Intro
In the previous posts we covered the basics of how to handle Futures. We are now able to chain them, execute them and even create them. But, so far, our futures are not really delegating the execution to another thing. In Part 3 we cheated parking and immediately unparking the future. This trick allowed our future to progress but it was a poor example of real life future. Let's correct this with another, more fitting, example.
A timer future
The simplest future we can create is the timer (as we did in part 3). But this time, instead of unparking the future's task immediately we want to leave the task parked until it's ready to complete. How can we achieve this? The easiest way it to detach a thread. This thread will lay waiting for some time and then it will unpark our parked task.
This is a good simulation of what happens with asynchronous IO. We are notified when some data is available by another entity (generally the OS). Our thread - remember, for simplicity sake think about the reactor as single threaded - can perform other tasks while waiting to be notified.
Timer revised
Our stuct will be very simple. It will contain the expiration date and whether the fact the task is running or not:
pub struct WaitInAnotherThread {
end_time: DateTime<Utc>,
running: bool,
}
impl WaitInAnotherThread {
pub fn new(how_long: Duration) -> WaitInAnotherThread {
WaitInAnotherThread {
end_time: Utc::now() + how_long,
running: false,
}
}
}
The DateTime type and the Duration one are from the chronos crate.
Spin wait
To wait for the time we can use this code:
pub fn wait_spin(&self) {
while Utc::now() < self.end_time {}
println!("the time has come == {:?}!", self.end_time);
}
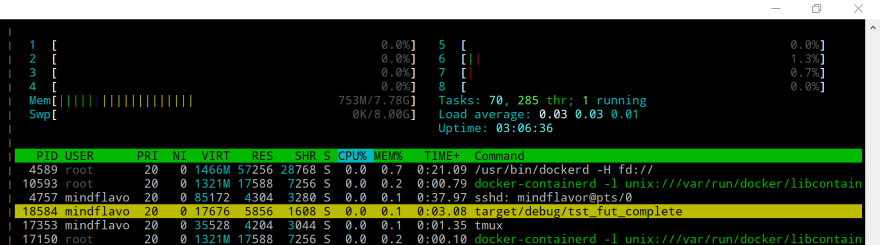
In this case we basically keep checking the current time against the expiration time. This works and it's also quite precise. The downside of this approach is we are wasting tons of CPU cycles. You can see it clearly if you look at the process utilization:
fn main() {
let wiat = WaitInAnotherThread::new(Duration::seconds(30));
println!("wait spin started");
wiat.wait_spin();
println!("wait spin completed");
}

In my case the core 8 is completely used by our code. This is similar of what we experienced in part 3.
Spin waits are very accurate but wasteful. Use them for very short waits only or when you do not have alternatives.
Sleep wait
OSs are able to park your thread for a specific amount of time. This is often called sleep. Sleeping a thread basically tells ths OS: "do not schedule my thread for X seconds". So the OS if free to use the available resources for something else (either another thread of your process of another process altogether). Rust supports this using the std::thread::sleep() function. Our code can be:
pub fn wait_blocking(&self) {
while Utc::now() < self.end_time {
let delta_sec = self.end_time.timestamp() - Utc::now().timestamp();
if delta_sec > 0 {
thread::sleep(::std::time::Duration::from_secs(delta_sec as u64));
}
}
println!("the time has come == {:?}!", self.end_time);
}
Here we try to determine how long the thread should sleep subtracting the expiration time from current time. Since the timestamp() function is not precise we loop as before. Let's try it:
let wiat = WaitInAnotherThread::new(Duration::seconds(30));
println!("wait blocking started");
wiat.wait_blocking();
println!("wait blocking completed");
The behavior will be the same except, this time, our process will not use any CPU at all:
Way better. But is it a Future?
Future
No, it isn't. We haven't implemented the Future trait. So let's do this. Our first, naive approach could be:
impl Future for WaitInAnotherThread {
type Item = ();
type Error = Box<Error>;
fn poll(&mut self) -> Poll<Self::Item, Self::Error> {
while Utc::now() < self.end_time {
let delta_sec = self.end_time.timestamp() - Utc::now().timestamp();
if delta_sec > 0 {
thread::sleep(::std::time::Duration::from_secs(delta_sec as u64));
}
}
println!("the time has come == {:?}!", self.end_time);
Ok(Async::Ready(())
}
While this method would not waste CPU cycles it will block the reactor. A blocked reactor does not advance the other futures. Which is bad.
Futures should block as little as possible.
In order to be a good reactor citizen we need to:
- Park our task when it's waiting for the expiration time.
- Do not block the current thread.
- Signal the reactor when the task is completed (expiration time).
What we will do is to create another sleeping thread. This thread will not consume resources because we will put it to sleep. Being in a separate thread the reactor will keep working happily. When the separate thread wakes (after the sleeping time) it will unpark the task, signaling the reactor.
Let's sketch an implementation first and then walk through it:
impl Future for WaitInAnotherThread {
type Item = ();
type Error = Box<Error>;
fn poll(&mut self) -> Poll<Self::Item, Self::Error> {
if Utc::now() < self.end_time {
println!("not ready yet! parking the task.");
if !self.running {
println!("side thread not running! starting now!");
self.run(task::current());
self.running = true;
}
Ok(Async::NotReady)
} else {
println!("ready! the task will complete.");
Ok(Async::Ready(()))
}
}
}
We need to kick off the parallel thread only once so we use the running field for that. Notice that our execution won't start until the future is polled. This is perfectly fine for our purposes. Also we check if the expiration time is already in the past in which case we do not spawn the side thread at all (we will see the run function in a moment).
If the expiration time is in the future and there is no side thread running we spawn it. We then ask to park our task returning Ok(Async::NotReady). Contrarily to what we did in part 3 we do not unpark the task here. That's responsibility of the side thread. In other implementations, such as IO, it would be an OS responsibility to wake our task.
The side thread code is this one:
fn run(&mut self, task: task::Task) {
let lend = self.end_time;
thread::spawn(move || {
while Utc::now() < lend {
let delta_sec = lend.timestamp() - Utc::now().timestamp();
if delta_sec > 0 {
thread::sleep(::std::time::Duration::from_secs(delta_sec as u64));
}
task.notify();
}
println!("the time has come == {:?}!", lend);
});
}
Two things to note here. First we pass to the parallel thread the task reference. This is important because we cannot resort to Task::current() in a separate thread. Secondly, we do not move self into the closure: that's why we bind lend to a self.end_time copy. Why is that? Threads in Rust require the Send trait with the 'static lifetime. the Task complies to both so we can move it into the closure. Our struct does not so we move a copy of the end_time field instead.
This means that you cannot change the expiration time after the thread has been started.
Let's give it a try:
fn main() {
let mut reactor = Core::new().unwrap();
let wiat = WaitInAnotherThread::new(Duration::seconds(3));
println!("wait future started");
let ret = reactor.run(wiat).unwrap();
println!("wait future completed. ret == {:?}", ret);
}
This is the output:
Finished dev [unoptimized + debuginfo] target(s) in 0.96 secs
Running `target/debug/tst_fut_complete`
wait future started
not ready yet! parking the task.
side thread not running! starting now!
the time has come == 2017-11-21T12:55:23.397862771Z!
ready! the task will complete.
wait future completed. ret == ()
Notice the temporal flow of events:
- We ask the
rectorto start our future - Our
futurenotices the expiration date is in the future so:- Parks the
task - Starts the side thread
- Parks the
- The side thread awakens after some time and:
- Notifies the
reactorthat thetaskshould be unparked - Destroys the side thread (quits)
- Notifies the
- The
reactorawakens the parkedtask - The
future(akatask) completes and:- Signals the
reactorthat it has completed - Returns the output value (unit in our case)
- Signals the
- The reactor return the output value of the
taskto the caller of therunfunction.
Pretty neat, don't you think?
Conclusion
This completes our "real life" future. It does not block so it behaves correctly in a reactor. It does not use unnecessary resources. It also does not do anything useful on its own (besides being used as timeout mechanism, can you imagine how?).
Of course you generally do not write a future manually. You use the ones provided by libraries and compose them as needed. It's important to understand how they work nevertheless.
The next topic will be the Streams which will allow to create Iterators that yield the values one at the time not blocking the reactor while doing so.
Happy Coding
Francesco Cogno

Top comments (4)
Thanks for writing this tutorial. I'm wondering about something though. Creating a separate thread for unparking seems like killing the point of futures all together. I might as well store my result in a cross-thread variable as an option and check from time to time whether it has Some(xxx) or None.
What seems appropriate is since the future is say calculating something, or querying a db, anyways it's running code, it should probably unpark the future when it's done. That way you have no overhead and no latency. However in that case why poll (even though futures doesn't actually poll). In other words why even have a poll method if you can replace it with an event. Maybe it's just a misnomer, but if you unpark why not pass the result of the future to it at once, saving the call to poll.
Maybe I'm just confused and I missed something fundamental, but I have an allergy to polling anyway.
Yes of course you are right! This is a contrived example, I'm just using a separate thread to simulate an "external event coming to completion". you are not supposed to do this in reality (as you point correctly this will defeat the purpose of having a future :) ).
Exactly! Futures are great when waiting for an "external resource". You can block your thread waiting for it to complete or do something else. Apologies if the example above is misleading, I just wanted to simulate a "external blocking resource" and I thought a sleeping thread would be simple to understand.
Rust futures support both approaches. If the "external resource" can raise an event upon completion (or progress) you can definitely use the event route. Just park the task and let the completion event unpark the task (as we did above).
If not you can poll the "external resource".
This difference is visible only to the crate implementer. The user consuming the future does not need to care about it. It's just a future: he can chain, join, etc... it regardless of it being "event based" or "polling based". It will work.
That made me laugh :D!
Ok, thanks. That clarifies some things. If I get it right to fully benefit from the async any external resource still has to support async as well, since otherwise some thread will still have to block (eg. if I use the file system api in std?). And any computational work is best put in separate threads to benefit of concurrency.
I write this because the Alex Crichton tutorial starts out by making a point that you don't need so much multithreading when using async which is true to some extend, but also a bit confusing if you just try to understand how to fit it all together.
When I tried to understand how to use hyper, I run into stuff like this. It did help me because it seems like the example with least boilerplate (and showing how to use futures-await with hyper), but it makes all methods async even though they're all running in the same thread. If I understand it well, this will just give more overhead and no benefit at all. As far as I can tell, futures-await does not make your code multithreaded. Am I getting it right?
ps: I found the explanation of how futures get unparked here: tokio.rs/docs/going-deeper-futures...
Yes. In general, OS offer some support to async IO and leave to devs to optimize CPU bound tasks via, for example, thread pools. Take a look at this pages Synchronous and Asynchronous I/O and I/O Completion Ports: they show how Windows offers async IO to its devs.
I felt the same way. Is not that Alex's tutorial is bad. It's actually very, very good. But it many things for granted meaning mortal developers such as myself have an hard time following it. That's why I wrote this tutorial in the first place. I hope it helps someone :)
TL;DR
Futures are more efficient than threads.
Long answer
The whole point of futures is to multiplex more tasks in a single thread. In the case of Hyper web server it allows you to handle multiple connections concurrently in the same thread. While one task is sending data to the network, for example, you can prepare the next answer (in the same thread).
You can have the same effect using multiple threads of course (the classic educational approach: "listen to a port, accept a connection, fork the process to handle the connection") but it's less efficient.
Threads are expensive to create (both in terms of CPU and memory) so with many short lived connections (such as HTTP) spawning a thread for each connection is terrible: you end up waiting more for the thread creation than everything else. Also threads make it very hard to surface errors/exceptions (Rust here helps, to an extent). Generally speaking, resource cleanup in threads is hard.
You could have avoided the thread generation cost using thread pools but the burden of managing it would be on your shoulders. Hence the futures. Futures are a convenient way of hiding the complexity of multiplexing tasks in a single/few thread(s).
Alex's futures are particularly elegant because, off the top of my head:
Resultmovein closuresTo make my point look at the performance of tokio-minihttp (a minimal webserver based on futures) compared to hyper: