![Cover image for [EN] Senginta: Traditional Search Engine Scrapper](https://media2.dev.to/dynamic/image/width=1000,height=420,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fvtjaw3rlfdmq35zfhcx6.jpg)
Senginta, a web scraper that is able to retrieve results from several Search Engine Products. Yours sincerely to Search Engines that do not provide Captcha. 👏
In these days Search Engines increasingly have a role to introduce something. Many people have learned the properties of a Search Engine, so that their blog or product can rise to the highest level to get large visitor traffic.
It's not just a business need. Search Engines are also able to search for various things that can be used as data entities. Only with the full name, they were able to find results relevant to that name.
But have we ever thought about automating the results given? Suppose you want to speed up the process of saving lots of images, videos, pdf from search engines, wouldn't that be great?
Unlike the current one. We have to do these things manually.
Senginta comes with the ability to help with the work earlier. If you are familiar with the name JSON, it is a format used by multiple systems to communicate with each other.
If you are confused, please DM me on Instagram and ask.

In this case, other systems can be integrated with Senginta via Python Module with JSON format and other formats. With just a small amount of code below, you can get search results from a complete Search Engine.
Even other Search Engine products have also been applied.
- Default Google Search
- Google Books
- Google News
- Google Video
- Google Shop
- Google Scholar
- Default Baidu Search
Preparation
- Make sure your python version is 3.8 or above.
$ python3 --version
Python 3.8.3rc1
OR
$ python --version
Python 3.8.3rc1
- Install Senginta using the PIP installer.
$ pip3 install senginta
...
OR
$ pip install senginta
...
Done!
How to use: Senginta
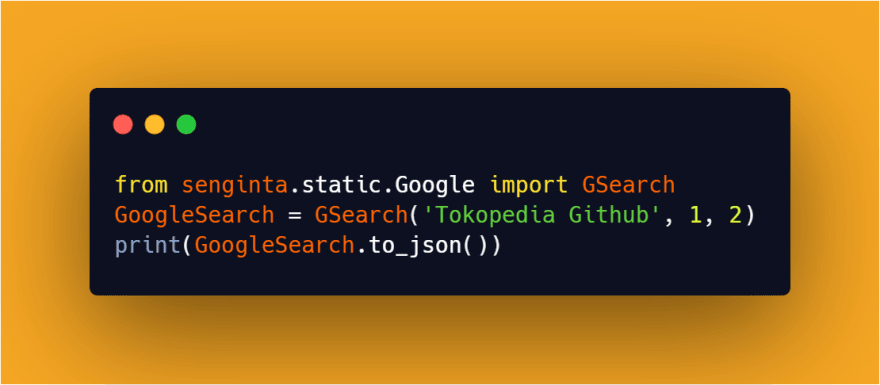
0:10 Google Search
GoogleSearch = GSearch('Tokopedia Github', 1, 2)
print(GoogleSearch.to_json())
0:47 Google Books
GoogleBooks = GBooks('Python Programming', 1, 2)
print(GoogleBooks.to_json())
01:35 Google News
GoogleNews = GNews('Idcloudhost', 1, 2)
print(GoogleNews.to_json())
02:23 Google Shop
GoogleShops = GShop('Remote TV', 'Rp', 1, 2)
print(GoogleShops.to_json())
03:32 Google Video
GoogleVideo = GVideo('Pegipegi', 1, 2)
print(GoogleVideo.to_json())
04:26 Google Scholar
GScholar.URL += "ANOTHER_PARAMETER_URL_FOR_PASS_BOT"
GoogleScholar = GScholar('Penggunaan Naive Bayes Classifier', 1, 2)
print(GoogleScholar.to_json())
Another useful method
.to_pd() = Convert the results to a Pandas DataFrame.
.to_json() = Convert the results to a Json.
.get_all() = Convert the results to a dictionary.

Top comments (0)