![Cover image for Web Scraper with Python (Beautiful Soup) & Deployment of it into Heroku [Part1]](https://media.dev.to/cdn-cgi/image/width=1000,height=420,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2F1tasz9xptrqo986u42lv.png)
A while ago I decided to create a web crawling project using Beautiful Soup (a Python library for pulling data out of HTML and XML files). Here is how I did it, hurdles I faced during development and how I overcame them.

We will use Virtual Environment throughout the development, here are the instructions on how to install it in Windows and here are the reasons.

To deactivate your virtual Environment simply type deactivate
![]()
Then we will create a requirements.txt file for listing all the dependencies for our Python project.
 Your requirements might differ depending on your case.
Your requirements might differ depending on your case.
requirements.txt is important! I was too lazy to do this step at the first attempt... However, sooner or later you have to do it at least in order to push it into Heroku.
pip install -r requirements.txt is the command to install the list of requirements.
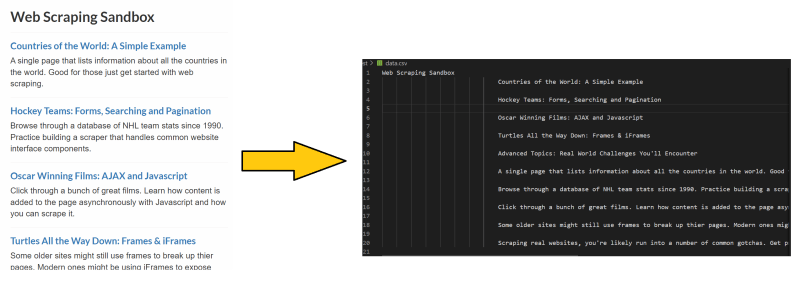
Now let me show to you how to write code to actually scrap the given web site. In a nutshell, web scraping is extracting data from websites into the form of your choice (I wrote "https://www.scrapethissite.com/pages/" to csv file).
First we make web requests using python requests library.
As you can see below, we printed the content of received information and it is the same HTML page, which you can see with the keyboard combination of Ctrl+U in Chrome or by pressing the right click on your mouse, then View page source.

import requests
from bs4 import BeautifulSoup
link = "https://www.scrapethissite.com/pages/"
request = requests.get(link)
print(request.content)


To withdraw actual data from HTML tags we are going to reach for the help of Beautiful Soup library.
Get .text from <title> tag:
import requests
from bs4 import BeautifulSoup
link = "https://www.scrapethissite.com/pages/"
request = requests.get(link)
soup = BeautifulSoup(request.content, "html5lib")
print(soup.title.text)

Withdraw hyperlinks with .a tag:
import requests
from bs4 import BeautifulSoup
link = "https://www.scrapethissite.com/pages/"
request = requests.get(link)
soup = BeautifulSoup(request.content, "html5lib")
print(soup.a)
.find_all():
import requests
from bs4 import BeautifulSoup
link = "https://www.scrapethissite.com/pages/"
request = requests.get(link)
soup = BeautifulSoup(request.content, "html5lib")
for i in soup.find_all('h3'):
print(i.text)

You can even search with CSS class .find_all(class_="class_name")
import requests
from bs4 import BeautifulSoup
link = "https://www.scrapethissite.com/pages/"
request = requests.get(link)
soup = BeautifulSoup(request.content, "html5lib")
for i in soup.find_all(class_='class_name'):
print(i.text)

The rule of thumb here is to find the piece of data from the source code of the web site (via Ctrl+F in Chrome) and extract the data using whatever tag it is in.

There are many tags on Beautiful Soup, and from my experience what I found out is, often tutorials or/and posts are not perfectly suitable for your case. Reading it on post sounds like I am shooting myself in the foot, doesn't it? 😅 Do not get me wrong posts/videos are by all means useful to get a general idea about the topic. Nonetheless, if you are working on a different situation it is better if you skim the docs, so you can tackle your problem with more adequate methods. Besides, by the time you are watching/reading the video tutorial/post things (versions) are very likely to be changed. So what I would suggest is going to what initially seems a hard way and read the documentary, rather than trying to cut the corners and ending up frustrated with wasted time.
Furthermore, if you need to insert scraped data into database in your local machine I would recommend you a real python article.
In the next part we will see how I pushed scrapper into Heroku Server and how to build a database there.
You can find the source code on my Git Hub page: https://github.com/Muxsidov/Scraper_Blog





Top comments (0)