
Twitter Data Pipeline with Apache Airflow + MinIO (S3 compatible Object Storage)
The more that you read, the more things you will know. The more that you learn, the more places you’ll go.
Dr. Seuss
Motivation
During my journey as a Data Engineer, I stumbled upon many tools.
One that caught my attention is MinIO, a Multi-cloud Object Storage that is AWS s3 Compatible.
To learn more about it, I built a Data Pipeline that uses Apache Airflow to pull Elon Musk tweets using the Twitter API and store the result in a CSV stored in a MinIO (OSS alternative to AWS s3) Object Storage bucket.
Then, we’ll use Docker-Compose to easily deploy our code.
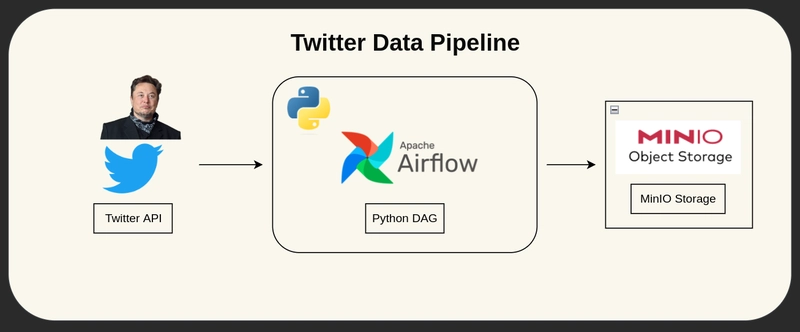
Table of Content
- What is Apache Airflow?
- What is MinIO ?
- Code
- get_twitter_data()
- dump_data_to_bucket()
- DAG (Direct Acyclic Graph)
- docker-compose & .env files
What is Apache Airflow
Airflow is a platform created by the community to programmatically author, schedule and monitor workflows.
Apache Airflow is an opensource workflow orchestration written in Python. It uses DAG (Direct Acyclic Graphs) to represent workflows. It is highly customizable/flexible and have a quite active community.
You can read more here.
What is MinIO
MinIO offers high-performance, S3 compatible object storage.
MinIO is an opensource Multi-cloud Object Storage and fully compatible with AWS s3. With MinIO you can host your own on-premises or cloud Object Storage.
You can read more here.
Code
The full code can be accessed.
Source code:
https://github.com/mikekenneth/airflow_minio_twitter_data_pipeline
get_twitter_data()
Below is the python Task that pulls Elon’s tweets from Twitter API into a python list:
import os
import json
import requests
from airflow.decorators import dag, task
@task
def get_twitter_data():
TWITTER_BEARER_TOKEN = os.getenv("TWITTER_BEARER_TOKEN")
# Get tweets using Twitter API v2 & Bearer Token
BASE_URL = "https://api.twitter.com/2/tweets/search/recent"
USERNAME = "elonmusk"
FIELDS = {"created_at", "lang", "attachments", "public_metrics", "text", "author_id"}
url = f"{BASE_URL}?query=from:{USERNAME}&tweet.fields={','.join(FIELDS)}&expansions=author_id&max_results=50"
response = requests.get(url=url, headers={"Authorization": f"Bearer {TWITTER_BEARER_TOKEN}"})
response = json.loads(response.content)
data = response["data"]
includes = response["includes"]
# Refine tweets data
tweet_list = []
for tweet in data:
refined_tweet = {
"tweet_id": tweet["id"],
"username": includes["users"][0]["username"], # Get username from the included data
"user_id": tweet["author_id"],
"text": tweet["text"],
"like_count": tweet["public_metrics"]["like_count"],
"retweet_count": tweet["public_metrics"]["retweet_count"],
"created_at": tweet["created_at"],
}
tweet_list.append(refined_tweet)
return tweet_list
dump_data_to_bucket()
Below is the python Task that transforms the tweets list into a Pandas dataframe, then dumps it in our MinIO Object Storage as a CSV file:
import os
from airflow.decorators import dag, task
@task
def dump_data_to_bucket(tweet_list: list):
import pandas as pd
from minio import Minio
from io import BytesIO
MINIO_BUCKET_NAME = os.getenv("MINIO_BUCKET_NAME")
MINIO_ROOT_USER = os.getenv("MINIO_ROOT_USER")
MINIO_ROOT_PASSWORD = os.getenv("MINIO_ROOT_PASSWORD")
df = pd.DataFrame(tweet_list)
csv = df.to_csv(index=False).encode("utf-8")
client = Minio("minio:9000", access_key=MINIO_ROOT_USER, secret_key=MINIO_ROOT_PASSWORD, secure=False)
# Make MINIO_BUCKET_NAME if not exist.
found = client.bucket_exists(MINIO_BUCKET_NAME)
if not found:
client.make_bucket(MINIO_BUCKET_NAME)
else:
print(f"Bucket '{MINIO_BUCKET_NAME}' already exists!")
# Put csv data in the bucket
client.put_object(
"airflow-bucket", "twitter_elon_musk.csv", data=BytesIO(csv), length=len(csv), content_type="application/csv"
)
DAG (Direct Acyclic Graph)
Below is the DAG itself that allows specifying the dependencies between tasks:
from datetime import datetime
from airflow.decorators import dag, task
@dag(
schedule="0 */2 * * *",
start_date=datetime(2022, 12, 26),
catchup=False,
tags=["twitter", "etl"],
)
def twitter_etl():
dump_data_to_bucket(get_twitter_data())
twitter_etl()
docker-compose & .env files
Below is the .env file that we need to create that hold the environmental variables needed to run our pipeline:
You can read this to learn our to generate the
TWITTER_BEARER_TOKEN.
# Twitter (Must not be empty)
TWITTER_BEARER_TOKEN=""
# Meta-Database
POSTGRES_USER=airflow
POSTGRES_PASSWORD=airflow
POSTGRES_DB=airflow
# Airflow Core
AIRFLOW__CORE__FERNET_KEY=''
AIRFLOW__CORE__EXECUTOR=LocalExecutor
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION=True
AIRFLOW__CORE__LOAD_EXAMPLES=False
AIRFLOW_UID=50000
AIRFLOW_GID=0
# Backend DB
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN=postgresql+psycopg2://airflow:airflow@postgres/airflow
AIRFLOW__DATABASE__LOAD_DEFAULT_CONNECTIONS=False
# Airflow Init
_AIRFLOW_DB_UPGRADE=True
_AIRFLOW_WWW_USER_CREATE=True
_AIRFLOW_WWW_USER_USERNAME=airflow
_AIRFLOW_WWW_USER_PASSWORD=airflow
_PIP_ADDITIONAL_REQUIREMENTS= "minio pandas requests"
# Minio
MINIO_ROOT_USER=minio_user
MINIO_ROOT_PASSWORD=minio_password123
MINIO_BUCKET_NAME='airflow-bucket'
And below is the docker-compose.yaml file that allow to spin up the needed infrastructure for our pipeline:
version: '3.4'
x-common:
&common
image: apache/airflow:2.5.0
user: "${AIRFLOW_UID}:0"
env_file:
- .env
volumes:
- ./app/dags:/opt/airflow/dags
- ./app/logs:/opt/airflow/logs
x-depends-on:
&depends-on
depends_on:
postgres:
condition: service_healthy
airflow-init:
condition: service_completed_successfully
services:
minio:
image: minio/minio:latest
ports:
- '9000:9000'
- '9090:9090'
volumes:
- './minio_data:/data'
env_file:
- .env
command: server --console-address ":9090" /data
postgres:
image: postgres:13
container_name: postgres
ports:
- "5433:5432"
healthcheck:
test: [ "CMD", "pg_isready", "-U", "airflow" ]
interval: 5s
retries: 5
env_file:
- .env
scheduler:
<<: *common
<<: *depends-on
container_name: airflow-scheduler
command: scheduler
restart: on-failure
ports:
- "8793:8793"
webserver:
<<: *common
<<: *depends-on
container_name: airflow-webserver
restart: always
command: webserver
ports:
- "8080:8080"
healthcheck:
test:
[
"CMD",
"curl",
"--fail",
"http://localhost:8080/health"
]
interval: 30s
timeout: 30s
retries: 5
airflow-init:
<<: *common
container_name: airflow-init
entrypoint: /bin/bash
command:
- -c
- |
mkdir -p /sources/logs /sources/dags
chown -R "${AIRFLOW_UID}:0" /sources/{logs,dags}
exec /entrypoint airflow version
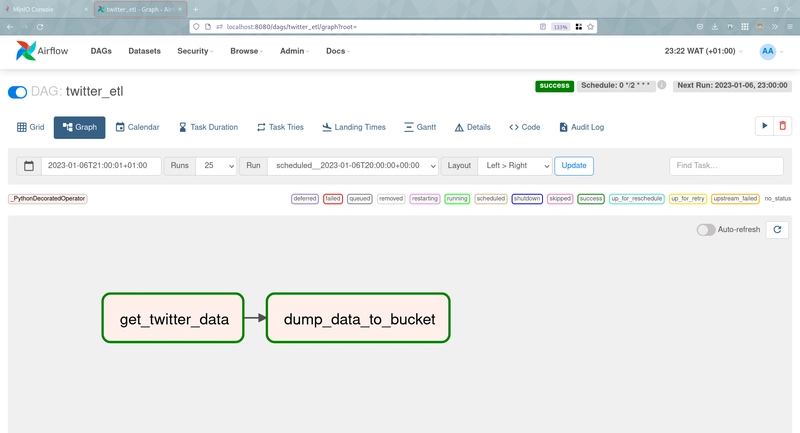
When we access the Apache-Airflow Web UI, we can see the DAG and we can run it directly to see the results.
DAG (Apache-Airflow web UI):
Tweets file generated in our bucket (MinIO Console):

This is a wrap. I hope this helps you.
About Me
I am a Data Engineer with 3+ years of experience and more years as a Software Engineer (5+ years). I enjoy learning and teaching (mostly learning 😎).
You can get in touch with me by mike.kenneth47@gmail.com, Twitter & LinkedIn.
Article posted using bloggu.io. Try it for free.

Top comments (1)
Good job 🚀