 |
|---|
| Photo by Michael Dziedzic on Unsplash |
When we think about distributed systems, we picture multiple machines communicating to each other to fulfill a request, perhaps a cluster of nodes storing data in a distributed database, or more abstract concepts like consistency in the CAP theorem[1].
But have you have ever seen a distributed system with your eyes? I do not mean an architecture diagram, I mean REALLY seeing it.
I bet you do and it is likely the thing you are using to read this post, your laptop. If the last sentence surprised you, keep reading and we shall see why.
Consistency
As you already know, memory is the device used to store data used by a computer. Memory varies for its speed, cost, and volatility. At the one end of the spectrum, we have fast but expensive memory like SRAM. At the other end, we have hard drives, slow (when compared to the CPU speed), cheap, and non-volatile as they do not require power to keep data stored. In the middle, we have the DRAM technology, popular due to its cost-effectiveness.
When talking about speed, it’s good to have an idea of the numbers involved to access data stored in memory:
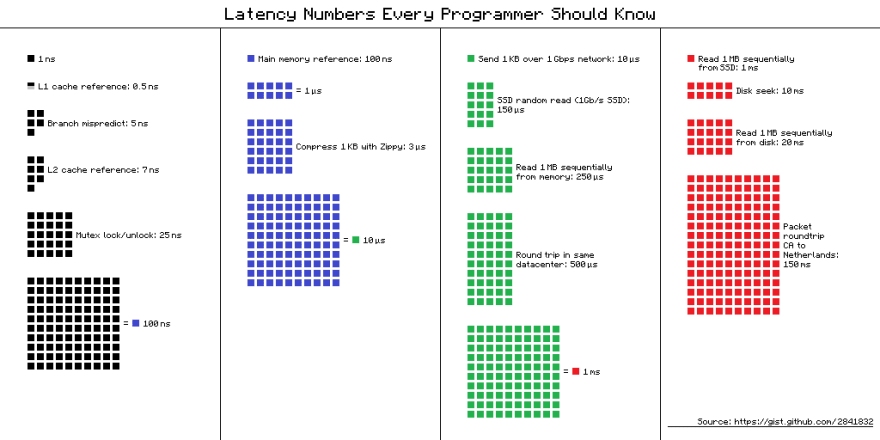 |
|---|
| Latency numbers — credit to hellerbarde via Github |
- Accessing data in an SRAM takes 0.5 nanosecond
- Accessing data from the DRAM takes 1000 nanoseconds. Roughly a thousand times slower than access in SRAM
- Accessing a date from a hard drive takes 2 million nanoseconds, that is 2 milliseconds. Roughly a million time slower than accessing an SRAM
Let’s assume you have a 1 GHz CPU, granted some simplifications [2] This means your CPU can run one instruction per nanosecond. In a naïve implementation, if we were to access a DRAM, the CPU would need to wait for about 1000 cycles doing basically nothing instead of running 1000 instructions. Lots of wasted compute capacity. If instead, we were to use an SRAM, the memory would be able to keep up with the CPU, thus not wasting precious cycles.
Ideally, we would love to equip our computers with the biggest amount of high-speed memory, but unfortunately, high-speed memory is expensive which brings us to a fundamental theorem of engineering: there is no such thing as free lunch. Engineering is a matter of finding the best trade-off between costs and performance.
Luckily two properties help computer designers with this trade-off: spatial and temporal locality. Spatial locality property says that instructions that are stored nearby to the recently executed instruction have high chances of execution. Temporal locality instead expresses the tendency of programs to use the same piece of data multiple times during the course of their execution. Those emergent properties do not surprise us since the CPU runs instructions one after the other and programs tend to access data multiple times during execution. These somewhat intuitive properties suggest organizing our memory hierarchically, with faster memory close to the CPU (SRAM commonly used for caches and CPU registers) and slower memory in the upper layer of the hierarchy (DRAM also referred to as main memory).
During a read operation, the CPU tries to access the data from the cache and use it if it’s there. In case it is not, the data needs to be copied from the main memory to the cache before the CPU can use it. The CPU does not copy just the data it needs, but a whole block of contiguous addresses (spatial locality).
Because the cache must be smaller than the main memory, at some point it will become full and some of the entries in the cache must be evicted. Which ones? The policy most commonly used is to remove the least recently used item (temporal locality), usually with some approximation depending again on a cost-benefit trade-off.
To gain better performance, system designers build systems with multiple CPUs interconnected on the same physical bus. Each CPU access the same memory which means that memory becomes a shared resource.
To recap, we have multiple CPUs interconnected on a bus, each CPU has its own cache and they all access the same shared memory:
 |
|---|
| Cache organization — credit to Kunal Buch, CC BY-SA 4.0, via Wikimedia Commons |
Each CPU populates the cache based on the data it needs to access, the so-called local copy of the data. The same data could be used by different CPUs which means we could end up with multiple copies of the same data in different caches. But what happens when one of the CPU updates its local copy of the data? We have a typical distributed system problem: keeping multiple copies of the same data synchronized when one of the processors updates its local copy. This is what distributed systems folks call a consistency problem. For hardware engineers instead, this is the cache coherence problem. [3]
Conclusions
Our laptop is a highly coupled distributed system where each node is a CPU.
Albeit hardware engineers need to solve a class of problems frequently encountered in a multi-machine distributed system, a major distinction separates the way the problems are solved. In a computer, components are physically connected via each other on the bus, if not even collocated on the same chip. Multi CPUs systems do not need to deal with network partitions, message reordering, partial failure, and all the other properties of an unreliable network.
Turns out that the network is really what makes distributed systems hard [4].
Follow me on Twitter to get new posts in your feed.
Credit for the cover image to Michael Dziedzic via Unsplash
[1] Consistency - Availability - Partition tolerance tradeoffs. The extension to the CAP theorem is called PACELC
[2] The simplification does not account for pipelining, multiple cores, instructions that take multiple cycles to complete
[3] Out of order execution. The similarities between our laptop and distributed systems do not stop here. Modern CPUs adopts another trick to improve CPU performance: they are allowed to run instructions in an order different from the specified in the program. Of course, this means increasing the complexity of the system which now needs to guarantee consistency in the presence of instructions executed out of order
[4] Of course, this does not mean that CPU design is easy

Top comments (0)