The Drive to Migrate Data to the Cloud
With data being valued more than oil in recent years, many organizations feel the pressure to become innovative and cost-effective when it comes to consolidating, storing, and using data. Although most enterprises are aware of big data opportunities, their existing infrastructure isn’t always capable of handling massive amounts of data.
By migrating to modern cloud data warehouses, organizations can benefit from improved scalability, better price elasticity, and enhanced security. But even with all these benefits, many businesses are still reluctant to make the move.
This is because these benefits are great once you get there. However, before companies can get there, they must go through the dreaded data migration process, and that process can be painful—especially if you don’t have the right tools.
To create an effective cloud data migration strategy, companies often struggle to find answers to key areas like:
- Gaps or anomalies in the source data
- Full or partial data migration
- Data owners and stakeholders
- Data lineage and dependencies
- Data consolidation process
- Automated regression testing for accuracy
With so many daunting concerns, it’s no wonder why many businesses delay their migration. And as a result, they miss out on the benefits of cloud data warehousing.
In this article, we will show you how—with a tool like Datafold—you can avoid a lot of the stress and complexities of data migration to Snowflake. While our focus in this article will be on Snowflake, a nearly identical approach can be used for migrating to Redshift, BigQuery, Databricks, or any other cloud data warehouse.
Snowflake and Datafold Together
Snowflake is a Software-as-a-Service (SaaS) data warehouse hosted entirely on cloud infrastructure. It has one of the biggest software IPOs in history, and is available on all three major cloud platforms, offering unlimited scalability in both storage and computing. Another reason for its popularity is its simple maintenance. Unlike most legacy data solutions, Snowflake takes care of the following:
- management
- upgrades
- tuning
- backups
- high availability
- indexing
It keeps its storage and computing layers separate, allowing significant cost-saving when not using computing power. Other attractive features include time travel, end-to-end encryption, and integration with popular identity providers.
Snowflake also natively integrates with third-party applications, creating a rich ecosystem of analytical capabilities. Datafold, a modern data reliability platform, can make data migration to Snowflake a breeze. For example, Datafold can:
- Intelligently profile data sources to show exactly where a piece of data is coming from and what it depends on
- Show before and after migration differences between source and target data sets.
- Use built-in machine learning models to automatically find data anomalies and alert users.
- Integrate with all major data warehouses—including Snowflake
- Be automated with tools like dbt or Apache Airflow or integrated into a continuous integration (CI) process.
The important question is: Can Datafold help prevent potentially costly mistakes when migrating to a Snowflake data warehouse? Let’s see.
Typical Data Migration Mistakes and How to Avoid Them
There are a few common mistakes DataOps teams make when migrating to a data warehouse.
Ignoring Key Stakeholders
Data engineering teams often rush through a migration project without consulting business stakeholders or including their feedback about data validation rules. This results in a flood of post-migration support tickets for erroneous or missing data. What’s worse is that some errors can go unnoticed.
For example, let’s say the team is migrating billing data, but the migration team hasn’t properly consulted the finance team. The currency conversion rates in the legacy system might use a four decimal point rounding while the new system uses only three. The engineers may deem this acceptable, but for the finance team, a change like this can mean skewed numbers across all their reports and subsequent business impact. To address this issue, Data Catalog in Datafold can list all your data sources in one place. This allows you to search and filter to find a particular table, database, or column from thousands of databases across your environment.
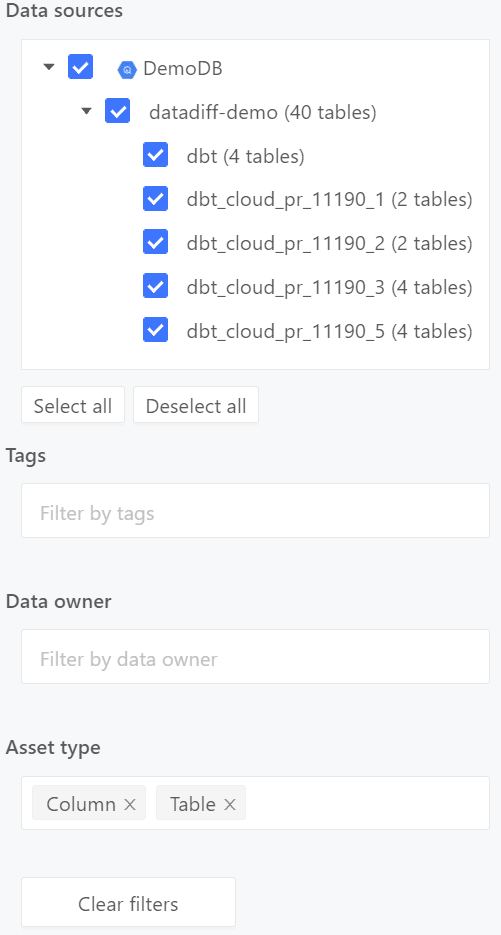
Once you find a data asset, you can easily add descriptions and tags, and also set owners for the assets. This makes it easy to know who to contact if you need to make a change or what types of changes are acceptable.
Taking a “Lift and Shift” Approach
Many businesses take a “lift and shift” approach to their data migration. This is where all the data from old systems is migrated to a new one with little to no validation, cleansing, or transformation. One of the reasons businesses take this approach is because they deem it too time-consuming to comb through huge datasets to find out what’s relevant and what’s not.
Lift and shift can only work when you’re 100% sure that the old system’s data is correct and portable as-is to the new system—and this is seldom the case. Consequently, you risk migrating incorrect or duplicate data and paying for its storage. When working with TBs—or even PBs—of data, these storage costs quickly add up.
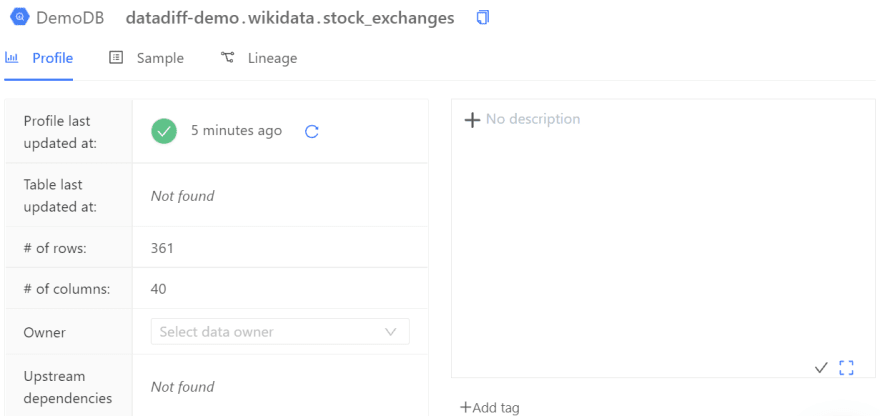
The Data Catalog summarizes the quality of the source data in terms of volume, completeness, and distribution of values. Using this, you can identify if important table columns like birthdate, email_address, or last_name are complete and if they need special business rules.
In the image below, we can see a table’s data profile:
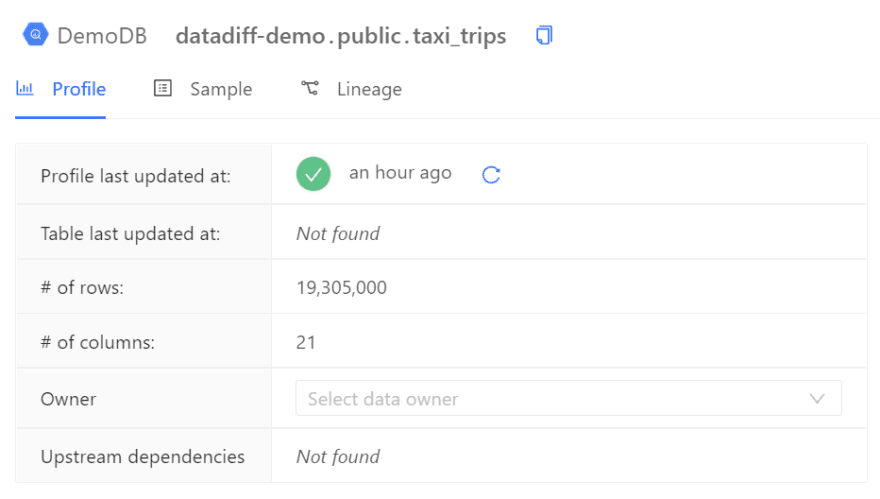
The table has more than 19 million rows and 21 columns. There are no upstream dependencies. Part of the column’s data distribution looks like the following:
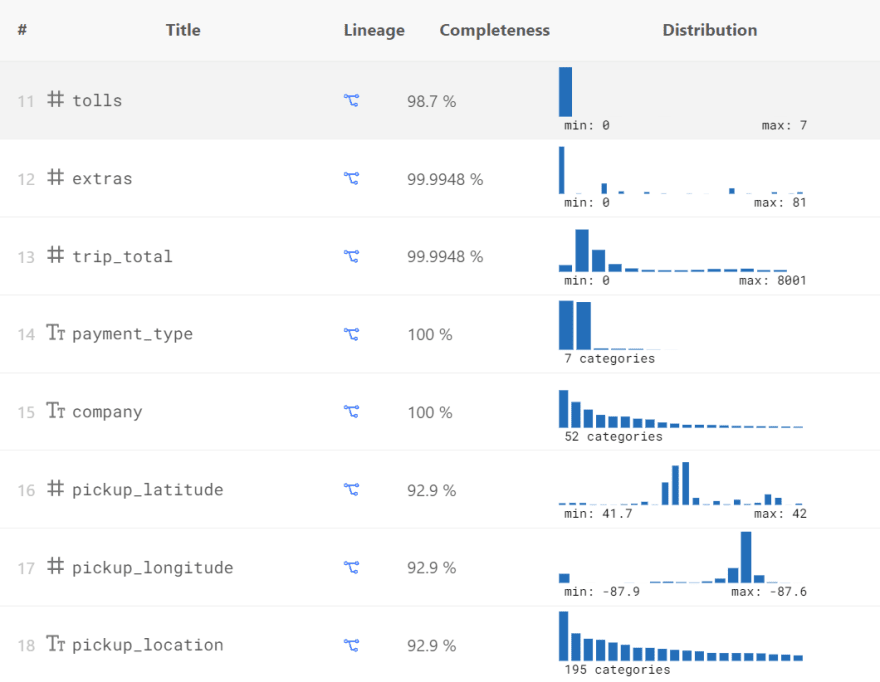
As you can see, some fields—like pickup_latitude and pickup_longitude—have lower completeness ratios. The graph also shows data distribution in different fields.
Data engineers can use such information to decide whether (or how) to cleanse and preprocess the data before migration.
The column-level lineage feature can also help by finding the most frequently used (and therefore, the most critical) tables and columns in the source.
One of the major drawbacks of lift-and-shift is that you’re never sure what fields or tables are unnecessary and don’t need to be ported. Column-level lineage makes this task much easier as it can discover all the dependencies of a table or column.

Using the Data Catalog and its lineage feature, let’s say you find a large source table that hasn’t been updated in the last five years, and this table has no dependencies. You can feel confident that it can be archived and doesn’t need to be migrated.
As an example, in the image below, we can see that taxi_trips doesn’t have any dependencies:
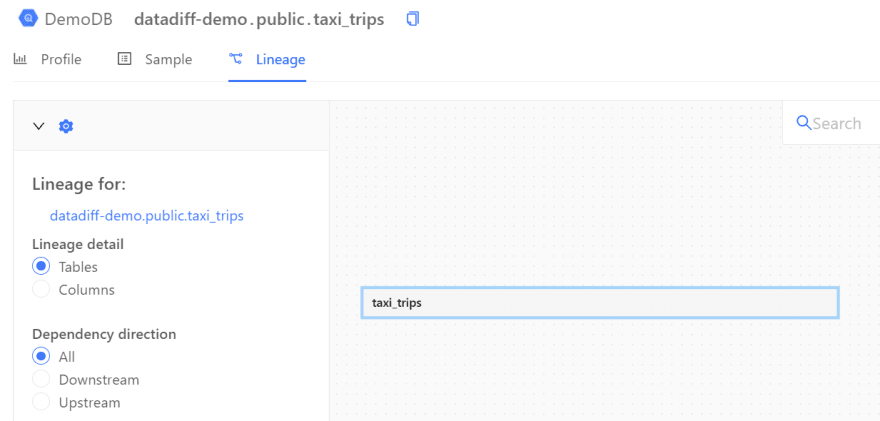
Migrating Old and Inefficient Queries
Engineers should be also looking for inefficient queries powering existing analytic reports. Not surprisingly, this is also often overlooked in fear of breaking applications.
For example, maybe you have a query with 10 joins, four of which are joining to obsolete data tables. The migration project can be the perfect time to optimize it by cutting out irrelevant joins. Showing side-by-side improvements can further showcase the value of planned migration to stakeholders.
Once again, the column-level lineage feature can help refactor or remove inefficient queries. Column-level lineage can show how a data field relates to its upstream and downstream objects, and what the effect will be when modifying queries containing this field.
In the image below, we can see that a data field is related to two tables. This should tell the data engineer which tables may be affected when fine-tuning a query containing this field.
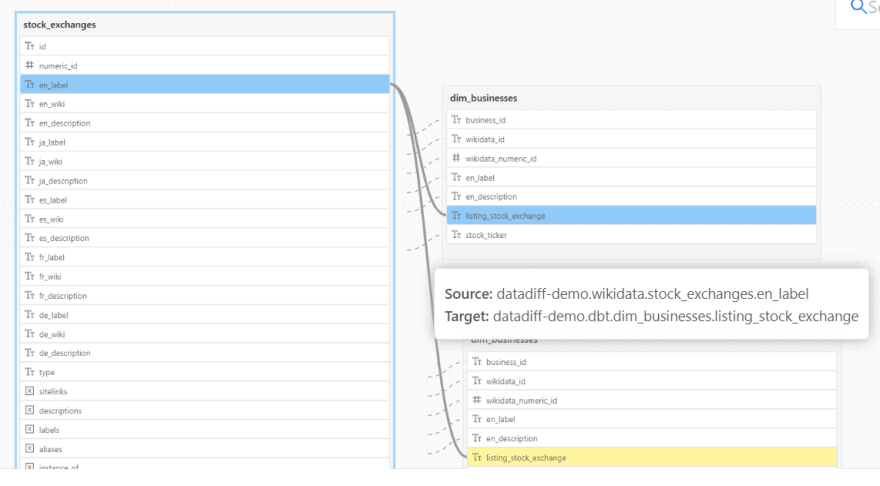
Datafold’s Data Diff feature can also show the potential impact of changing your old queries. Data Diff compares two datasets and can show if their schemas, primary keys, row counts, or column values are mismatched.
You can use such results for quality assurance of your migrated data. If the target Snowflake tables show no discrepancies, stakeholders can have confidence that the new queries are safe and effective. If the comparison shows differences, then the queries can be further fine-tuned.
In the images below, we see one such Data Diff operation. Here, the target table shows non-matching columns with non-matching values:
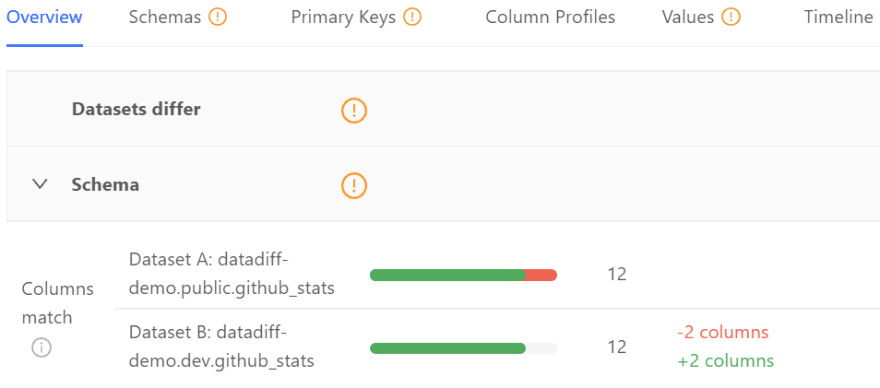

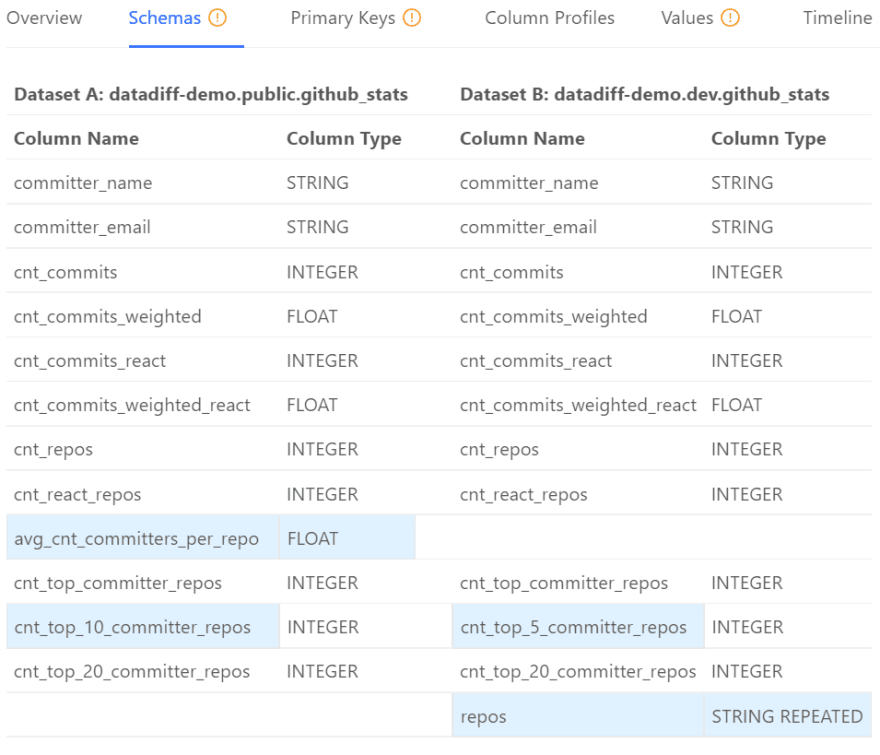
Manual or No Regression Testing
For organizations dealing with terabytes of data, manual testing and validation is a guaranteed recipe for failure. Manually cross-checking millions of rows of query results or data is simply not an option. The result is that many engineers will simply skip validation altogether.
According to the data engineers in Thumbtack, their manual validation process used to take up to two hours per pull request. In many cases, this validation just wasn’t realistic to complete and mistakes can be costly. There are two ways to eliminate—or largely automate—manual data validations when migrating data to Snowflake.
The first method is to use Datafold’s Alerting feature. Datafold uses machine learning to find the normal trend or seasonality in your data. You can configure alerts to send proactive messages to DataOps when anomalies are detected in that data. You can also adjust the alert thresholds.
You can create alerts by writing your own SQL statements for data completeness checks or comparisons, as shown below:
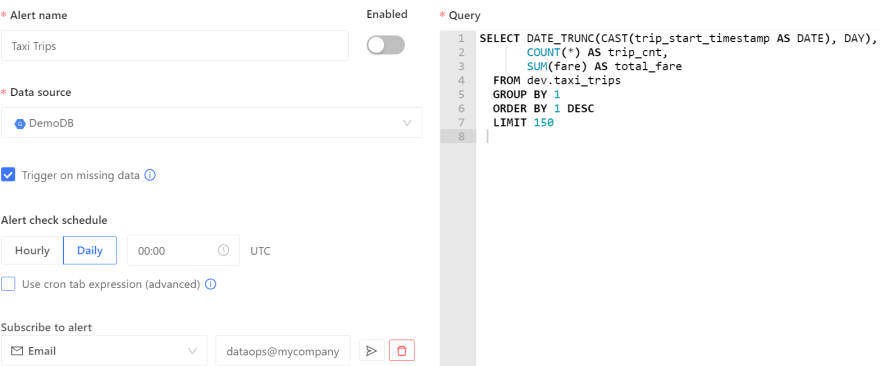
In both cases, proactive alerts can help data engineers fix any issues in the source data before migration.
The other option is to use the Data Diff feature within the CI process.
With this approach, after creating a data migration script, it’s committed to a Git repository. Once the commit is made to the development branch, a developer creates a pull request to merge the change to the main branch. At this stage, a senior team member can review the code to approve or reject it.
Now, when integrated with the CI process, Datafold’s Data Diff feature can show the reviewer the effect of the ETL code—how data will change between the source and the target as the code cleanses, aggregates, and performs its operation. This is automatic regression testing for the data pipeline.
If reviewers see the target table will have unwanted changes when the code runs, they can reject the change, preventing garbage data from entering the Snowflake database.
When Thumbtack started using Data Diff, they reported a savings of over 200 hours per month, increased productivity by at least 20%, and over 100 pull requests automatically tested every month.
Conclusion
There are many advantages to moving to a cloud data warehouse like Snowflake. However, migrating even a single database to a new system can have its challenges, especially when the source data hasn’t been profiled or the ETL code hasn’t been tested.
The key to successful data migration is leveraging tools that can automate most of the hard work. Datafold can help dramatically reduce the number of errors, failures, and silent issues by automating most of the testing.
Although we’ve focused on Snowflake in this article, the same features of Datafold can be used for other cloud products like Redshift or BigQuery.

Top comments (0)