Some applications need to get random data for providing their customers are good and diversified experience, e.g. for a quiz app. In this article we take a look at three serverless approaches to getting random records from a large and changing set of data.
A serverless mechanism for getting random records should be scalable, support a changing dataset and scale down to zero if not in use.
A great quiz app lets us store millions of questions so that the game stays interesting to our customers. It also allows us to add more questions over time, and remove questions that are outdated.
Keep in mind that true randomness is not always desirable, as that can lead to your user seeing the same record 5 times after another. Keep track of what your user has already seen, and try again if you load a record that they’ve already seen.
Use Cases
Apart from a quiz app, you might need to get random records for
- a vocabulary app,
- a “wisdom of the day” Twitter bot,
- a “picture of the week” calendar,
- a Special Sales Deal suggestion,
and many more.
Prerequisites
You need an AWS account and credentials in the environment that you’re running the examples from. You can use AWS CloudShell for this.
To get the most of this article, you should be familiar with one of DynamoDB, S3 or Redis.
Python knowledge, or the ability to translate the examples to other languages is a nice to have.
Offset
In the chapters for DynamoDB and S3 we’re using a random offset. The trick here is that this random offset does not need to exist as a record in the target service. S3 and DynamoDB will take it and scan until they find a record.
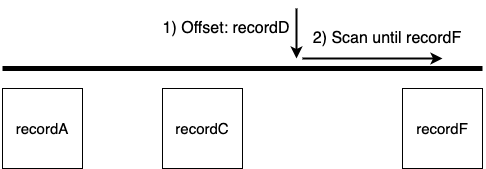
In plain English we tell DynamoDB and S3 to start at a certain point, and then keep looking until they find one record.
DynamoDB
DynamoDB is a serverless key-value database that is optimized for transactional access patterns. If the partition key of our table is random within a range (e.g. a UUID), we can combine a Scan operation with a random offset to get a random record on each request.
Tyrone Erasmus pointed me to a Stackoverflow answer, that we’re looking at in more detail below.
I have used the most upvoted answer once or twice on dynamo: https://t.co/OdIWdTWVzI
Wasn't intuitive at first but actually works really well (and only consumes 1 read capacity)
— Tyrone Erasmus (@metall0id) December 25, 2020
In this example we’re using the Python library boto3 for DynamoDB.
First we insert some records that have a UUID as their partition key.
for i in range(100):
item = {'pk': str(uuid4()), 'text': f'What is {i}+{i}?'}
table.put_item(Item=item)
There are more exhaustive examples in the following sections.
The second step is to run the Scan operation with a random offset. We use the parameter Limit so that the scan stops after it found one entry, and we use ExclusiveStartKey to pass in a random offset.
table.scan(
Limit=1,
ExclusiveStartKey={
'pk': str(uuid4())
}
)
In the above example we have a table that has a partition key called pk. Every record in this database has a UUID as their partition key.
By running this command, we read and retrieve exactly one record. While scans are usually considered expensive, but this scan operation only consumes 0.5 capacity units. This is the same amount a get_item operation consumes. You can test this by adding the parameterReturnConsumedCapacity='TOTAL' to the scan operation.
From my tests DynamoDB offers the best price for datasets with heavy usage. If you store a lot of records but only rarely access them, then S3 offers better pricing. More on that in the cost comparison.
Please note that DynamoDB has a size limit of 400 KB per record. If you exceed that, then consider using the S3 or Redis approach.
Fully Random
Here’s a complete Python example to pick a random record from a table called random-table. The example includes writing records and checking for an edge case where we start at the end of the table.
import boto3
from uuid import uuid4
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('random-table')
# Create 100 records with a random partition key
for i in range(100):
item = {'pk': str(uuid4()), 'text': f"question-{i}"}
table.put_item(Item=item)
print(f"Inserted {item}")
# Read 3 records and print them with the consumed capacity
for i in range(3):
response = table.scan(
Limit=1,
ExclusiveStartKey={
'pk': str(uuid4())
},
ReturnConsumedCapacity='TOTAL'
)
if response['Items']:
print({
"Item": response['Items'][0],
"Capacity": response['ConsumedCapacity']['CapacityUnits'],
"ScannedCount": response['ScannedCount']
})
else:
print("Didn't find an item. Please try again.")
Categorized
Many use cases are not fully random, but require some kind of categorization. An example for this is a quiz, where we have the three difficulties ['easy', 'medium', 'difficult'].
In this case, we don’t want to query for a fully random record until we find one that matches the desired category. Instead, we want to achieve the same with one request.
To achieve this we need a different data model. Instead of putting the UUID into the partition key, we use the partition key for the category and add a sort key with the UUID. This may lead to a big partition, but there’s no limit on how many records you can store in a single DynamoDB partition:
In a DynamoDB table, there is no upper limit on the number of distinct sort key values per partition key value. If you needed to store many billions of Dog items in the Pets table, DynamoDB would allocate enough storage to handle this requirement automatically. - DynamoDB documentation about partitions
Here’s an example which expands on the fully random example with categories.
import boto3
from uuid import uuid4
from boto3.dynamodb.conditions import Key
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('random-table-categorized')
categories = ['easy', 'medium', 'difficult']
for category in categories:
# Create 50 records for each category with a random sort key
for i in range(50):
item = {'pk': category, 'sk': str(uuid4()), 'text': f"question-{category}-{i}"}
table.put_item(Item=item)
print(f"Inserted {item}")
for category in categories:
# Read 3 records and print them with the consumed capacity
for i in range(3):
response = table.query(
Limit=1,
KeyConditionExpression=Key('pk').eq(category) & Key('sk').gt(str(uuid4())),
ReturnConsumedCapacity='TOTAL'
)
if response['Items']:
print({
"Item": response['Items'][0],
"Capacity": response['ConsumedCapacity']['CapacityUnits'],
"ScannedCount": response['ScannedCount']
})
else:
print("Didn't find an item. Please try again.")
S3
S3 is a serverless object storage. It allows you to store and retrieve any amount of data, and offers industry-leading scalability, availability and performance. It’s also cheaper than fully fledged databases for storage heavy use cases. It does however offer less query flexibility than databases like DynamoDB.
With S3 we take a similar approach to the one used with DynamoDB, which we need two API calls for: One for finding the key of a random object, and one for retrieving that object’s content.
Assuming that there’s a bucket called my-bucket-name with files that each have a UUID as their name, we can use the following approach.
list_response = s3client.list_objects_v2(
Bucket='my-bucket-name',
MaxKeys=1,
StartAfter=str(uuid4()),
)
key = list_response['Contents'][0]['Key']
item_response = s3client.get_object(
Bucket=bucket_name,
Key=key
)
With the parameter MaxKeys=1 we tell list_objects_v2 to stop after it found one file. StartAfter is the equivalent to DynamoDB’s ExclusiveStartKey which allows us to pass a random offset. The result of list_objects_v2is a list of object keys, from which we pick the first one and retrieve the object.The result is sorted alphabetically.
Fully Random
Here’s a Python example to pick a random record from a bucket called my-bucket-name. The example includes writing files and checking for an edge case, where we might have started at the end of the bucket.
import boto3
from uuid import uuid4
client = boto3.client('s3')
bucket_name = 'my-bucket-name'
# Create 100 records with a random key
for i in range(100):
key = str(uuid4())
client.put_object(Body=f"question={i}".encode(),
Bucket=bucket_name,
Key=key)
print(f"Inserted {key}")
# Read 3 records and print them
for i in range(3):
list_response = client.list_objects_v2(
Bucket=bucket_name,
MaxKeys=1,
StartAfter=str(uuid4()),
)
if 'Contents' in list_response:
key = list_response['Contents'][0]['Key']
item_response = client.get_object(
Bucket=bucket_name,
Key=key
)
print({
'Key': key,
'Content': item_response['Body'].read().decode('utf-8')
})
else:
print("Didn't find an item. Please try again.")
Categorized
Here’s an S3 example with categories, which we add as a key prefix. What was previously keynow becomes category/key. For list_objects_v2 we need to consider the category in two places. The first one is the Prefix parameter, and the second one is the StartAfter parameter which needs to include the category and the key.
import boto3
from uuid import uuid4
client = boto3.client('s3')
bucket_name = 'my-random-bucket'
categories = ['easy', 'medium', 'difficult']
for category in categories:
# Create 100 records with a random key
for i in range(100):
key = str(uuid4())
client.put_object(Body=f"question-{category}-{i}".encode(),
Bucket=bucket_name,
Key=f"{category}/{key}")
print(f"Inserted {key} for category {category}")
for category in categories:
# Read 3 records and print them
for i in range(3):
start_after = f"{category}/{uuid4()}"
list_response = client.list_objects_v2(
Bucket=bucket_name,
MaxKeys=1,
Prefix=category,
StartAfter=start_after
)
if 'Contents' in list_response:
key = list_response['Contents'][0]['Key']
item_response = client.get_object(
Bucket=bucket_name,
Key=key
)
print({
'Key': key,
'Content': item_response['Body'].read().decode('utf-8'),
})
else:
print("Didn't find an item. Please try again.")
If you omit the Prefix, you might find objects that are outside the selected category. Assuming that the StartAfterparameter is categoryA/object2, and that we don’t provide a Prefix, then our result would be categoryB/object3. If we however include Prefix=categoryA, then categoryB/object3 doesn’t match, and we get an empty result instead.
categoryA/object1
categoryA/object2
categoryB/object3
The list_objects_v2 call always returns an ordered list.
Redis
Redis is an in-memory data store that can be used as a database amongst others. While Redis is not serverless, there are offerings like Lambda Storethat you can use to keep your application fully serverless.
Have you tried redis? It has both RANDOMKEY as well as SRANDMEMBER commands that might be useful here
— Yan Cui is making the AppSync Masterclass (@theburningmonk ) December 25, 2020
The Redis approach suggested by Yan Cui is a lot simpler, because there are built-in command to pick random entries:
-
RANDOMKEYgets a random key from the currently selected database. -
SRANDMEMBERlets us pick one or more random entries from a set, which lets us add categorization.
Redis has a size limit of 512 MB per record.
Fully Random
In the example below, we store unstructured records in our database. We retrieve a random key with the command RANDOMKEY, and then get the value with the GET {key} command.
SET firstKey "Hello world!"
SET secondKey "Panda"
RANDOMKEY
> "secondKey"
GET firstKey
> "Panda"
This approach requires two calls per random record.
Categorized
We can leverage sets to add categories into our data. This approach is very powerful, as the SRANDMEMBER command has an optional parameter with which we can specify how many records we want to retrieve. This comes in handy, if our users should see multiple entries at once.
SADD easy 1 2 3 4 5 6 7 8 9
SADD medium 1 2 3 4 5 6 7 8 9
SADD difficult 1 2 3 4 5 6 7 8 9
SRANDMEMBER easy
> 5
SRANDMEMBER medium 2
> 3,6
SRANDMEMBER difficult 5
> 2,3,6,7,9
This approach only needs one call per random record, or less if you retrieve multiple records at once.
Cost Comparison
In the cost comparison we’re looking at DynamoDB (On-Demand), S3 (Standard), and Lambda Store, because all of them are serverless solutions. All of them have a free tier that lets you test the approaches for free.
In the cost comparison we’re reading from a dataset of one million records, each with a size of 1 KB. This should be enough for a question and some meta information. The total size of this data set is 1 GB. We’re excluding cost for Data Transfer.
In the first table you see the price per single random record, as well as per million.
| Service | Single Record | One Million Records |
|---|---|---|
| DynamoDB | $0.000000125 | $0.125 |
| S3 | $0.0000054 | $5.4 |
| Lambda Store | $0.000004 | $4 |
With DynamoDB, we’re using eventually consistent reads which are charged at a half read capacity unit. For S3 we need a List and a Get call, which are added together in the table. Lambda Store has a flat price per 100,000 requests. We’re assuming the SRANDMEMBER operation here, as it needs only one request.
In the second table you see the price per 1 GB stored per month.
| Service | GB-month |
|---|---|
| DynamoDB | $0.25 |
| S3 | $0.023 |
| Lambda Store | $0.15 |
Limitations
Lambda Store has a concurrency limit of 20 in the free tier, 1000 in the Standard tier and 5000 in the Premium tier. They do however offer reserved capacity for high throughput use cases. So once you hit these limits, you probably have a working business model that can pay for reserved capacity.
With DynamoDB, you might hit a throughput limitation, even if you’re in On-Demand mode. To work around this, you can let your app retry for a few times, or switch to a high provisioned capacity. Another approach I heard of but didn’t verify is to create the table with a very high provisioned capacity, and then immediately switch back to On-Demand.
Conclusion
Serverless is a great fit for providing random records. The application scales with demand and has a very low price per access.
DynamoDB has the lowest cost and highest flexibility for applications that are similar to a quiz app. The pricing is better for applications that have a few million records, and where those records are read frequently and repeatedly. Imagine 10 million records stored, with 100 million reads each month.
S3 becomes interesting for applications that use significantly more storage , and read infrequently. Imagine 10 billion records stored, and 2 million reads a month.
Lambda Store has the easiest learning curve at a reasonable price. Its Redis database is also the only of the three offerings, that can return multiple random records in one request. Last but not leastLambda Store says on their website that their latency is “submillisecond while the latency is up to 10 msec in DynamoDB”. Check out their full benchmark article.

Top comments (0)