This tutorial describes the steps required to create a custom document data extraction API using Mindee.
Over the course of this tutorial, you will learn how to train a deep learning model that can parse and extract the data of your choice in your documents.
Once the ML model is trained, you will be able to use the custom REST API backed by that model in your application code using the language of your choice.
Let’s see how to build and deploy your first document data extraction REST API using the following, fictitious scenario: as a developer, you want to extract the name of any burger food store that delivers orders to your door, along with its address, average user rating, user votes count as well as its first menu item name and price.
Set up your API
Prerequisites
- You will need a free beta account. Sign up and confirm your email address before proceeding.
- Download this data model configuration file.
- Download this sample training set.
Once you have signed up and logged in at https://beta.mindee.net, press the I’m ready, start building button, as shown below:

First, we need some basic information about your new, custom document scanning API. That info will help us highlight your API in your Mindee API Hub (and in other users’ API Hubs if you choose to share your API with them). The requested properties are:
- Document type: The common name of the document type your API will be trained on. Examples: 1040 US Tax Form, Pay Stub, Bank Statement
-
API name: The resource name of your API URL.
We automatically generate one for you based on your document type but you can customize it at your own convenience. Note however that you can’t use special or accented characters. The format of your API URL complies with the following scheme:
https://api-beta.mindee.net/[username]/[API_name] - Description: An optional, short blurb aimed at conveying the purpose of the API. This description will appear below the image in your API Hub (and others if you choose to share your API with other users). We suggest you make it as clear and concise as possible to maximize its effectiveness.
- Image: An uploaded image that appropriately illustrates your API. Other users may see it in their API Hub if you choose to share it with them.
Here is a possible configuration for our first burger stores API:

Fill out the form with the following values (or pick your own):
- Document type: Burger Stores and Menus
- API Name: burger_stores
- Description: An API used to extract data (such as store name, ratings and address) from popular burger stores
- Image: upload this image
Once you’re done setting up your API, press the Next step: define your data model button to create the list of fields we’d like to extract from our burger stores documents.
Define your document data model
The following page shows up:
![]()
You can either manually add each field or upload a json-formatted file, typically generated from an existing data model someone previously built (and exported).
The following information is required for each field:
- Field name: The legible field name used in your API documentation
- Api response key: The field key available in your API response to carry the extracted field value for each document
- Field type: The data type of the field you are trying to extract. The supported data types currently are: strings, numbers, dates, email addresses, phone numbers and URLs. Specifying a field type helps our deep learning selector better understand the data you’re looking for by restricting the number of potential candidates for each field. Learn more about the data types we support.
For the purpose of this tutorial, we want to extract the following information from our image or PDF documents:
- The burger store name (a string)
- The burger store address (a string)
- The store average user rating (a floating number)
- The votes count number (an integer)
- The name of the first item on the menu (a string)
- The price of the first item (an amount)
Below is a screenshot of one of our training files with each field above highlighted in green:

The Mindee representation of these fields after setting them up one by one is the following:

You can manually add them one by one or you can upload a configuration file to automatically populate your data model (this file is typically generated using the Config Export feature available to existing models in the Settings section of your API dashboard).
Press the Choose file button to upload the json-formatted config file (the one mentioned in the Prerequisites section above):

Once you’re done setting up your data model, press the Data model ready? start training button at the top of the screen:

Train the model
Now is the time to train our Burger Stores deep learning model in the Training section of our API:
![]()
For each of our documents we must assign a value to each field by selecting a box (or several consecutive boxes) displayed in the uploaded document. The Mindee selector highlights all the potential candidates for each field in blue, as shown below:

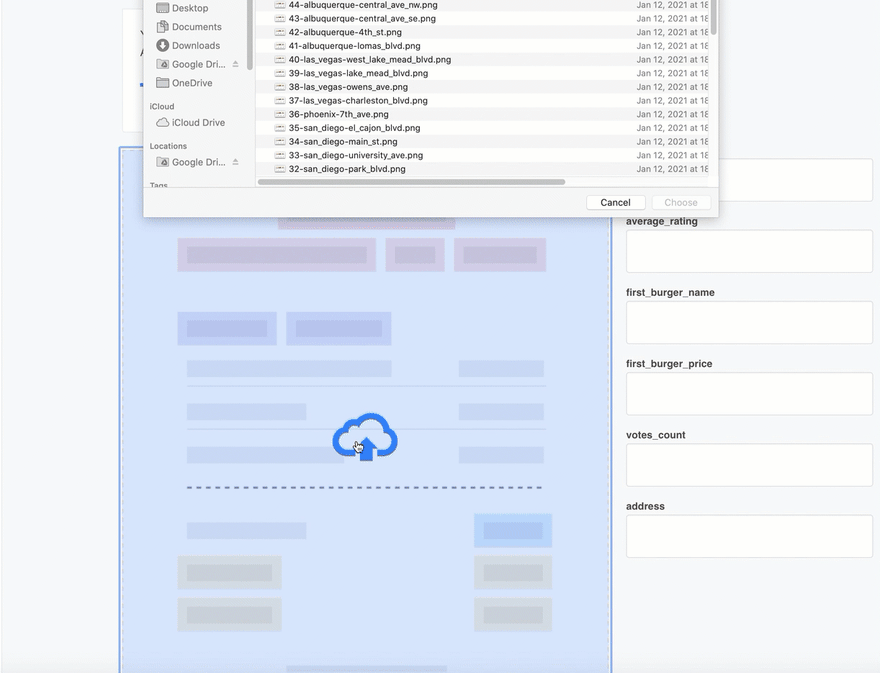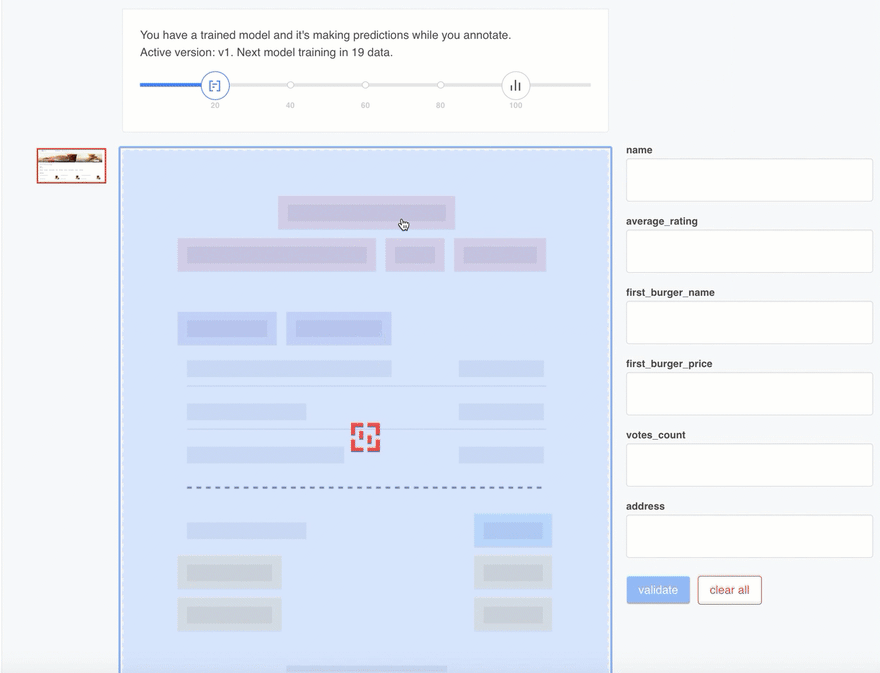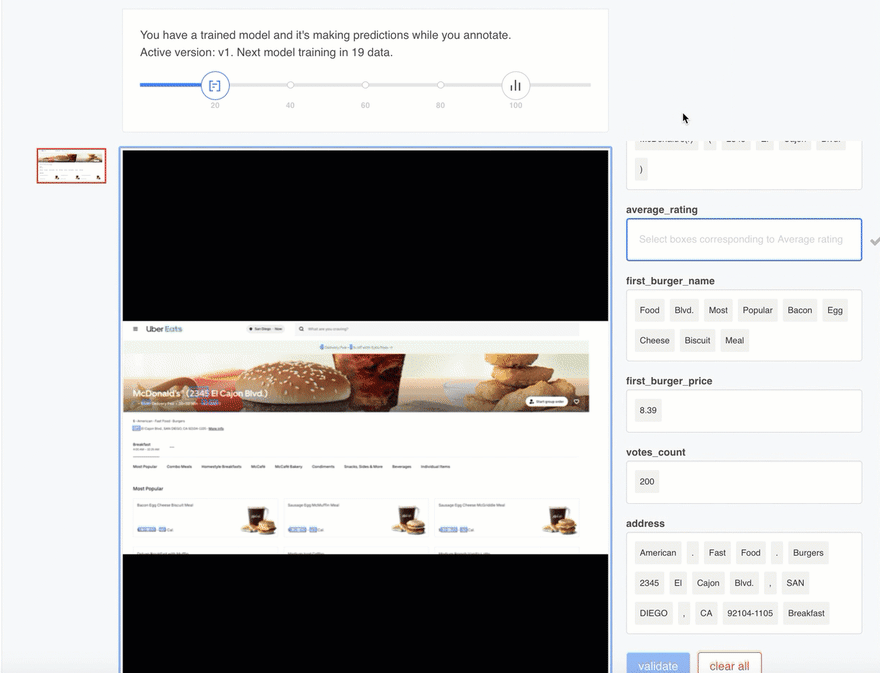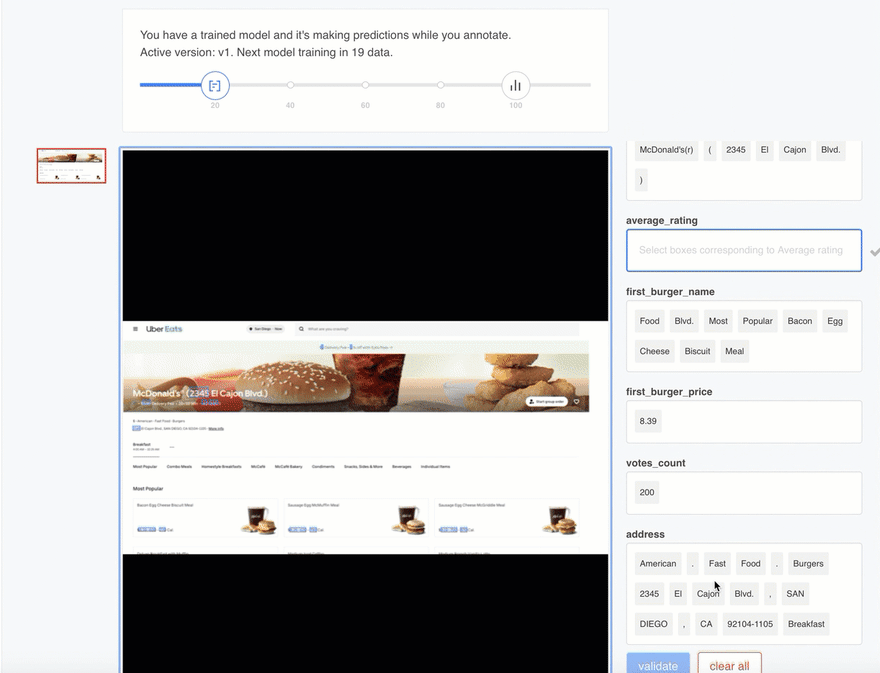
When you find the blue box that matches the field you are looking for, simply click that box. This populates the field text box with the selected value and shows the selected box in an identifiable color. For instance, the screenshot below highlights the box we selected for the average_rating field in orange:

If the content you are looking for is composed of more than one box, simply select all the consecutive boxes that match your field (non-consecutive boxes may result in an inefficient model). For example, he screenshot below shows the address field populated with 9 consecutive boxes:

You can download this sample dataset to train your Burger Stores deep learning model. Unzip the file into a folder and upload each file in that folder one-by-one to the Training page.
Once you have selected the proper box(es) for each of your fields (as displayed on the right-hand side of the document), press the validate button and repeat the tagging process for the next document.
The progress bar above each picture indicates the advancement of your tagging efforts and identifies the milestones at which a new model is generated.
Every 20 documents, a new model is being trained and automatically deployed into your API environment. You will receive an email whenever your latest model has been trained and is up and running:

Note that the more documents you feed into your model, the more accurate it will be.
With that being said, we will generate the first version of your trained model once you reach the 20 documents threshold (uploaded and validated).
At this point, you can experience the true power of the Mindee data extraction engine every time you upload a new training file, as the model will start filling out the fields on the right-hand side with the most likely values it was able to identify in the uploaded file.
From now on, the Burger Stores model will help you annotate new data in the Training section:
With a 20-documents training set, the model algorithm starts working pretty well on most fields, but still makes a few mistakes on the complex fields, such as the address field (extra words are predicted).
Once again, the more data you’re feeding to the model, the more accurate your API will get. So your job will now consists in correcting your model until you reach the next 20 documents threshold, which will kick off the generation of a new, more efficient model. You may repeat this task as often as you want.
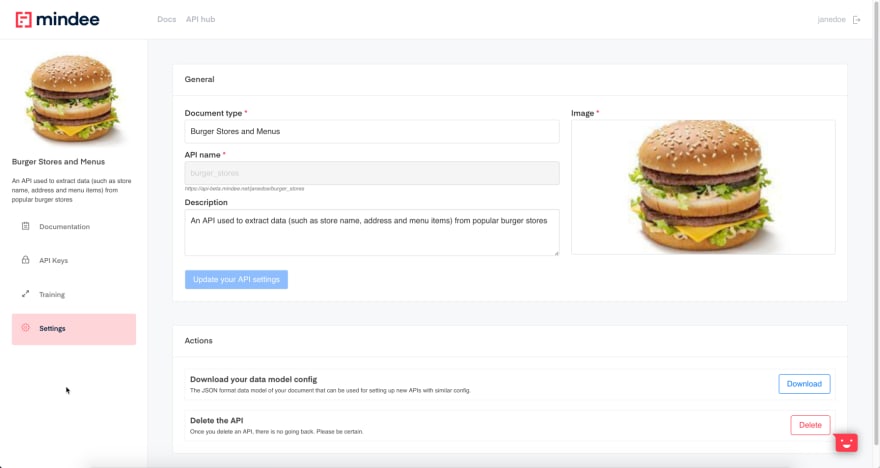
Settings, API keys and documentation
If you select the Documentation tab, the following page is displayed:

This page allows you to explore your API endpoints and download your API definition as an OpenAPI-formatted file.
The API Keys tab allows you to create and manage your custom API tokens:

The Settings tab allows you to update general information about your API such as its name or its description. It also allows you to download your data model field configuration, which can be used to create a new, enhanced data model without having to start from scratch.
That’s it! You should now be able to set up a real world use case now and build whichever document parsing API you may need.
If you have any questions or feedback about this tutorial, feel free to reach out to us in the #tutorials channel of the Mindee Community on Slack (the Get Started email you have received when signing up contains an invitation to join it).

{kind=link}
Top comments (0)