
A common issue that many companies often face, including DEV, is how much data access to give their engineers. Allowing engineers access to production data has many benefits. It can help them make more informed decisions when they are working on projects because they have a clear picture of the data they will be working with. It is also helpful in debugging situations when production code breaks and an engineer needs to figure out why.
On the flip side, allowing engineers access to production data is also a risk. You don't want an engineer to accidentally change something in the database they shouldn't. You also might have sensitive customer data in your database that you don't want engineers to see. We ran into this exact problem at DEV and found a solution we are really happy with which I wanted to share with everyone.
Hello Blazer
First, we tackled the database access issue. How do we give access to the database and all its information to our engineers? Some companies allow engineers access to a production console. This is not an option for us because we use Heroku and only a couple of senior engineers have full Heroku access which you need in order to start a console.
With console access off the table, we started looking for other ways we could do it. That's when we found the Blazer gem written by Andrew Kane. When installed, Blazer allows users to query your database via a web UI like below.
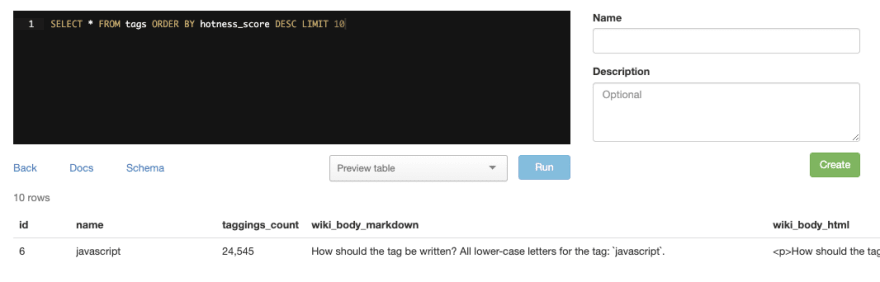
In addition to allowing users to query your database, Blazer has tons of other nice features such as:
- Saving your queries to reuse later
- Optionally track all queries that are run
- Make charts from your queries
- Work with other datasources
- Smart Variables and Smart Columns

This was exactly what we were looking for so we went ahead and added Blazer to DEV by following steps which are outlined on the gem's homepage.
A couple of things to note. First off, we only gave super_admins access to Blazer because we still had to sort out the data privacy and read-only access issues.
authenticate :user, ->(user) { user.has_role?(:super_admin) } do
mount Blazer::Engine, at: "blazer"
end
Development Set Up
Notice that Blazer uses an ENV variable BLAZER_DATABASE_URL to know where to point to look at your database. In development, I found that if BLAZER_DATABASE_URL is nil then Blazer will use your ActiveRecord connection to talk to your database. This makes getting it set up and working in development super easy.
Production Set Up
The BLAZER_DATABASE_URL can also allow you to set up Blazer to use a separate user to talk to your database. One of the big things we want to prevent with Blazer is engineers accidentally changing production data. Per the Blazer README:
Blazer tries to protect against queries that modify data (by running each query in a transaction and rolling it back), but a safer approach is to use a read-only user.
Even though Blazer uses a transaction we wanted to be extra careful and use it via a read-only user. Having a separate URL from our default ActiveRecord connection allows us to use a read-only user's credentials in the url to ensure no data is ever changed.
ENV["BLAZER_DATABASE_URL"] = "postgres://read-only-user:read-only-user-password@hostname:5432/database-name"
Setting Up a Read-only User
Blazer even offers docs on how to set up a read-only user for your given database. Since we use Postgres and Heroku I created the read-only user via our Heroku Postgres add-on following the steps outlined in Heroku's Postgres guide.
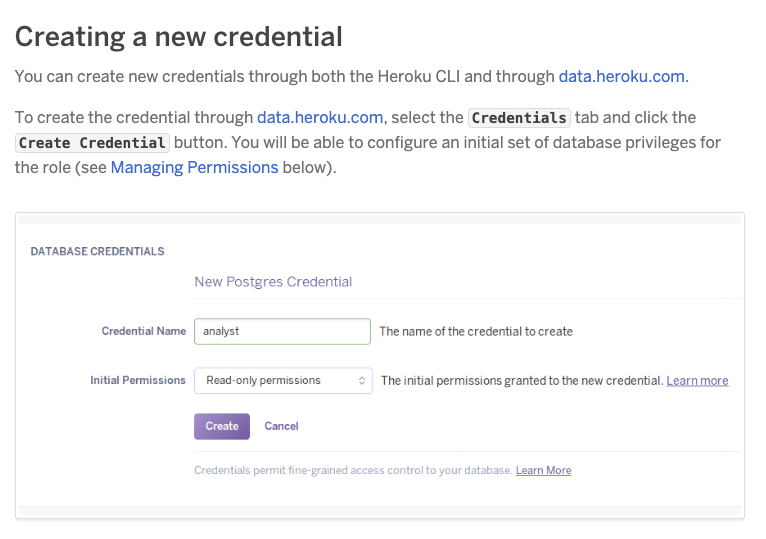
Once you have your new user in place then you want to take that user's name and password and your database name and create your BLAZER_DATABASE_URL.
With the BLAZER_DATABASE_URL set, we now have a UI in place for querying our production database and the database is protected against being changed in any way. The only thing left to do is filter the data.
Enter Hypershield

No, not that kind of shield! The shield we were looking for was one that could hide sensitive user data for us. To accomplish this, once again we turned to another one of Andrew Kane's gems, Hypershield. How it works:
Hypershield creates shielded views (in the hypershield schema by default) that hide sensitive tables and columns. The advantage of this approach over column-level privileges is you can use SELECT *.
The first step to getting this to work was to install the gem and create a list of columns we wanted to shield. We installed the gem in our production group since we only want this running in production.
group :production do
gem "hypershield", "~> 0.2.0" # Allow admins to query data via internal
gem "nakayoshi_fork", "~> 0.0.4" # solves CoW friendly problem on MRI 2.2 and later
gem "rack-host-redirect", "~> 1.3" # Lean and simple host redirection via Rack middleware
end
Next, we created a list of columns we wanted to shield in our hypershield.rb initializer file.
if Rails.env.production?
Hypershield.enabled = ENV["ENABLE_HYPERSHIELD"].present?
# Validate that hypershield schema exists before trying to use it
begin
if ActiveRecord::Base.connection.schema_exists?("hypershield")
# Specify the schema to use and columns to show and hide
Hypershield.schemas = {
hypershield: {
# columns to hide
# matches table.column
hide: %w[
auth_data_dump
email
encrypted
encrypted_password
message_html
message_markdown
password
previous_refresh_token
refresh_token
secret
token
current_sign_in_ip
last_sign_in_ip
reset_password_token
remember_token
unconfirmed_email
]
}
}
# Log SQL statements
Hypershield.log_sql = false
end
rescue ActiveRecord::NoDatabaseError
Rails.logger.error("Hypershield initializer failed to check schema due to NoDatabaseError")
end
end
One thing you will notice is that we have a couple of extra lines doing different checks before we configure Hypershield. First, we have:
Hypershield.enabled = ENV["ENABLE_HYPERSHIELD"].present?
This line will disable the Hypershield schema refresh task which happens when migrations are run if the ENV variable ENABLE_HYPERSHIELD is not present.
Next, we have:
if ActiveRecord::Base.connection.schema_exists?("hypershield")
This ensures that if the hypershield schema does not exist we won't try to set it up and fail with an error. These two lines are important because there are other communities using the DEV application source code and we didn't want them to break due to a missing, completely optional, feature we added to the application.
Creating the Schema
Once the gem and initializer are in place, next we need to create the hypershield schema. Since we are working in Postgres, here are the steps we took to set it up. These set up steps and those for other database types are documented in the gem's README.
Create a new schema in your database
CREATE SCHEMA hypershield;
Grant privileges to the user you have setup with Blazer. In our case, we want to grant all of these privileges to our read-only Blazer user that we set up via Heroku.
GRANT USAGE ON SCHEMA hypershield TO readonly-blazer-username;
-- replace migrations with the user who manages your schema
ALTER DEFAULT PRIVILEGES FOR ROLE heroku-default-user IN SCHEMA hypershield
GRANT SELECT ON TABLES TO readonly-blazer-username;
-- keep public in search path for functions
ALTER ROLE readonly-blazer-username SET search_path TO hypershield, public;
If you are working on Heroku you can run these commands via a Rails console.
sql = <<-SQL
CREATE SCHEMA hypershield;
SQL
ActiveRecord::Base.connection.execute(sql)
Or you can connect directly to Postgres via the Heroku CLI using those Blazer user credentials you set up earlier.
heroku pg:psql postgres-app-name --credential readonly-blazer-username --app your-app-name
I found that the last ALTER ROLE statement needed to be run by our read-only Blazer user so you might have to use the Heroku CLI with that user's credentials for that one. Another small Heroku gotcha is that when you set up the read-only Blazer user it is given full access to the public schema. You will want to revoke this with the following command. This ensures that your Blazer user can ONLY view the shielded views set up by your Hypershield gem.
REVOKE ALL PRIVILEGES ON ALL TABLES IN SCHEMA public FROM readonly-blazer-username;
Putting It Altogether

After you have your shielded schema in place with your read-only Blazer user it is time to test it out on Blazer to make sure everything works as expected. An easy way to do this is to run a SELECT * query on one of the tables you expect to be filtered. In our case, I tested it out with messages.
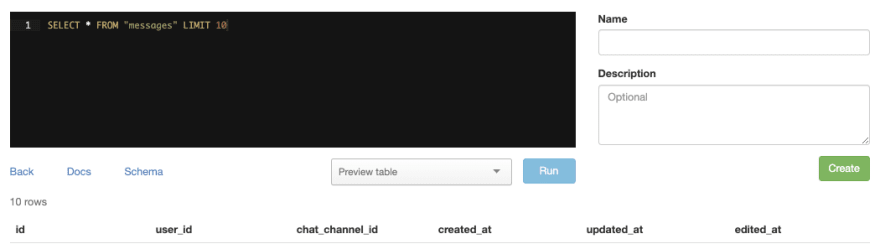
As expected, none of the message text or body fields are present. Another way to test it out is to request one of the fields you blocked from a table. In this case, I try to explicitly request message_html from messages and as you can see I get an error.
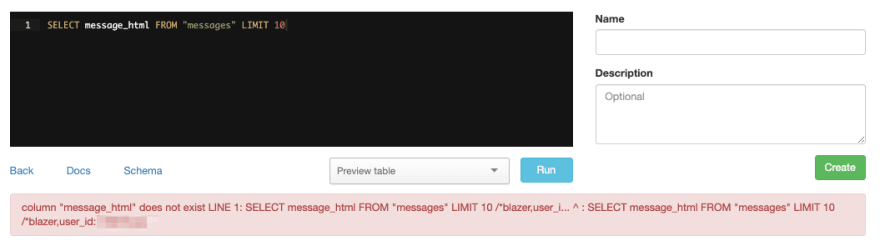
When you are satisfied with all of your testing, the last thing you need to do is expose Blazer to those you want to be able to use it. At DEV we choose to allow all tech admins(basically engineers) access to the Blazer console.
authenticate :user, ->(user) { user.has_role?(:tech_admin) } do
mount Blazer::Engine, at: "blazer"
end
DONE!
And with that, you are done! Now sit back and wait for the praises to roll in from your fellow devs who can now access the data they have so desperately needed.






Top comments (10)
I'd been really rigid about this, for good reason, because as we scale the team we absolutely cannot provide broad access to private user information. Handling this thoughtfully from day one was really important for the organization. I'm really happy we eventually settled on this approach.
I'm also really excited that we did it in an entirely open source way where we can build on it as we need and it will come bundled with all uses of our software going forward.
Really great stuff Molly and team :)
One more thing: I'd love us to eventually get to true E2E encryption on certain private actions, but not quite sophisticated enough to make that work right now.
For anyone out there using SQL Server, it has a built in feature called dynamic data masking. You can tell which columns contain sensitive data and different database users can be given access to see actual values.
Other than that, great post! 🙂
I’m a huge fan of Blazer. At a previous company, we always ran it against a read-only DB replica (which we already had) to avoid having to deal with user permissions, but I do like the idea of Hypershield filtering out certain columns. That looks like it requires making that secondary user, right?
The other thing about Blazer that I always loved was that it helped us check a given query’s performance against a real production dataset. When you run a query against a development dataset, it’s always going to be fast because there’s next to nothing there, and you also can’t trust the query planner to run a given query the same way in two different DBs since it adapts to the quantity and diversity of the data. Running the actual query plan in production is super nice.
Yes, because you don't want to restrict your default user to anything otherwise you will probably have a bad time haha
Me delivering heaps of praise to Molly for this awesomeness (seriously, this has already been a lifesaver at DEV!):
This is great. Thanks for sharing.
The projects I work on have production access limitation. Right now I don't leadership approving using Blazer + Hypershield combo but now I know what to offer in case the situation comes up 😁
Great explanation Molly. Now I just need to start using Blazer 😉
I have a webapp that's in NodeJS, can I run Blaze as a standalone docker container w/o other Ruby apps?
Not sure, worth looking into