If your GitOps deployment model has security issues (for example, a misconfigured permission because of a typo), this will be propagated until it is hopefully discovered at runtime, where most of the security events are scanned or found.

What if you can fix potential security issues in your infrastructure at the source?
Let's start with the basics.
What is Git?
Git is an open source distributed version control system. It tracks changes made in files (usually text files such as source code) allowing and fostering a collaborative work model. It is the de facto standard in version control systems nowadays.
You can have your own git repo locally on your laptop, host it on your own server, or use some provider such as GitLab or GitHub.
There are different “flows” on how to manage a repository (git-flow, github-flow, etc.), but a basic example on how git is used is something like this: Changes in the files are “committed” by users by “forking” the repository and doing the proper changes in a “branch”.
Then, the user creates a request (either "pull request", "merge request", or just "send a patch") to include those changes in the repository.
After that, usually a discussion happens between the “owner” and the user creating the request, and if everything goes fine the change is accepted and added to the repository.
NOTE: If you want to know more, here is much more detailed information about the git pull request mechanism.
To see a real world example, just browse your favorite open source GitLab or GitHub repository and browse the Pull Request (or Merge Request) tab (or see this for a fun one). You can see the proposed changes, comments, labels, who proposed the changes, tools running validations against the proposed changes, notifications sent to people watching the repository, etc.
What is GitOps?
To put it simply, GitOps is just a methodology that uses a git repository as the single source of truth for your software assets so you can leverage the git deployment model (pull requests, rollbacks, approvals, etc.) to your software.
There are books (The Path to GitOps, GitOps and Kubernetes or GitOps Cloud-native Continuous Deployment), whitepapers, and more blog posts than we can manage to count but let us elaborate on the GitOps purpose by taking a quick look on how things evolved in the last few years.
Before the cloud, adding a new server to host your application took weeks. You had to ask for permissions, purchase it, and perform a lot of manual tasks. Then, virtualization made things much easier. You request a virtual machine with some specs and after a few minutes, you have access to it.
Then, the cloud. Requesting servers, network, storage, and even databases, messaging queues, containers, machine learning stuff, serverless… is just an API call away! You request it and a few seconds later, you get it, just like that. You just need to pay for what you use. This also means the infrastructure can be managed as code performing API calls… and where do you store your code? In a git repository (or any other content version system).
The GitOps term was coined back in 2017 by Weaveworks, and paraphrasing OpenGitOps, a GitOps system is based on the following principles:
- Declarative: it defines “what.”
- Versioned and immutable: hence “git.”
- Pulled automatically: an agent observes the desired state and the changes happening in the code.
- Continuously reconciled: did someone mention Kubernetes?
The essence of the GitOps methodology is basically a Kubernetes controller or controllers (or agents) running on your cluster that observes the Kubernetes objects running on top of it (defined by a CustomResource) comparing the current state against the state specified in the Git repo. If it doesn't match, it remediates the application by applying the manifests found in the repository.
NOTE: There are slightly different approaches to GitOps, for example, push vs. pull, how to handle the configuration management, etc. Those are advanced topics, but for now, let's stick to the basics.
The following diagram shows a simplified GitOps system:
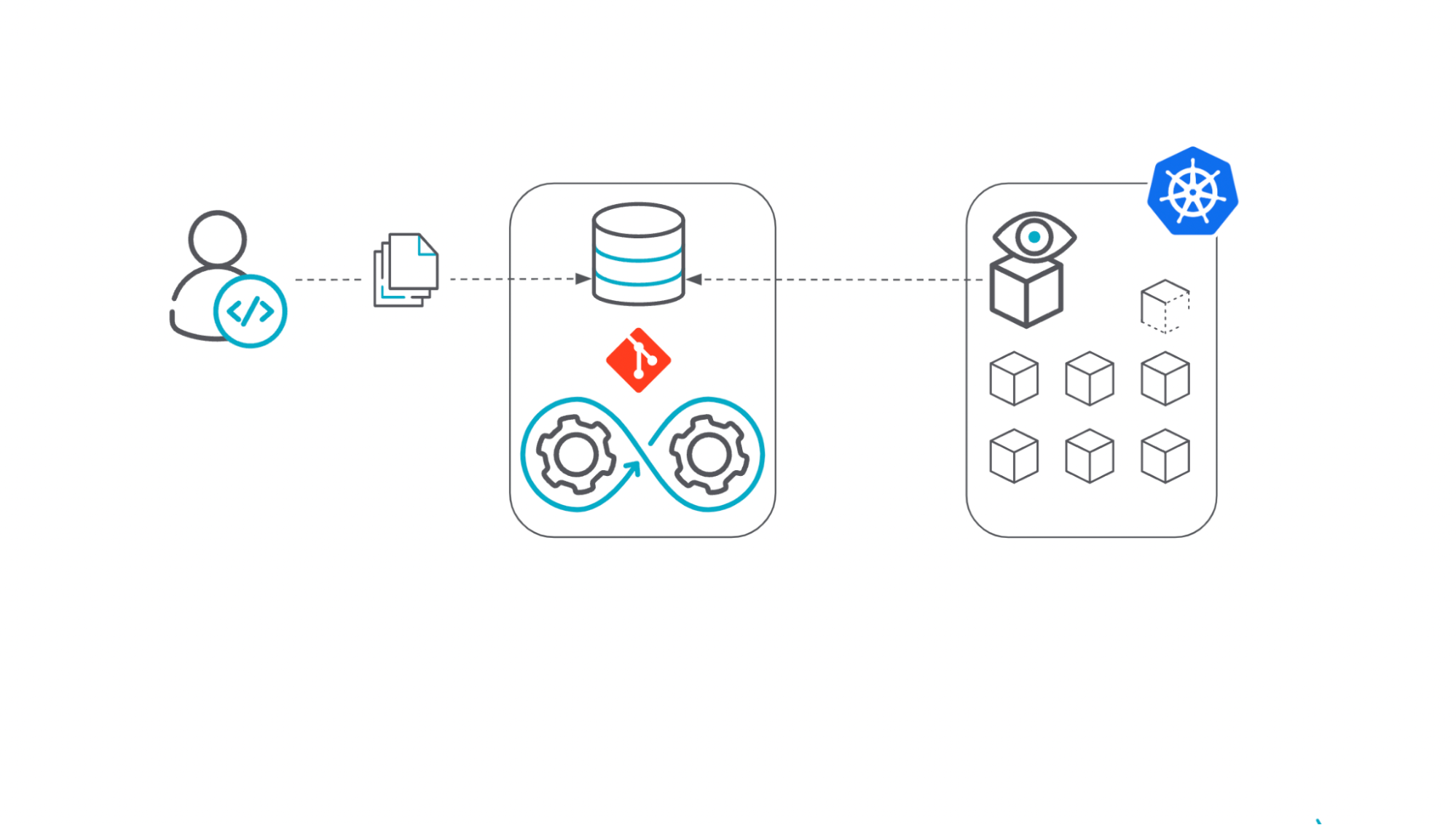
- A code change is submitted to the Git repository by the user.
- Then, a process is triggered on the repository to incorporate those changes into the application itself, including running automation tools against that new code to validate it.
- Once everything is in place, the GitOps agent running in the Kubernetes cluster, which is observing the repository, performs the reconciliation between the desired state (the code in the repository) and the current state (the objects running on the Kubernetes cluster itself).
Being based on Git means frictionless for developers. They don't need to worry about a new tool to interact with, but rather apply the same practices used to manage the code in the Git repository.
Speaking about GitOps tools, there are a few already available, including open source tools such as Flux or ArgoCD, both CNCF incubating projects.
To get a feeling on what an application definition looks like via GitOps, this is an example of a simple application (stored in a GitHub repository) managed by Flux or ArgoCD.
With Flux:
---
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: GitRepository
metadata:
name: my-example-app
namespace: hello-world
spec:
interval: 30s
ref:
branch: master
url: https://github.com/xxx/my-example-apps.git
---
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
metadata:
name: my-example-app
namespace: hello-world
spec:
interval: 5m0s
path: ./myapp
prune: true
sourceRef:
kind: GitRepository
name: my-example-app
targetNamespace: hello-world
With ArgoCD:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-example-app
namespace: hello-world
spec:
destination:
namespace: my-example-app
server: https://kubernetes.default.svc
project: default
source:
path: myapp/
repoURL: https://github.com/xxx/my-example-apps.git
targetRevision: HEAD
syncPolicy:
automated: {}
syncOptions:
- CreateNamespace=true
Both reference the Git repository where the application manifests are stored (Deployments), the NameSpaces, and a few more details.
GitOps vs. IaC
Infrastructure as Code is a methodology of treating the building blocks of your infrastructure as code using different techniques and tools. This means that instead of manually creating your infrastructure such as VMs, containers, networks, or storage via your favorite infrastructure provider web interface manually, you define them as code, and then those are created/updated/managed by the tools you choose, such as terraform, crossplane, or pulumi, among others.
The benefits are huge. You can manage your infrastructure as if it was code (it is code now) and leverage your development best practices (automation, testing, traceability, versioning control, etc.) to your infrastructure assets. In fact, there is a trend of using "Infrastructure as Software" as a term instead because it is much more than just code.
There is tons of information out there on this topic, but the following resource is a good starting point.
As you have probably figured, GitOps leverages Infrastructure as Code as the declarative model to define the infrastructure. In fact, IaC is one of the GitOps cornerstones! But it is much more as IaC doesn't mandate the rest of the GitOps principles.
GitOps vs. DevOps
There are lots of definitions of the "DevOps" term. It depends who you ask but to put it simply, "DevOps is the combination of practices and tools to build and deliver software reducing friction and to a high speed."
DevOps methodologies can leverage GitOps as GitOps provides a framework that matches DevOps practices but it is not strictly necessary.
What about NoOps?
NoOps was coined by Forrester in 2011 and it is a radical approach to handling operations where the IT environment is abstracted and automated to the point there is no need to manage it manually.
GitOps helps to reduce the manual changes by remediating those with the desired state in the Git repository, but applying a real NoOps to the whole IT environment is an aspirational goal rather than a real goal as of today.
Is GitOps just for Kubernetes?
No. Kubernetes, the controller pattern, and the declarative model to define Kubernetes objects are a perfect match for a GitOps methodology, but it doesn't mean GitOps methodologies cannot be applied without Kubernetes. There are a few challenges if using GitOps outside of Kubernetes, such as handling the idempotency, the deletion/creation of the assets, secrets managements, etc. But the GitOps principles can be applied without Kubernetes (and applying a little bit of creativity).
GitOps & Security
Let's talk about the security aspects now. Most security tools detect potential vulnerabilities and issues at runtime (too late). In order to fix them, either a reactive manual process needs to be performed (e.g., modifying directly a parameter in your k8s object with kubectl edit) or ideally, the fix will happen at source and will be propagated all along your supply chain. This is what is called “Shift Security Left”. From fixing the problem when it is too late to fixing it before it happens.
This doesn't mean every security issue can be fixed at the source, but adding a security layer directly at the source can prevent some issues.
First of all, the general security recommendations apply.
- Reduce the attack surface
- Encrypt the secrets (using External Secrets or Sealed Secrets)
- Network segmentation
- RBAC
- Keep software up to date
- Enforce least privilege
- Monitor & measure
- …
Let's see a few scenarios where the GitOps methodology can improve your security in general:
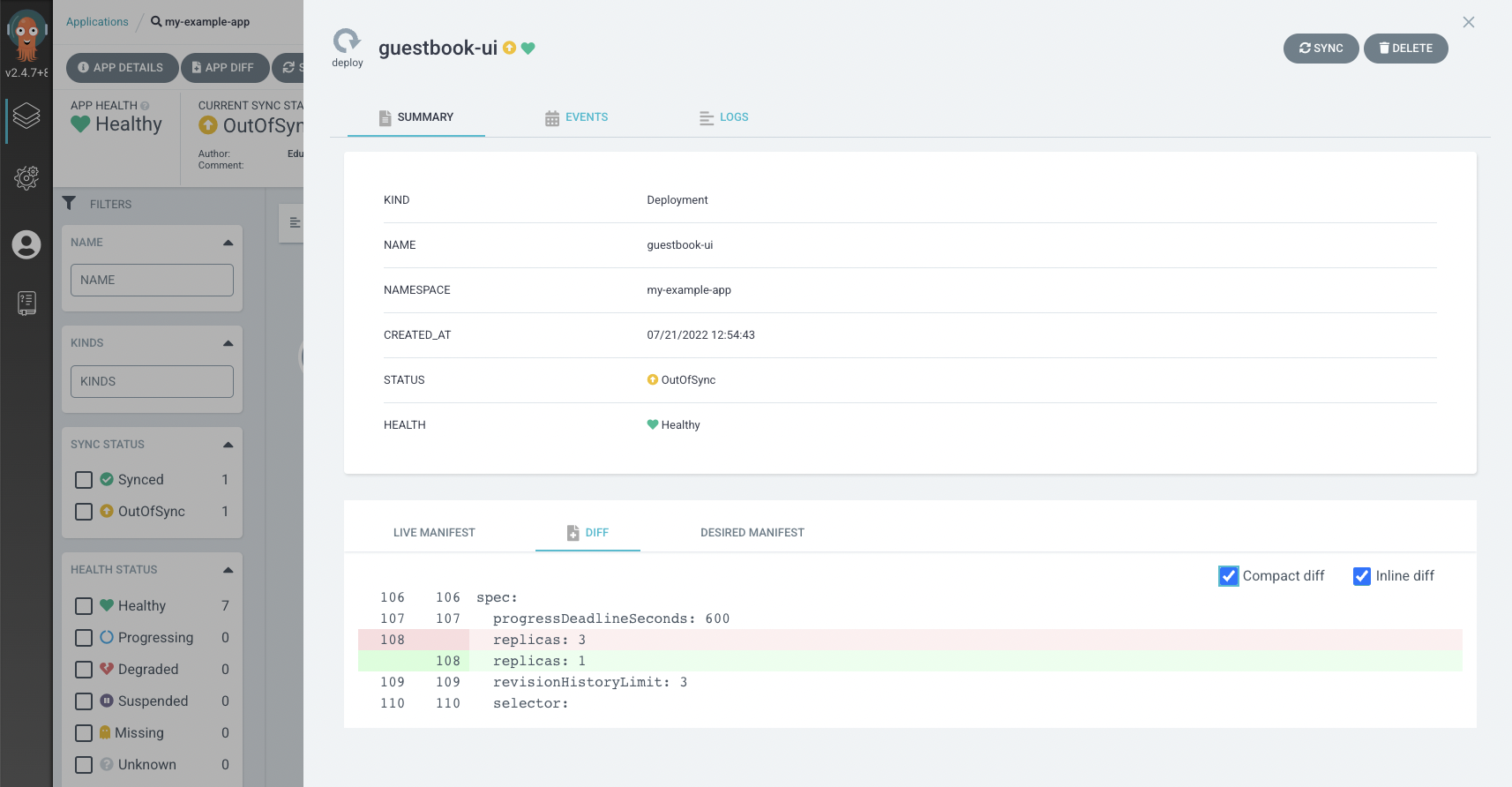
- Avoid/Refuse manual changes (avoiding Drift). The Git repository is the source of truth. If you try to modify the application definition, the GitOps tool will revert those changes by applying the version stored in the Git repository.

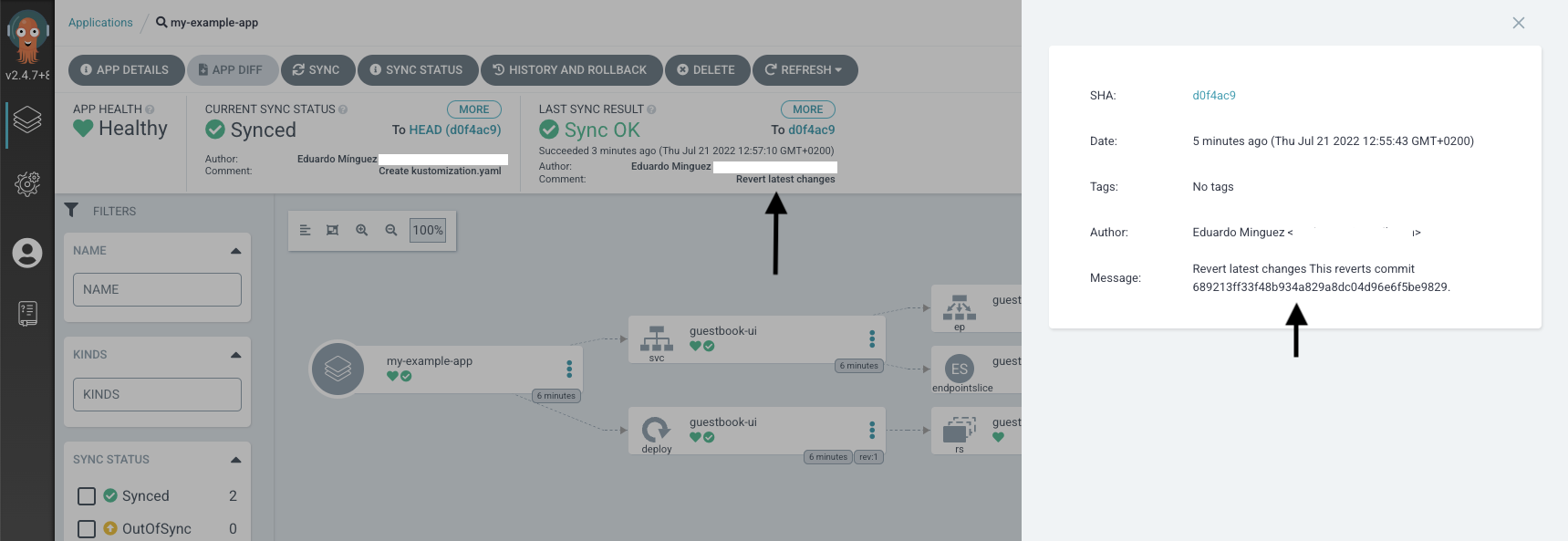
- Rollback changes. Imagine you introduced a potential security issue in a specific commit by modifying some parameter in your application deployment. Leveraging the Git capabilities, you can rollback the change if needed directly at the source and the GitOps tool will redeploy your application without user interaction.
- Fast response. If you find you are using a vulnerable container image in your application (e.g., MariaDB), you just need to create a PR to update the tag into the deployment file and the GitOps tool will use the new tag in a new deployment.
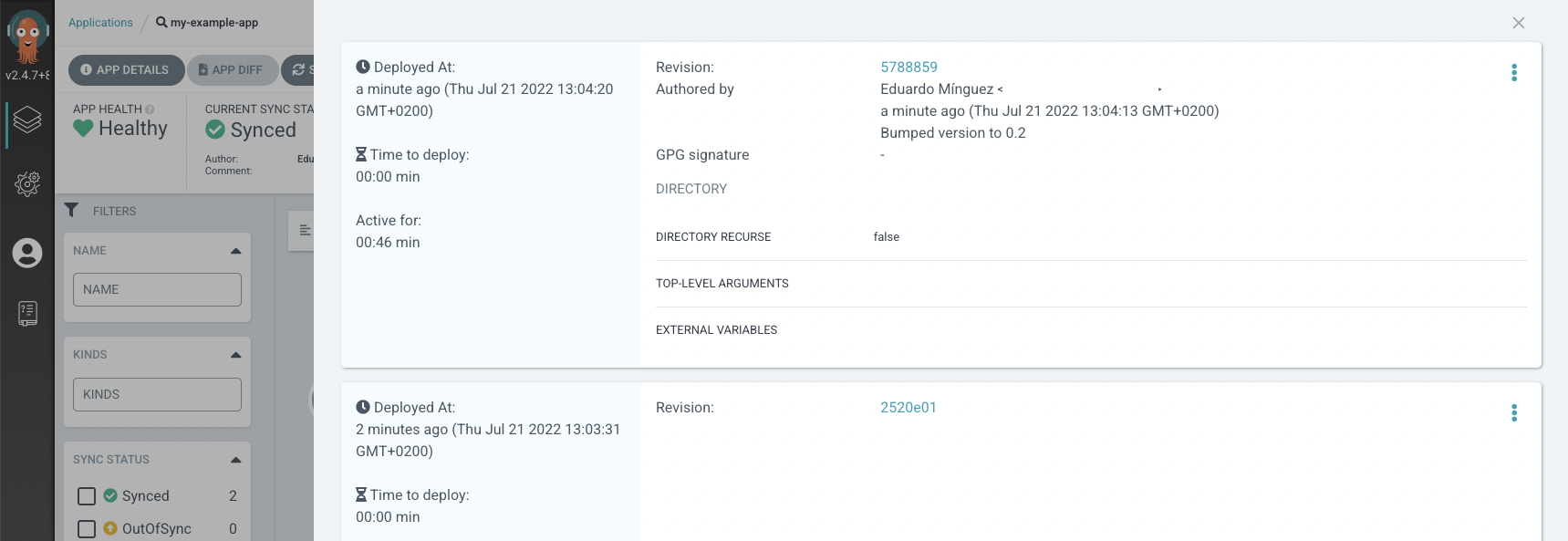
- Traceability. Using Git capabilities, you can easily check when a file was changed, the changes themselves and the user that promoted the changes. You've got an audit log for free.
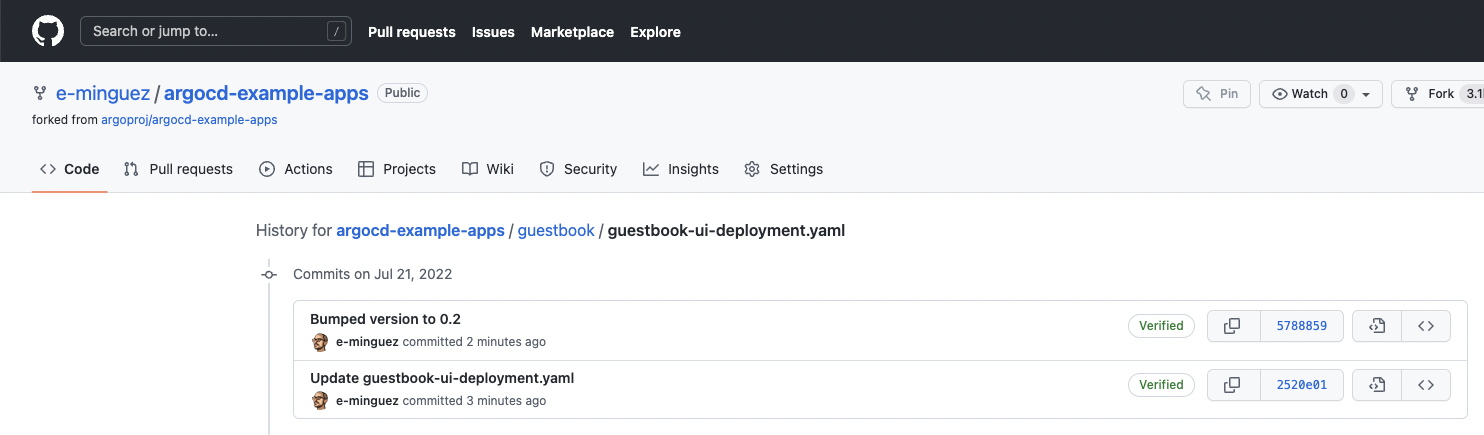
- Disaster recovery. Again, the Git repository is the source of truth. If you need to redeploy your application because something happened, the definition is there (of course you need to have a disaster recovery plan for other stuff such as the data itself).
- Access Control. You can apply different permissions to different users on your Git repositories and even policies such as “only merge a change after two positive reviews”.
Those benefits are good enough to justify using GitOps methodologies to improve your security posture and they came out of the box, but GitOps is a combination of a few more things. We can do much more. GitHub, GitLab, and other Git repositories providers allow you to run actions or pipelines based on the changes you perform in your Git repository, including by a pull request, so the possibilities are endless. A few examples:
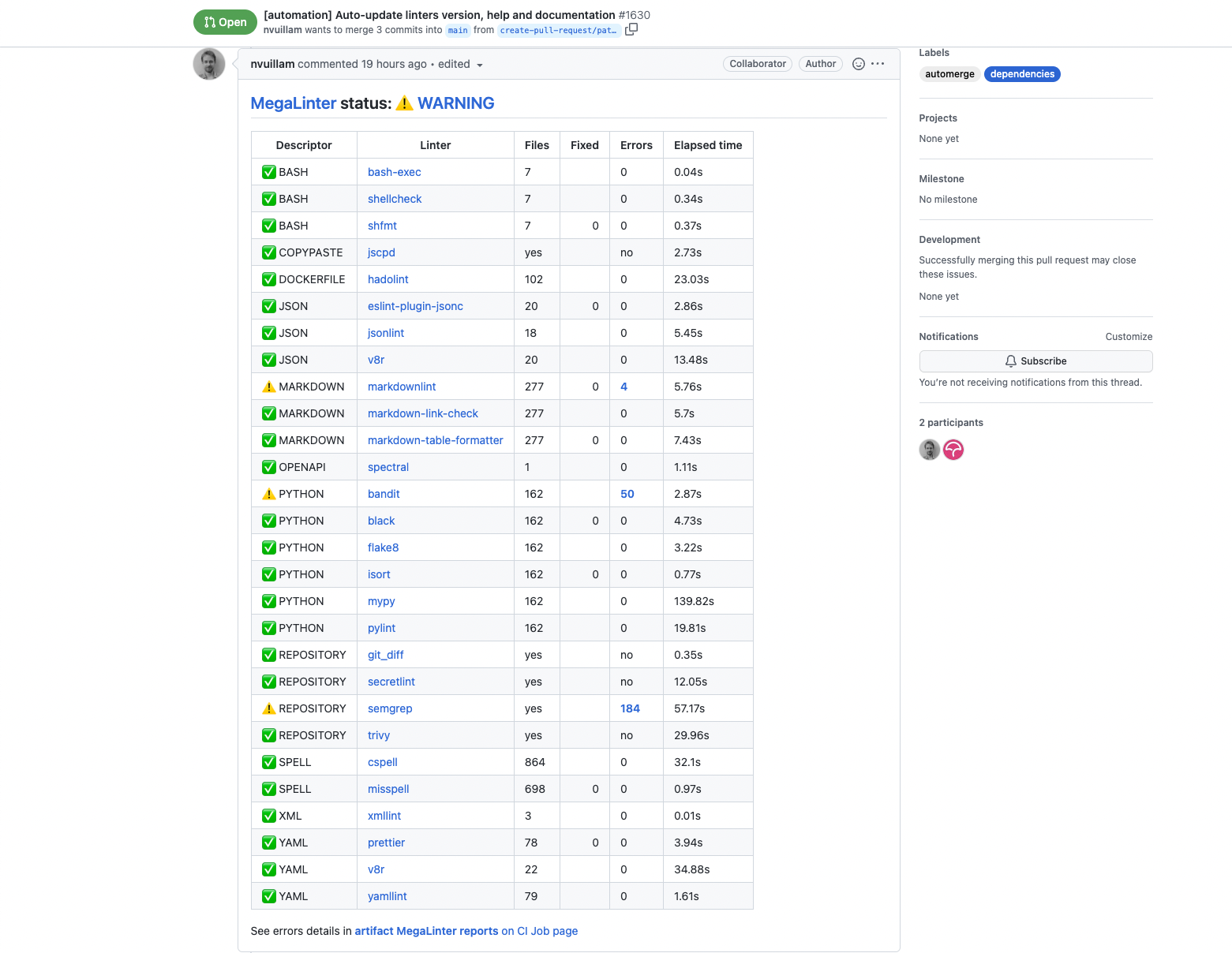
- Linting. The definition of the application is code, what if the definition is checked for wrong syntax, missing parameters, and more? There are tools (such as the megalinter) that can be executed against the changes you've performed so you avoid surprises later on.
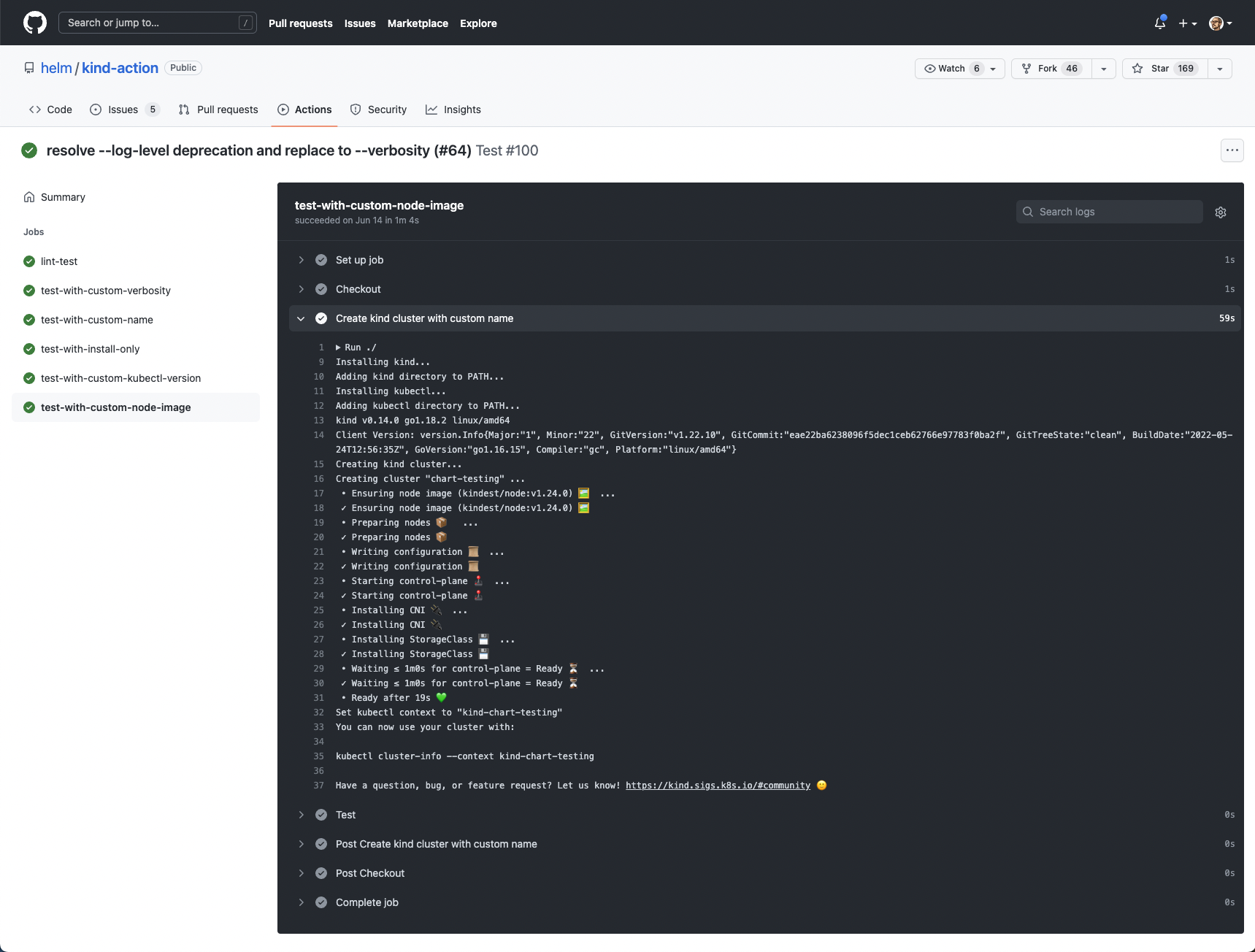
- Testing. You can even automate the creation of a temporary Kubernetes cluster to run your application with the changes and run some tests against it.
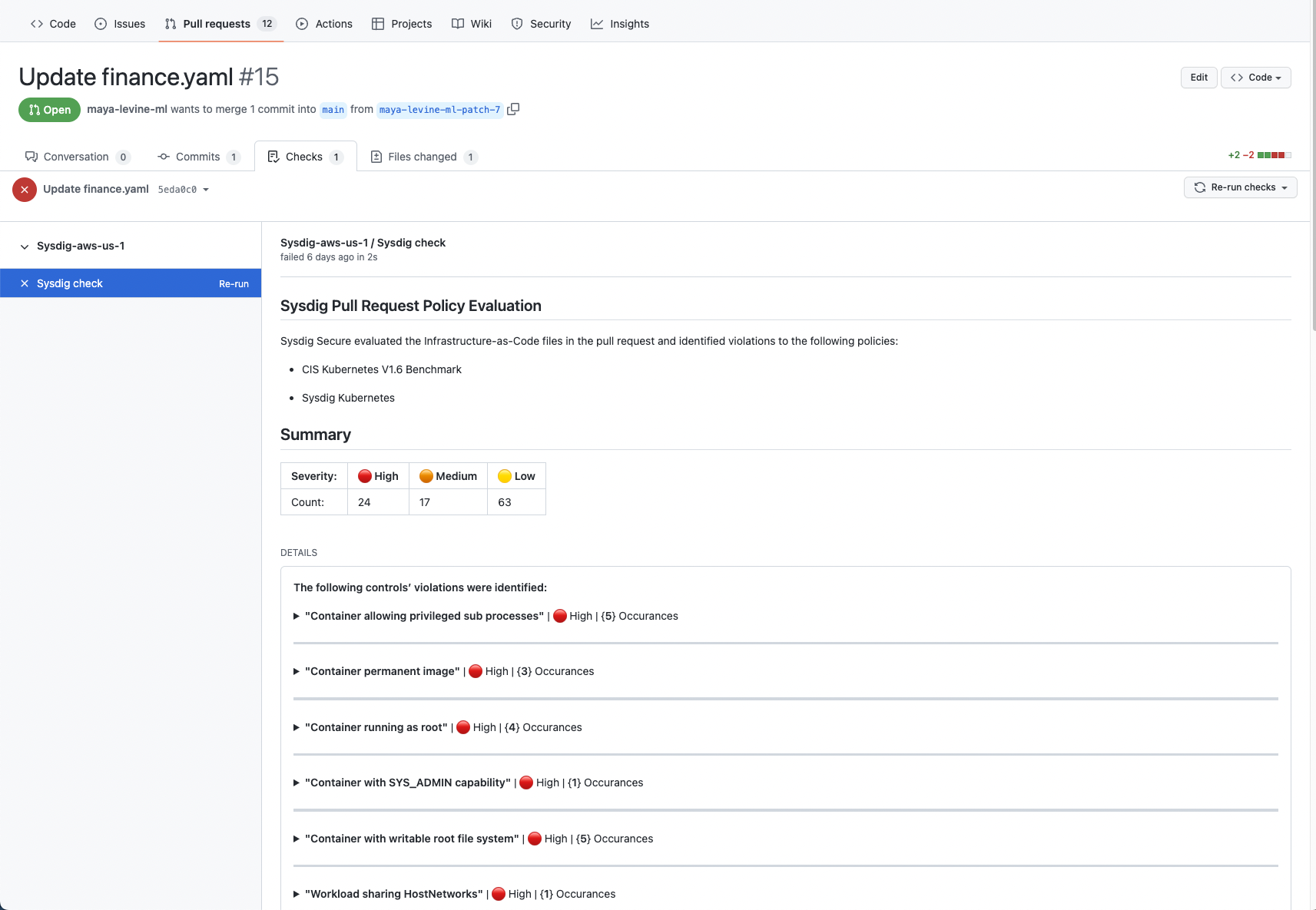
- Vulnerability scanning. By checking the container images you are using for vulnerabilities before they are deployed in your environment.
- Policy-as-code. Leveraging OPA, you can even apply policies to your manifests to check for potential issues or custom policies
Final thoughts
The GitOps methodology brings a few improvements to the deployment model and security benefits to the table without having to add another tool.
It improves the security posture by adding a “shift left” layer directly to the source code and thanks to the flexibility of the pull-request model, you can easily add extra security checks without affecting or modifying the runtime.

Top comments (0)