Let us understand why data is the new ‘oil’
This article is a part of series on Data Science. If you haven’t read part I of this series, then you can read it by clicking here.

You may have heard a new quote in the tech circles recently that ‘Data is the new oil!’. Today, we will be understanding this fact and building our thought process to understand that how it relates to the problem. Then, we will move on to solution :
Problems :

In the first part, we understood that there’s a lot of Data in the form of both closed and open source data sets in the world. So, it means we have lots of data out there.
You might be thinking that if we have this lots of data, then, it’s good. What’s the issue then?
Issue is that most of the data which is present today is stored in silos. It’s used just for analytical purposes and at most people are using it to gain some insights using business intelligence and data analytics tools.
Solution :
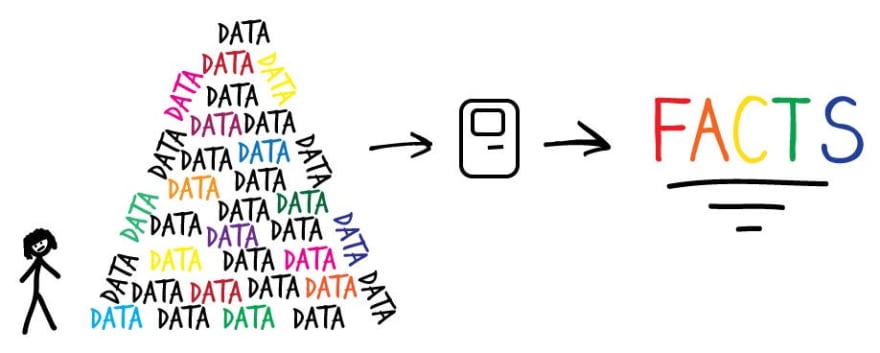
So, you got the problem?
Right…
Let us build the solution…
You know data is unused. Solution is obvious. To use it.
Data is in silos. It’s isolated. Solution is to bring it to the processes.
Data is not involved in decision making. Solution is to give power to data.
Data is underutilized. Solution is to utilize it for decision making.
That’s where the power of data lies.
What’s next ?
At this stage, we have a pretty good understanding of Data Science. Now let us move one step further.
As we know, every field in the world has got some tested processes to prepare something. For example, if you want to make Pizza, it has well established recipes which you can tweak a bit but base process remains the same.
So, to deal with a Data Science problem, we follow a process called ‘Data Science Process’.
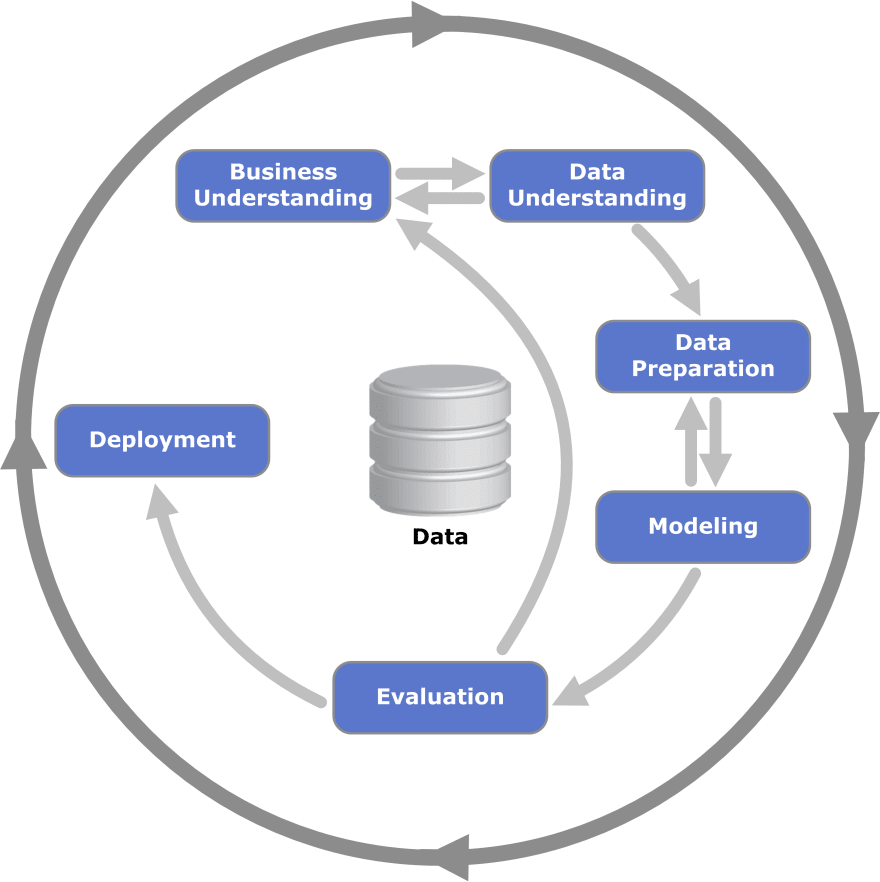
Data Science Process consists of following steps :
Business Understanding
Data Understanding
Data Exploration
Modeling
Evaluation
Deployment
Let us revisit each one of them :
i. Business Understanding :

Business Understanding is the foremost needed skill for a data scientist. It doesn’t mean that you need to be a guru of that field but instead basic understanding of that particular area should be developed in order to prevent any misconception.
ii. Data Understanding :

Understanding of your data is also important. It means that you should never assume things about your data set. Mostly, data is noisy and you have to clean it manually using different techniques so, beware of that.
iii. Data Exploration :

In this step, you try to understand the behavior of your data by different statistical methods and visualizations. It is also commonly know as Exploratory Data Analysis (EDA).
iv. Modeling :

This part involves application of an appropriate data science model to your problem. Choice of a data science model depends on nature of problem, nature of data, noise in data, behavior of data and other factors.
v. Evaluation :

Evaluation step involves quantifying your data science model against a set of metrics which are used to measure the performance of a model. This method tell us how feasible is our model according to business needs and other factors. If model fails here, whole process is repeated from start.
vi. Deployment :
If your data science model passes the Evaluation step, then it’s deployed for live testing. Again, different metrics are used to evaluate it. More data is fed according to requirements and this cycle goes on.
Did you enjoy the article?
Comment below to let me know how Data Science will change the world?

Top comments (0)