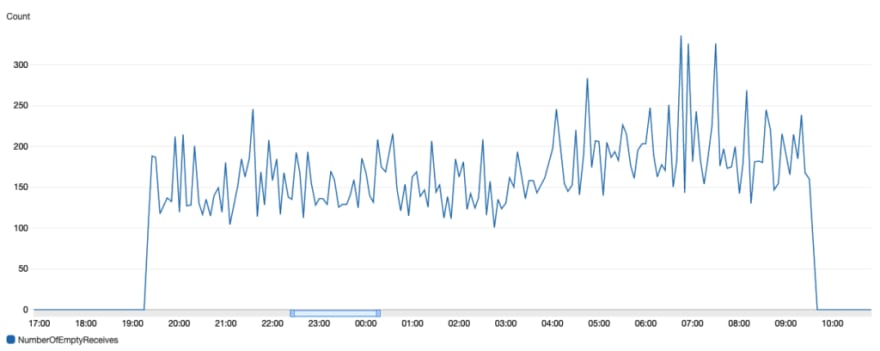 Make sure to monitor your SQS empty receives section to avoid incurring costs for empty requests
Make sure to monitor your SQS empty receives section to avoid incurring costs for empty requests
That’s why we’ve setup a “cooldown” mechanism to let the queue stack up on more messages before we process those once again. If we got 10 consecutive batches of less than 1,000 messages, we let the worker sleep for a while.
let smallBatchCounter = 0;
do {
const multiPulls = await Promise.all(Array(100).fill(0).map(() => sqsPull()));
const messages = multiPulls.map((res) => res.Messages).flat().filter((i) => !!i) || [];
...
if(message.length < 100 * 1000) {
smallBatchCounter += 1;
} else {
smallBatchCounter = 0;
}
if(smallBatchCounter >= 10) {
await new Promise((resolve) => setTimeout(resolve, 5 *60 * 1000));
}
} while(true);
Processing Messages
Processing messages is very specific to your application and schema and use case but we’ll show you what we did anyway so you can get ideas for your application. In our case, since we’re doing analytics, these are usually many field increments on a single document. So a single document could be updated by many messages in one batch (e.g. 5 requests related to one account would be 5 times { $inc: 1 }), we want to have one update operation per document. An example of how a message looks like in our case:{
"accountId": string,
"assetId": string,
"date": timestamp,
"event": "click",
"cpc": 0.5
}
You can see that there could be multiple events for a combination of accountId, assetId, date.
So we would map these out like this:
{
"accountId_assetId_date": {
"$inc": { "clicks": 1, "revenue": 0.5 },
},
....
}
Now for every 1000 messages we would get far less operations to write to mongo.
After we have our map, we would create an array of operations to bulkWrite.
const entries = Object.entries(map);
// note how we increment by 1000 every iteration (the max number of operations for mongo per bulkWrite)
for(let i = 0; i < entries.length; i += 1000) {
const ops = entires.slice(i, i + 1000).map(([key, value]) => {
const [accountId, assetId, date] = key.split('_');
const filterQuery = { accountId, assetId, date };
updateOne: {
filter: filterQuery,
update: value,
upsert: true,
},
});
await model.bulkWrite(ops, { ordered: false });
}
Deleting Messages
You would not want your messages to be processed more than once and save duplicate data. So after successfully processing messages, you should delete those.
Here again, SQS limits you to deleting up to 10 messages in a single request. So we added a helper to delete larger batches:
function deleteBatch(receiptIds = []) {
if(receiptIds.length > 10) {
throw new Error('max 10 ids per delete batch');
}
let i = 0;
const entries = receiptIds.map((rId) => {
i += 1;
return { Id: `${i}`, ReceiptHandle: rId };
});
return sqs.deleteMessageBatch({ QueueUrl, Entries: entries }).promise();
}
function deleteLargeBatch(receiptIds = []) {
const promises = [];
for(let i = 0; i < receiptIds.length; i += 10) {
promises.push(deleteBatch(receiptIds.slice(i, i + 10)));
}
return Promise.all(promises);
}
Why not FIFO queue?
First In First Out SQS queues guarantee that messages will be pulled in the order they were sent and will only be delivered once to the consumer/client.
The caveat with using FIFO queues are MessageGroupId. A message has to be associated with a group and the order of messages is only guaranteed relative to the group.
A single message group can have up to 20k messages in-flight or “waiting” to be pulled.
What if we have more than 20k? We would have to split those up to multiple groups, but then what would be the order of messages relative to other groups? We could not find an answer to this.
For our use case simple queues were sufficient, messages are delivered in-order and no messages are left behind.
Conclusion
All-in-all AWS SQS is a cheap, simple, effective and scalable service. If you’re having trouble with write through-puts, you should consider using SQS to queue and batch these operations.
Hopefully this guide will help you get started and later on help you optimize your costs and efficiency.
We’ve also published our SQS helper library on npm with many of the operations described in this article for your convenience.





Top comments (0)