Natural Language Processing (NLP) has seen significant improvements in recent years due to the advent of neural network models that have achieved state-of-the-art performance on a range of tasks like sentiment analysis, named entity recognition, and machine translation. However, these models require vast amounts of labeled data, which can be prohibitively expensive and time-consuming to obtain. With refinery and gates, we enable users to leverage the power of weak supervision in their production environment to mitigate the need for expensive manual labeling and costly model deployment.
Why use weak supervision?
Weak supervision is a promising alternative to traditional supervised learning that can help alleviate the need for vast amounts of labeled data. Weak supervision uses heuristics or rules to create noisy labels for the data. Noisy means that the labels are largely correct, but can contain more errors than labels obtained from manual labeling. These noisy labels can then be used to train a model that can generalize to new, unseen data. Or we can also optimize the weak supervision to use it directly for production! This approach is especially useful when there is no large labeled dataset available for a particular task or domain.
In the context of NLP, weak supervision can be used to annotate text data, such as social media posts or online reviews, with labels that are less precise than those obtained through manual annotation. For example, a weak supervision approach to sentiment analysis might use a set of rules in the form of programmatic labeling functions to label all tweets containing positive emojis as "positive," and all tweets that use negative emojis as "negative." These noisy labels can then be used to train a model that can classify new tweets into positive or negative categories.
Despite the challenges, weak supervision has gained popularity in recent years due to its ability to quickly and easily generate labeled data. It can also be used in combination with traditional supervised learning to improve model performance further. For instance, a weak supervision approach can be used to generate initial labels for a dataset, which can then be refined by human annotators in a process called "bootstrapping." This iterative process of weak supervision and human annotation can help reduce the amount of manual labeling required and improve the quality of the final dataset.
Another advantage of weak supervision is that it can be used to label rare or unusual events that are difficult to label using traditional supervised learning approaches. For example, it can be challenging to obtain labeled data for rare diseases or rare events in social media. However, a weak supervision approach can use domain-specific knowledge to generate labels for these rare events, enabling models to learn from limited data.
How to deal with noisy labels
While weak supervision can be a powerful tool for training models with limited labeled data, it comes with its own set of challenges. Cheap labels are often noisy. Noisy labels can introduce errors and biases into the training data, and it can be difficult to quantify the quality of the labels generated by the weak supervision process. However, there are reliable methods that allow us to easily spot errors in labels quickly.
One of those methods is called confident learning. Confident learning is a technique used to identify and correct errors in noisy labels, so this is perfect for weakly supervised data! The approach involves training a model on the noisy labels generated through weak supervision and then using the model's predictions to estimate the confidence of each label. Labels with low confidence can then be flagged as potentially incorrect and subjected to further scrutiny or correction. This method can help improve the quality of the final dataset and reduce the impact of errors introduced by weak supervision without the need to check all the labels manually.

Heuristics - sources for cheap labels
The classic approach to get labels would of course be to manually annotate the whole dataset. But that would be time-consuming, tedious, slow, and very expensive. Instead, we can only partly label our data by hand and try to find cheaper methods to obtain labels for the rest of our data. These cheap and inexpensive label sources will most likely be noisy. But if we can get labels from many different sources, then the final, weakly supervised label will be greater than the sum of its parts. In other words: It’s going to be accurate. In refinery, we call these sources heuristics.
Labeling functions
Labeling functions allow us to programmatically incorporate domain knowledge into the labeling process. Similar to expert systems, which are still in place in many companies. We can do this with programming languages like Python. A domain expert has a mental model in his mind, of how and why he would label things in a certain way. In the field of natural language processing, this could be certain words, the structure of sentences, or the author of a text. All of these can be expressed programmatically. Let’s imagine that we want to build a classifier to detect clickbait. We would quickly notice that a lot of clickbait starts with a number and that clickbait often addresses the reader directly. We could incorporate this simply with just a few lines of code:

These labeling functions won’t be perfect, but as long as they are better than guessing, we’ve already gained something. In the iterative process of getting labels, these functions can also be improved and debugged later on as we gain more insights into our data.
Active learner
Active learning is a technique used to select the most informative examples from a large unlabeled dataset to be labeled by a human annotator. The goal is to select examples that will provide the most value in improving the model's performance while minimizing the number of examples that need to be labeled. This approach can be especially useful when labeled data is scarce or expensive to obtain. It involves iteratively training a model on a small subset of labeled data, selecting the most informative examples to label, and retraining the model on the expanded labeled dataset. This process can be repeated until the model's performance reaches a desired level or the budget for labeling is exhausted.
This is especially powerful if we use this in combination with pre-trained transformer models to embed out text data. These models handle all of the heavy-lifting during the active learning part, so that we can quickly get accurate results, even if we don’t have tons of data available.

Zero-shot classification
Zero-shot classification allows us to label data without having to explicitly train a model on that particular task or domain. Instead, we can use a pre-trained language model, such as BERT or GPT-3, that has been trained on a large corpus of text to generate labels for new, unseen data.
To use zero-shot classification, we need to provide the language model with a set of labels or categories that we want to use for classification. The language model can then generate a score or probability for each label, indicating how likely the input text belongs to that label. This approach can be especially useful when we have a small labeled dataset or no labeled data at all for a particular task or domain.

For example, let's say we want to classify news articles into different topics, such as politics, sports, and entertainment. We can use a pre-trained language model, such as BERT, to generate probabilities for each label. We would provide the language model with a set of examples for each label, such as news articles that belong to the politics category, and let it learn the patterns and features that are characteristic of each category. Then, when we give the language model a new, unseen news article, it can generate probabilities for each label, indicating how likely the article belongs to each category.
Combining heuristics for weak supervision in refinery

We now learned why weak supervision is so powerful. Let’s take a closer look at how we use all the possible heuristics for weak supervision in refinery.
In refinery, labels from different sources are combined and result in a singular, weakly supervised label. The labeling source includes manual labels, labels from labeling functions, active learner models as well as zero-shot labels. Let’s take a closer look at an example project, which contains news headlines.
A closer look under the hood
Here are the steps on how we obtain the weakly supervised label. We build a DataFrame out of the source vectors of our heuristics, which contain the label <> record mappings as well as the confidence values for all of our label sources. Afterward, the predictions are calculated for all of the label sources by multiplying the precision with the confidence of each label source. These values then all get added to an ensemble voting system, which integrated all the relevant data from the noisy label matrix into the singular weakly supervised label.
The ensemble voting system works by retrieving all of the confidence values from all the label sources, aggregating them, and selecting the label with the highest confidence values. The final confidence score is then calculated by subtracting the highest voting confidence score from the sum of voters and then subtracting this from the highest voting confidence score and after that, passing the output of this to a sigmoid function. The resulting weakly supervised label and the final confidence value are then added to our record in refinery.
Using weak supervision in production with gates
The great thing about weak supervision is that we can directly use it in production as well. We created custom labeling functions, already have machine learning models in our active learners, and include state-of-the-art transformer models to obtain labels. When using weak supervision, we set up a powerful environment to efficiently label data with ease. If this approach works well on unlabeled data in our dataset, chances are that it also works well with new incoming data in a production environment. Even better: We can even enrich our project with new incoming data and react to changes quickly. We can monitor the quality of our weak supervision system via the confidence scores and create or change labeling functions or label some new data manually when needed. This ensures high accuracy but also low cost in regards to maintaining AI in a production environment and removes the stress of monitoring and re-deploying machine learning models regularly.
That’s why we created gates, which allows you to use information from a weak supervision environment anywhere through an API. Our data-centric IDE for NLP allows you to use all the powerful weak supervision techniques to quickly label data. And through gates, you can access all your heuristics and active learners with the snap of a finger. No need to put models into production, you can access everything right away.
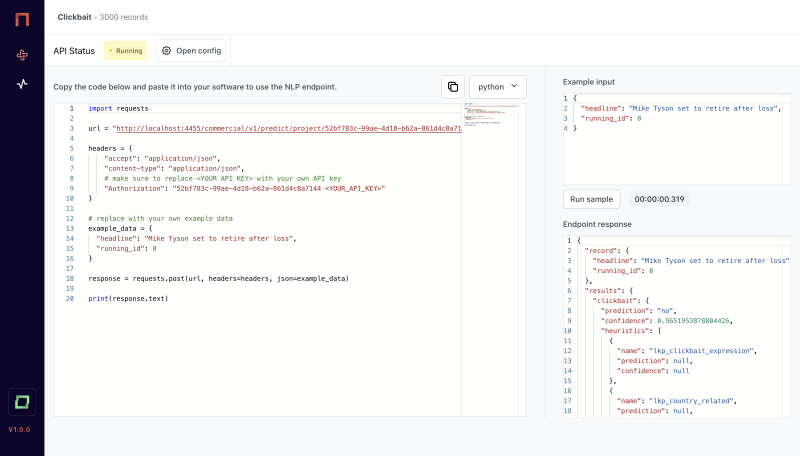
In conclusion, weak supervision is an amazing technique for NLP that can help alleviate the need for vast amounts of labeled data. It can be used to label data quickly and easily, especially for rare or unusual events, and can be combined with traditional supervised learning to improve model performance further. While it comes with its own set of challenges, recent research has shown that combining weak supervision with other techniques can help mitigate these challenges and improve model performance.

Top comments (0)