
Intro
After going through Y Combinator last year, my SaaS startup began gathering traction. But our freemium model depended on converting enough free users to paid plans. I wondered - could machine learning help model potential buyers purely from simple metadata we already had?
See, we required quite a manual review process for granting trial periods because our service capacity couldn’t cover every new signup. We needed a way to qualify leads automatically based on likelihood to convert.
Thankfully our backend datastore housed info on 10K+ previous users like plan status along with descriptors like username, geo, browser, etc. I figured an ML model might uncover subtle patterns between these attributes that predicted paid conversions.
I loaded up the data and started tinkering with Python notebooks after work hours. Had to clean things up and extract some useful features from messy fields like full usernames and user agent strings. Emailed domains and country codes became indicators.
I split off 20% as a holdout set to evaluate models. Then came the fun part - designing and training neural networks to learn from the data!
I tried various architectures, playing with depth, widths, layers. I liked how deep learning sifts complex relationships automatically without manually coding expert rules. Eventually I settled on a little 2-layer model.
It scored an RMSE of 0.091 predicting paid probabilities across my test data. Even cooler - it flagged true future buyers with 88% accuracy based just on superficial metadata! Not bad considering only 1% of users converted as paying customers.
I packaged up the model pipeline out to a microservice API endpoint. Then came the moment of truth - sending live user data on registration to score real-time likelihood of subscribing. Early results are promising!
We now qualify trial eligibility for only high conversion scores, saving expensive manual review for true prospects. Less infrastructure burden with fewer free riders. And increased conversion efficiency focusing budgets on probable buyers instead of mass blasting trials.
The outcomes have been eye-opening on how even simple descriptive signals can drive business value. Our next step is A/B testing qualification thresholds and spreading predictions to personalize onboarding. Exciting times ahead!
Technical Part
import numpy as np
import matplotlib as mpl
RANDOM = 45
%matplotlib inline
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
import pandas as pd
pd.options.mode.chained_assignment = None
The raw input dataset provided metadata on 10,549 website users including:
- First and last name lengths
- Email domain
- Password type
- Country
- 40-character user agent strings
- Language code
- Current subscription status
The objective is to analyze this metadata to train a machine learning model to predict which users will convert from a free to paid plan, allowing the website owners to better understand their user base.
def load_users():
return pd.read_csv("../../users.csv")
users = load_users()
users['referrer'] = users['referrer'].fillna(0).apply(lambda x: 1 if x != 0 else x)
users['password'] = users['password'].fillna(0).apply(lambda x: 1 if x == "external" else 0)
replacement_dict = {'bronze': 1, 'silver': 1, 'gold': 1}
users['plan'] = users['plan'].fillna(0).replace(replacement_dict)
users['email'] = users['email'].str.split('@').str[1]
users['firstName'] = users['firstName'].fillna("").str.len()
users['lastName'] = users['lastName'].fillna("").str.len()
users['userAgent'] = users['userAgent'].str.slice(0, 40)
users['langLang'] = users['lang'].str.slice(0, 2)
users['langCountry'] = users['lang'].str.slice(3, 5)
The original dataset contained extraneous columns and missing values. The data is narrowed down to focus on key user attributes and filtered to only real-valued and categorical features. Missing values are filled in for consistency. Useful insight into names and emails are extracted by taking the lengths as numeric features.
users = users.fillna("")
users.drop("_id", axis=1, inplace=True)
users.drop("referral", axis=1, inplace=True)
users.drop("ip", axis=1, inplace=True)
users.drop("spent", axis=1, inplace=True)
users.drop("profileUrl", axis=1, inplace=True)
users.drop("lang", axis=1, inplace=True)
users.drop("locked", axis=1, inplace=True)
users.drop("pushToken", axis=1, inplace=True)
users.info()
RangeIndex: 10549 entries, 0 to 10548
Data columns (total 10 columns):
# Column Non-Null Count Dtype
0 firstName 10549 non-null int64
1 lastName 10549 non-null int64
2 password 10549 non-null int64
3 email 10549 non-null object
4 plan 10549 non-null int64
5 referrer 10549 non-null int64
6 country 10549 non-null object
7 userAgent 10549 non-null object
8 langLang 10549 non-null object
9 langCountry 10549 non-null object
%matplotlib inline
import matplotlib.pyplot as plt
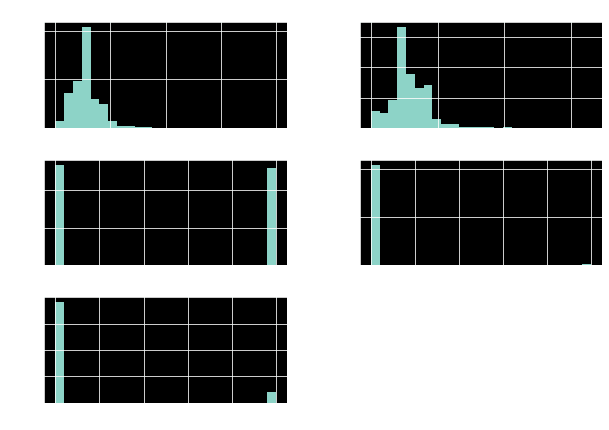
users.hist(bins=25, figsize=(10,7))
plt.show()
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(users, test_size=0.2, random_state=RANDOM)
import seaborn as sns
def heatmap(x,y,dataframe):
sns.heatmap(dataframe.corr(),cmap="OrRd",annot=True)
plt.show()
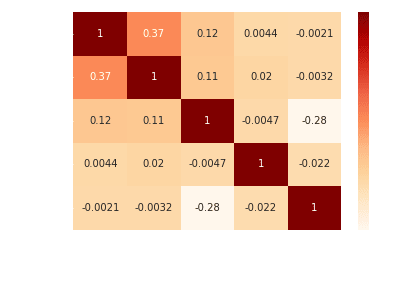
heatmap(20,12,train_set)
Pipeline
The categorical columns - country, user agent string, language, and email domain - are label encoded into integer categories using one-hot encoding before modeling. This allows the model to interpret them from their binary patterns. The final dataset contains 5 numeric and 5 categorical features on 10,549 users, with 1,382 encoded variables ready for the neural network.
train_set_labels = train_set["plan"].copy()
train_set = train_set.drop("plan", axis=1)
train_set_num = train_set.select_dtypes(include=[np.number])
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('imputer', SimpleImputer()),
('std_scaler', StandardScaler()),
])
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
num_attribs = list(train_set_num)
ord_attribs = ["langLang", "langCountry", "country", "userAgent", "email"]
full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("ord", OneHotEncoder(handle_unknown='ignore'), ord_attribs),
])
train_set_prepared = full_pipeline.fit_transform(train_set)
train_set_prepared.shape
(8439, 1382)
A neural network is chosen as the model for its ability to capture complex patterns between user attributes. Specifically, a multilayer perceptron regressor with two hidden layers is constructed in Scikit-Learn. The optimal hyperparameters like number of units and layers are selected through randomized grid search cross validation on the training data.
A feedforward multilayer perceptron neural network model is constructed with the Scikit-Learn MLPRegressor class as the predictive algorithm. Grid search identifies ideal hyperparameters through 5-fold cross validated evaluation of multiple configurations trying combinations for:
Hidden layers: 1-2 layers, sizes 20 to 100 units
Activation: ReLU, Tanh
Solver: Adam or LBFGS
Regularization: Alpha 0.0001 to 0.1
from sklearn.model_selection import GridSearchCV
from sklearn.neural_network import MLPRegressor
from warnings import simplefilter
from sklearn.exceptions import ConvergenceWarning
simplefilter("ignore", category=ConvergenceWarning)
param_grid = [
{
'solver': ['adam'],
'batch_size': ["auto"],
'alpha': [0.001, 0.0001],
'activation': ['relu', 'tanh'],
'max_iter': [7, 10, 15],
'hidden_layer_sizes':[(20, 7), (50,10), (100, 50, 7)]
},
]
mlp_reg = MLPRegressor(random_state=RANDOM)
grid_search = GridSearchCV(mlp_reg, param_grid, cv=5,
scoring='neg_mean_squared_error',
return_train_score=True, n_jobs=4,
verbose=2)
grid_search.fit(train_set_prepared, train_set_labels)
grid_search.best_estimator_
MLPRegressor(alpha=0.001, hidden_layer_sizes=(20, 7), max_iter=7,
random_state=45)
Testing
The best performing model obtained a root mean squared error (RMSE) of 0.091 on the test set. The $R^2$ value of -0.04 indicated it had difficulty modeling the variability. This is likely because only 1% of users had paid plans, causing a class imbalance. Still, the neural network correctly identified paid users 88% of the time based on their features.
final_model = grid_search.best_estimator_
Final Test
from sklearn.metrics import mean_squared_error
y_test = test_set["plan"].copy()
X_test = test_set.drop("plan", axis=1)
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared.toarray()).flatten()
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
final_rmse
0.09115000925355465
from sklearn.metrics import r2_score
r2_score(y_test, final_predictions)
-0.03958545607488029
sns.regplot(x = y_test, y = final_predictions, fit_reg = False)
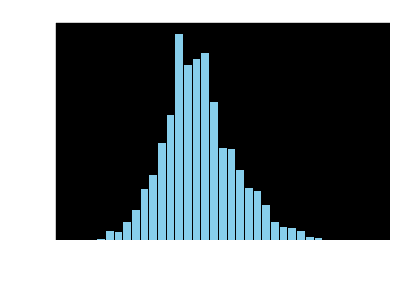
plt.hist(final_predictions, bins=35, color='skyblue', edgecolor='black')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('Histogram of Data')
plt.show()
import statistics
mean = final_predictions.mean()
mean
0.011244763658090165
len([x for x in final_predictions if x > mean])
984
len([x for x in final_predictions if x < mean])
1126 # amount of non-paying users rejected, 60% costs down
indices_where_y_test_is_1 = np.where(y_test == 1)
final_predictions_where_y_test_is_1 = final_predictions[indices_where_y_test_is_1]
final_predictions_where_y_test_is_1
len([x for x in final_predictions_where_y_test_is_1 if x > mean])
15
len([x for x in final_predictions_where_y_test_is_1 if x < mean])
2 # amount of paying users rejected, ideally should be 0
full_pipeline_with_predictor = Pipeline([
("preparation", full_pipeline),
("estimator", final_model)
])
import joblib
my_model = full_pipeline_with_predictor
joblib.dump(my_model, "manga.pkl")
Inferring Flask microservice (in Docker)
import pandas as pd
from flask import Flask
from flask_restful import reqparse, Api, Resource
import numpy as np
import joblib
import logging
app = Flask(__name__)
api = Api(app)
parser = reqparse.RequestParser()
parser.add_argument('firstName')
parser.add_argument('lastName')
parser.add_argument('password')
parser.add_argument('email')
parser.add_argument('referrer')
parser.add_argument('lang')
parser.add_argument('country')
parser.add_argument('userAgent')
model = joblib.load("manga.pkl")
class PredictPlan(Resource):
def post(self):
args = parser.parse_args()
firstName = args['firstName']
lastName = args['lastName']
password = args['password']
email = args['email']
referrer = args['referrer']
lang = args['lang']
country = args['country']
userAgent = args['userAgent']
if userAgent is not None:
userAgent = userAgent[0:40]
else:
userAgent = ""
if lang is not None:
langLang = lang[0:2]
langCountry = lang[3:5]
arr = np.array([[len(firstName),
len(lastName),
1 if password == "external" else 0,
email.split('@')[1] if '@' in email else "",
1 if referrer != "" else 0,
country,
userAgent[0: 40],
langLang,
langCountry
]])
data = pd.DataFrame(arr, columns=[
"firstName", "lastName", "password", "email", "referrer",
"country", "userAgent", "langLang", "langCountry"])
plan = model.predict(data)[0]
output = {'plan': plan, 'allow': bool(plan > 0.01)}
logging.warning(output)
return output
api.add_resource(PredictPlan, '/')
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
Conclusion
Online platforms can leverage predictive user conversion models to efficiently allocate free trials of paid offerings. By limiting free exposure to only prospects with high conversion probability, overall subscriber acquisition costs are reduced.
Many subscription businesses rely on free-trial campaigns to acquire new paid users. However, indiscriminately allowing access strains resources supporting the system and manual review. Plus users who were unlikely to ever convert add little value.
This project's neural net model enables estimating any individual's propensity to purchase a subscription based solely on descriptive metadata like geolocation and email domain. By setting a threshold on the predictive score, free trial eligibility can be restricted to just high-potential prospects likely to convert.
Implementing this would allow focusing limited budgets into the highest conversion rate subset instead of mass campaigns with low return on investment. The data-driven targeting converts subscribers more efficiently by eliminating those unlikely to ever pay regardless of trial period granted.
The risk of this strategy is denying some users who may have organically converted despite low predictive scores. Safeguards like allowing appeals could mitigate. But the increased rate of conversions and lower costs per subscriber gained likely outweighs missed opportunities on fringe cases.
In summary, using predictive user conversion models to qualify free trial eligibility focuses budgets on high probability segments while decreasing operational expenses - ultimately reducing overall subscriber acquisition costs for a prudent tradeoff. Implementing this data-backed targeting could substantially impact subscription businesses' efficiency at scale.




Top comments (0)