
Real-time machine learning refers to continually improving a machine learning model by feeding it actual data. A data analyst /scientist or a developer creates the model offline using a collection of the previous testing set. All sectors and industries try their best to fetch all possible benefits from machine learning, whether for cognitive research or auto-continuous processes. Consider a smart home assistant like Google Home or a smart activity tracking device, voice recognition systems such as Alexa or Siri, or automated cars. This artificial technology has advanced a lot.
Machine learning is more branched into other types, which are defined below:
Supervised learning: your model predicts the correct outcomes/labels. Most supervised learning algorithms include linear and logistic regression;
Unsupervised learning: this learning looks for patterns with pre-existing labels in the dataset;
Reinforcement learning: this learning refers to how some behaviors are discouraged or encouraged;
A machine learning model’s accuracy deteriorates over time because of data drift. The frequency of updates determines how effectively a model operates. While businesses like Google, Alibaba, and Facebook have been able to use real-time pipelines to change several of their algorithms in production continuously and improve their performance, many other businesses still update their models by hand. In this article, we’ll discuss the motives, difficulties, and potential solutions for machine learning’s current state of continual learning.
The value of data supplied to machine learning models is frequently most significant when it can be used immediately to make suitable decisions. However, user data is typically ingested, converted, stored, and left idle for a long time before being used by machine learning models.
Consumer-facing products, such as the Headspace app, can significantly decrease the edge user feedback loop by using consumer data to provide real-time insights and judgments. This is because users take actions just moments earlier that could be fully integrated into the item to produce more meaningful, personally tailored, and situationally content proposals for the consumer.
However, for streaming or real-time data Memphis platform is widely used and provides training with machine-learning algorithms.
Real-time machine learning continually improves a machine learning model by feeding it accurate data.
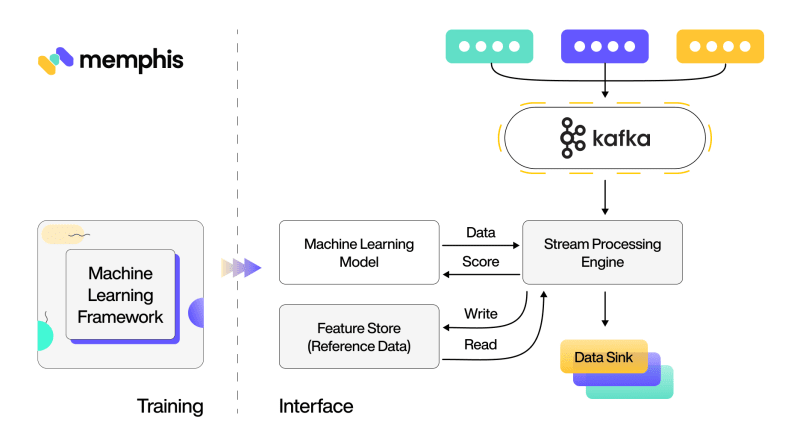
A Machine learning model is applied to a streaming data pipeline. This workflow absorbs and modifies data in real-time chunks between a supplier and a goal in a process known as streaming machine learning.
Continual learning and Machine learning prediction delay may be improved via a streaming infrastructure. A part of computing is batch processing for small datasets.
Machine learning and data analysis techniques are suitable for aiding the security of enormous streaming systems. Machine learning, also known as model training, creates a prediction model from the required given data.
When knowledge-based algorithms, such as real-time machine learning or deep neural networks, are used properly, they benefit the most. Image identification A commonly used and widespread machine learning application in real life is image recognition.
Why real-time Machine Learning is in demand
Because there needs to be more available data beforehand for training or when data must respond to different tendencies, real-time machine learning might be helpful. For instance, if customer preferences and needs vary over time, a machine-learning-based item recommender that is constantly improving may adapt to such changes without the need for additional retraining. Therefore, by identifying new trends and adjusting to reflect them, real-time machine learning may give businesses and their consumers a more instantaneous accuracy.
Real-time machine learning models are typically deployed in this way to production in an event-driven architecture, where data is continuously injected into the model. The pipeline for processing the data stream handles all data refining and manipulation required to get the data ready for input into the model. The pipeline simultaneously modifies the model and the reference set of data it is built on using real-time data.
High-performance technologies have been increasing daily in our everyday lives over the past few years. The scope of artificial intelligence and their respective jobs now hold much respect in the industry. From voice assistants like Siri or Alexa to high-technology coffee makers, these are becoming a vital part of our daily lives, leading to the positive evolution of machine learning artificial intelligence jobs.
Real-time data streaming platform
You may gather, process, evaluate, and provide constant streaming of large amounts of data to your real-time apps and analytical services with real-time data streaming services. By utilizing secure, highly accessible, robust, and adaptable centrally managed services, developers can easily create real-time apps.
Real-time data streaming is gathering and absorbing a series of data from several sources and then interpreting that data in real-time to get information. Rather than having to wait for periods or longer for results, real-time data streaming allows users to examine and handle data immediately.
Log files produced by users of web applications, e-commerce prepayments, data from social networks, trading information from financial platforms, geographic analysis services, and satellite tracking from smart gadgets are examples of streaming data.
There are 5 components of real-time data streaming:
Source: thousands of devices generate millions of data every second like mobile, web apps, etc.
Stream ingestion: enables you to grasp thousands of data produced from the above-mentioned devices;
Stream storage: memory that will be used to hold that variety of data;
Stream processing;
Destination: deliver streaming data for analytical secrecies for further analysis;
One major platform widely used to continually process data streams is Memphis.
Memphis
Memphis is the emerging solution to all the problems in developing real-time systems. It claims to be the fastest solution, and it has proved to be the one. It helps build streaming platforms faster than any platform in the market. The main benefit of Memphis is that it is an open-source platform that is publicly accessible. This platform is an easily accessible, real-time data integrator.
Features
Current
- It delivers a completely optimized message broker in a couple of minutes.
- It offers an intuitive User interface, such as a command line interface.
- It gives observability at the data level.
- It offers the message's route during transmission.
- It makes use of software development kits such as Python Node.JS etc.
Coming
- It will use more SDKs.
- It will provide prepared connections and analysis tools.
- It will provide inline processing.
Pros of using Memphis
Memphis’s platform enables the construction of next-generation applications, which call for massive amounts of streamed and enhanced data, current protocols, zero operations, rapid development, drastic cost reduction, and a smaller amount of development time from data-oriented programmers and data engineers. The main focus of Memphis is:
- Performance - Improved cache utilization;
- Resiliency - provides 99.95% uptime;
- Observability – correct observation that cuts down the troubleshooting time;
- Developer Experience - Inline processing, schema management, modularity, and tops;

Scenarios of real-time Machine Learning
For business research artificial intelligence, computer systems may use machine learning to use all the client data. It adheres to the already programmed required instructions whilst still changing or adjusting to different situations. Data displaying a previous inability to perform behavior causes algorithms to alter.
A digital assistant might read emails and retrieve vital info if it could understand the situation. This understanding comes with the ability to predict future client behavior as a built-in capability. As a result, you may have been more active and flexible to the demands of your consumers.
Deep learning falls under machine learning. The neural net network has three tiers. A rough estimation can be produced using one-layer neural networks. Precision and performance may both be enhanced by adding more layers. Machine learning is helpful in a variety of different blocks and businesses and could move forward more efficiently over time. Here are five instances of real-world applications for machine learning.
Pattern/Image recognition
Pattern or image recognition is a common and widely used application of machine learning in the physical world. Depending on the severity of the pixel in dark or light or black and white or colored images, it can recognize an item as a digital photo. Its real-life example is diagnosing an Xray that if it has cancer or not.
A collection of methods that fall under the category of image recognition, a branch of artificial intelligence, represent the detection and interpretation of images to enable the automation of a certain activity. It is a method that can identify objects, people, places, and various other aspects in an image and draw conclusions about them through analysis.
Speech recognition
Speaking to text is a capability of machine learning. A text file may be produced using specific computer software that can convert both spoken and taped or recorded speech. The speech is further characterized into segments based on intensities on time-frequency bands. Real-life word examples include voice dialing and voice search.
A microphone must create an electrical signal that resembles a wave before any system can understand speech. This signal is then transformed into a binary code by the computer or computer network, such as a device’s sound card. A speech recognition software examines the digital data to identify distinct vowel sounds, the fundamental constituents of speech. The words are created by recombining the consonants. However, because so many words have a similar sound, the algorithm must depend on the circumstances to choose the right term.
Medical diagnosis
Machine learning can help in medical diagnostics. Many clinicians use speech software to identify disease clusters. Its real-life examples include analyzing body fluids.
Predictive analysis
Available data may be classified by machine learning into categories further defined by regulations established by researchers. The researchers can determine the likelihood of a defect after classification is completed. A real-life example includes checking whether the transaction is valid or fraudulent.
Extraction
From unstructured data, machine learning can retrieve specific data. Enterprises gather countless amounts of client data. The process of automatically labeling datasets for predictive data analysis tools uses an algorithm for machine learning. Is real life examples include helping doctors to treat the problem and diagnosing them easily. This extraction is carried out by our platform Memphis which makes it more helpful for us as it provides a more realistic and comprehensive system with the use of the cloud.
Online prediction
AI Platform Prediction is designed to process your data using dedicated models as quickly as feasible. The service receives tiny batches of data from you and responds to your predictions.
Due to the expense of maintaining logs, the Automated Network Prediction tool does not give recorded information about queries by default. Online prediction with several requests every second might generate a large volume of logs charged for by Cloud Monitoring.
Online prediction contexts are used when you wish to make predictions in a low-latency scenario for each example separately from the other instances.
Predictions can be used, for instance, to quickly determine if an amount due seems most likely to be fraudulent.
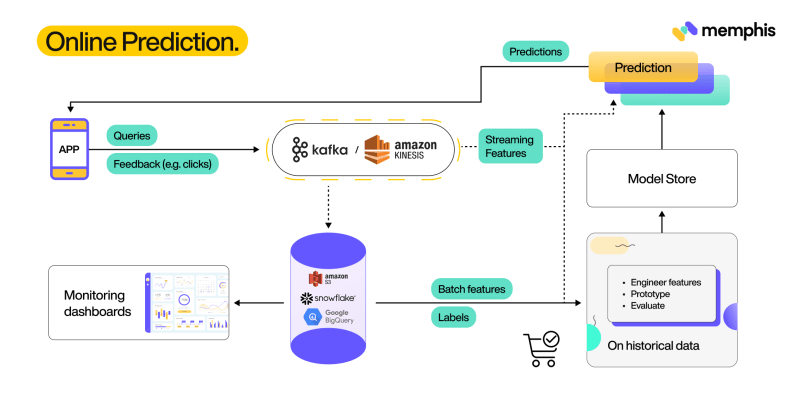
Although I think the widespread adoption of continual learning remains a couple of decades away, I’m observing considerable efforts from businesses to move toward online prediction. We’ll describe the requirements for a straightforward online prediction system employing batch characteristics, often helpful for in-session adaption, starting with a batch prediction system. Later, we’ll discuss developing an online prediction tool that uses both batch and streaming capabilities.
Requirements
You must do the following for this stage:
- Switch your models over to session-based predictions from batch predictions.
- Include session data in your online prediction tool.
You don’t have to create predictions for users who aren’t viewing your site while using online prediction. For example, in 2020, Grub hub reported 31 million monthly active consumers and 620,000 average orders. Imagine that just 2 percent of your consumers log in daily to your app.
The computing power needed to produce 98% of your online forecasts would be useless if you generated predictions for every client daily.
Continual learning
The idea behind continual learning, also referred to as incremental learning, is to learn a model for many multiple jobs chronologically without neglecting the information acquired from the tasks that came before them, even when the statistic for the older tasks is no longer available when training the new ones.
People immediately conjure up frequent model updates, like once every five minutes, when they hear “continual learning.” Many contend that most businesses don’t require changes that regularly because:
- For that retrained timeline to understand, they need traffic.
- Their models don't degrade as quickly.
I concur with them. However, continual learning isn’t about how often the model is retraining frequency; it’s about how it’s retrained.
Most businesses use stateless retraining, in which each time the model is programmed from the start. Continual learning entails enabling stateful training, where the model keeps learning with fresh input. Continual learning is what we aim for and what we think many businesses will eventually follow.
The peak is reached when edge deployment and continual learning are combined. Envision can deliver a basic model with a new gadget—a cellphone, a wearable timepiece, etc.—and have that model automatically keep track and customize to the surroundings. There is no need to transport data between a device and the cloud constantly, and there are no client-server costs.
Conclusion
The main issue with real-time machine learning is the equipment. The platform team and the computer analytics or machine learning team will be required to must collaborate to find a solution. A developed streaming platform is required for continual learning and online prediction. Continual learning’s training component may be completed in batches, but its online assessment component necessitates streaming. Streaming is difficult and expensive, which worries many developers. Although it was accurate three years ago, streaming technology has advanced greatly. Many famous companies are now providing and are increasingly proposing a solution to simplify businesses’ transition to streaming. Memphis plays a major role in streaming, making it more efficient with the help of its cloud-based system.
Nowadays, many developers are conducting a poll to learn more about real-time machine learning usage and industry obstacles. It should only take a few minutes for you to share your opinions with them. The user will be informed of the results when they have been compiled and summarized.
Machine Learning deployment architecture
Machine learning has advanced to a higher platform over time. However, it’s unfortunate that most universities, blogs, and other sources still need to provide a partial understanding of the principles or pipelines of machine learning. The applicable principles are only presented up to the model’s formation, training, and testing. Even though it is crucial to be aware of the various/multiple available ways of distributing the model alongside their use cases & design, there are surprisingly few locations where the model deployment is discussed.
The act of providing the machine learning model accessible to such end clients is known as model deployment. The developed model must be able to accept requests from the customer base and then provide the output to the same viewers.
Every time a model is deployed, an application is used to present that use case or, at the very least, build the gateway used to deploy the model. This is because every model has a specific use case that it must complete.
For instance, the most basic model deployment may be done via a website page that can accept user input, utilize that input to run the model, and then deliver the outcome to the client. That basic web page will serve as the application in this case.
Considering this, let’s examine the 4 various model deployment architectures:
Built-in Architecture/Embedded Architecture
According to the design, the model is bundled into the finished product at the time of the application’s construction and delivered within it in an embedded manner as a requirement of the initiative.
The Model was Published as Data
A streaming program is utilized to maintain and keep the models that may be accessed by the apps because this architecture supports streaming in the applications as well. This design is much more sophisticated, can handle many challenging use cases, and is far more advanced than the rest.
Offline Predictions
Only this architecture lacks some functionality as compared to other architectures. Also, in this case, the exchange is significantly more in favor of boosting the overall mechanism architecture & complexity. This architecture is rather outdated, but it still has many valuable applications, such as when it is necessary to verify if a prediction is valid or invalid.
Challenges in streaming-first infrastructure
Developers, data scientists, and security engineers must solve various difficulties to ensure the effective deployment and uptake of a real-time streaming site. However, some of the challenges faced during the streaming-first infrastructure of machine learning in real-time are described below:
Choose the necessary data structures, formats, and schemes
Usually, streaming data will be transmitted to a sizable data repository on-hand or cloud-based. Developers, programmers, and subject matter experts analyze this data to derive insights, comprehend patterns, and create methods deployed in real-time to various data streams to promote efficiency and derive more commercial value.
Malfunction information for the equipment being monitored is generally needed for creating predictive maintenance algorithms like RUL, condition monitoring, or APM programs. Operating rising resources or survival operations could be too expensive or impracticable until they fail.
Evaluation and authentication of algorithms
To guarantee that the control parameters of the resources are correctly recognized and reported, experts must consider how algorithms are validated inside the integrated environment.
For algorithm verification and analysis, the streaming program should be able to repeat stored data streams to solve these issues. Usually, a verification system that is a scaled-down version of the actual streamed system would be used for this stage.
Simulated techniques should be applied to produce and transmit artificial data to evaluate unfavorable or edge scenarios, much as modeled input is utilized inside the algorithmic development process. The techniques implemented into these systems must be managed over their whole life-cycle validity and correct usage as they grow increasingly crucial to the functioning of a specific business, much like how corporate software application is handled. This would include the capacity to assess an algorithm’s correctness and effectiveness throughout the creation process, maintain the data utilized to create the algorithm and the assessment findings, and continuously record the outcomes along with details on the possible applications of the algorithm.
Scalability and Effectiveness
Systems that stream data in real time must respond to that data within predetermined time frames. As additional gadgets come online, they should be able to adapt since they are continuously operating. According to the normal partitioning used by famous streaming architecture, the system should expand, evolve, and scale. Additional dataflow contexts should be generated as specific ideas or streams are produced. Make sure you can take advantage of the flexibility of cloud-based technologies.
Securities
The security implications of the whole workflow, from design to computer system deployment, must be considered by architects and developers. A streaming programmer must interface with the firm’s current security levels to accommodate these activities and restrict access to data and systems depending on an individual’s function. Controlling access to end devices is part of this, especially when the streaming program is exercising and monitoring its control over other gadgets and devices. Additionally, the platform must support the security of data, the privacy of both records in transit and at rest, and the vital functionalities of the algorithms, mainly if those methodologies are accessed via a cloud service or by any system software.
Conclusion
Real-time machine learning is coming, even if you’re prepared to embrace it. While most businesses are still arguing the merits of online predictions and continual learning, others have begun to see a financial return. Their real-time programs may play a significant role in helping them stay one step ahead of their rivals.
After thoroughly examining our model run-time, we were able to determine that switching to famous streaming technologies has improved both the accuracy and predictability of our capacity planning and the throughput of our model during maximum periods. We no longer need to build satellite systems or construct programming to manage failures and edge situations to manage success and defeats.
Headspace machine learning
The Headspace machine learning team is still bringing out commercial use cases for such a platform. Headspace dramatically lowers the final lag between consumer actions and tailored content suggestions by utilizing real-time prediction. Events streamed from the regular instance, including previous results, in-app mobility activities, and even personal identification such as biometrics, etc., may all be used to alter the suggestions we provide to clients while they are still utilizing the Headspace application.
Current position of machine learning in the industry
Machine learning industry innovation is moving into recommendations using your information. Actual possibilities for your data are on the horizon thanks to innovation inside the machine learning sector. At the junction of explainable predictions, quick motion of tiny workloads, and modular streaming analytics, problems need to be solved right away. Machine learning-ready data will now be monitored, viewable, backed by massive platforms, and analyzed primarily via streamed methods. The data will be viewable, supported by the proper platform, and principally handled via go-through when it is prepared for machine learning.
Join 4500+ others and sign up for our data engineering newsletter.
Follow Us to get the latest updates!
Github•Docs•[Discord (https://discord.com/invite/DfWFT7fzUu)
Originally published at Memphis.dev By Shay Bratslavsky, Software Engineer at @Memphis.dev

Top comments (0)