Before we start talking about K-Nearest Neighbors, I'm going to list other common classification algorithms in Machine Learning:
- Logistic regression
- Support Vector Machines
- Decision trees
- Random forests
- Naive Bayes classifier
Now I'm gonna focus on the questions that are probably in your head right now.
What is the K-Nearest Neighbors algorithm?
This algorithm is used to solve the classification model problems. K-nearest neighbor or K-NN algorithm creates an imaginary boundary to classify the data. When new data points come in, the algorithm will try to predict that to the nearest of the boundary line.
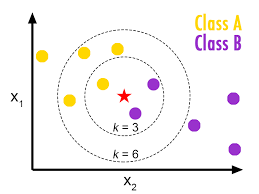
It could look like this:
From this image, you would be able to depict that:
When
k=3the new data point(the star) introduced is going to be classified into Class B because there are more Class B data points in the imaginary boundary.When
k=6the new data point(the star) introduced is going to be classified into Class A because there are more Class A data points in the imaginary boundary.
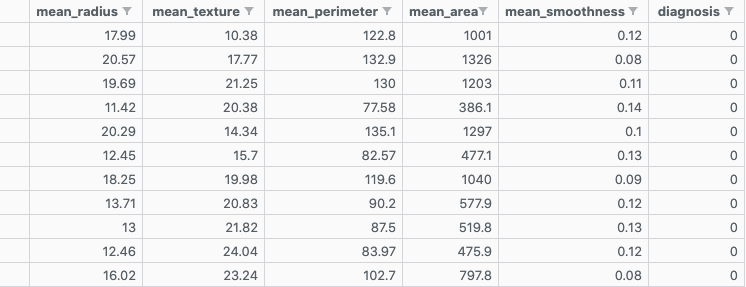
Before we start coding you'll need to install the dataset we're gonna use. Click here to install the dataset we're gonna use. Open the file named Breast_cancer_data.csv. You should see something like this:
GOAL OF THE DAY
We're gonna make a classification model that would be able to predict whether a breast is cancerous or not.
We're gonna start coding now.
Importing the needed libraries
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
Load and view the dataset
df = pd.read_csv('Breast_cancer_data.csv')
df.head()
OUTPUT
Feature Extraction
data = df[["mean_radius", "mean_texture", "mean_perimeter", "mean_area", "mean_smoothness"]]
data = data.values.reshape(-1,5)
labels = df["diagnosis"]
Making a classification model
classifier = KNeighborsClassifier(n_neighbors=100)
classifier.fit(data, labels)
print(classifier.score(data, labels))
Just know that n_neighbors represents k
OUTPUT
0.8945518453427065
Making predictions with your model
print(classifier.predict([[7.76,24.54,47.92,181.0,0.05263]]))
OUTPUT
[1]
This shows that this is a cancerous breast but who knows, our model's prediction might be wrong. Just know that even if your model has a high score some of its predictions might still be wrong.
You can visit Kaggle to find more datasets that you can perform Classification with K-Nearest Neighbors.
Check out my Twitter or Instagram.
Feel free to ask questions in the comments.
GOOD LUCK 👍



{kind=link}
{kind=link}
{kind=link}
Top comments (0)