Just to give you some context, we were working on the new Diabecarp App a few days ago. I can't talk much about the new features, but I am going to extrapolate 2 interesting solutions during the process, give you why, explain a bit and, as always, put together a demo with Rails ♥️.
First Requirement -
Recommendation engine
Without giving many details about the case itself, we have a very large amount of content. Various resources (such as Articles or Recipes). Therefore, we must find a way to organize it efficiently according to the user's interest. Come on, nothing new, right?
So, the first thing we did was ask ourselves, what do we have at our disposal to better understand the user and their interests? At this point, due to early stage, we can only use: likes and views.
The next thing we did was go over the different ways of understanding our user. And we opted for the one that seems simpler, and not for that less elegant.
🌎 Collaborative Filtering
It is based on the premise that we all have certain similarities, and therefore, likes and interests. And precisely this simplicity is what makes this algorithm extremely elegant.
Wikipedia: Collaborative filtering is a method of making automatic predictions (filtering) about the interests of a user by collecting preferences or taste information from many users (collaborating).
Most websites like Amazon, YouTube, and Netflix use collaborative filtering as a part of their sophisticated recommendation systems. You can use this technique to build recommenders that give suggestions to a user on the basis of the likes and dislikes of similar users.
Let's see with an illustration, surely they understand me instantly.

It is also very common to see this with Content Based Filtering, the same as with users, only here we compare the relationship of the content. Something like that:
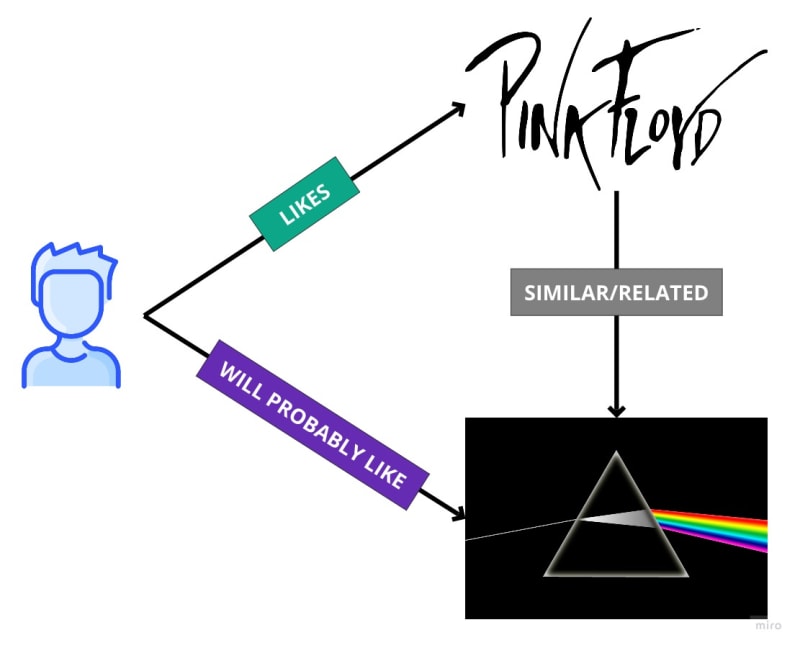
DISCLAIMER: For the rest of the article I will touch on both options, I just want to make it clear that the concept is the same, the similarity.
👉 Let's see an example of how to recommend similar content (in this case, songs).
First, we take each pair of songs in our database and calculate a similarity between the two songs. To find this similarity, we compared the lists of users who liked the two songs. If many people liked both songs, it is likely that they are quite similar. And if not many people liked both songs, they are probably less similar. A table of similarities could look like this:
| Another Brick in the Wall | Hey You | Time | |
|---|---|---|---|
| Another Brick in the Wall | 1 | ||
| Hey You | 0.7 | 1 | |
| Time | 0.2 | 0.1 | 1 |
Once we have this list of similarity scores between songs, it's pretty easy to provide recommendations. If a user is listening to a song, we can provide a "Similar Songs" list by simply finding the most similar songs in our previous metric.
Challenges with Collaborative Filtering
Basically, there are 2 big problems.
1.- Cold Start:
Starting without enough data, such as users and reactions of those users that allow us to multiply matrices and reach a good result (later).
This clear problem has a solution, only that we find a much simpler return. Basically, in the index of each resource (eg. Articles) we have a top section with 10 recommended articles and below the rest ordered by 'most recent'.
This is how we get those recent ones to get the traction they deserve. Here it can be automatically filtered to the top section or disappear completely. Finally, we filter those that the user already read and end.
2.- Scalability:
The more users and more data, the more expensive it becomes to compare these matrices.
As we do not have much time or resources, we decided to take this technical debt, considering that very possibly in the future we will have to migrate.
Now let's see a real implementation so that you can understand me.
There are already several gems developed for this need, yet several are old. I'm not 100% sure they still work, at the end of the day at Diabecarp we have another stack. Maybe we can write a new one in the future 😉
I choose the last one because the rest works with Redis and I no longer want to extend the post. Let's go! 👊
To find the similarity of two songs, we need to take the user IDs that liked each of the two songs, and compute: (size of intersection of sets) / (Jaccard similarity coefficient). Because we have to do this computation for every pair of songs, performance becomes important.
One strategy used by the Redis-based gems is to push the similarity computation into our datastore– we want to avoid the overhead of sending each pair of ID sets back and forth to our application server, especially if those are large sets. We also get extra performance points if our datastore has primitives that help make the similarity computation faster.
Fortunately, these are both problems that can be solved with a relational database. SQL is totally flexible enough to express a single query that computes many item similarities at once. Also, postgres happens to have a convenient extension called intarray which provides efficient intersection and union operations for arrays of integers.
Setup the gem...
Specify an ActiveRecord association to use for recommendation (./app/models/song.rb):
class Song < ActiveRecord::Base
has_many :likes
has_many :users, through: :likes
include SimpleRecommender::Recommendable
similar_by :users
end
And then you can call similar_items to find similar items based on who liked them:
song = Song.find_by(title: "Another Brick in the Wall")
song.similar_items(n_results: 3)
# => [#<Song id: 2, name: "Time">,
#<Song id: 3, name: "Hey You">,
#<Song id: 4, name: "Wish You Where Here">]
This scope is composing a query that operates on its join table, like a Like table with user_id and song_id. It uses common table expressions to create a temporary table with one row per pair of songs, and computes the similarity for each row of that table. That temporary table looks something like this:
| Song 1 Name | Song 1 User IDs | Song 2 Name | Song 2 User IDs | Similarity |
|---|---|---|---|---|
| Another Brick in the Wall | {1, 2, 3, 4, 5} | Hey You | {1, 3, 4, 5, 6} | 0.7 |
| Another Brick in the Wall | {1, 2, 3, 4, 5} | Time | {3, 8, 10, 12, 13} | 0.1 |
Then it just looks for the highest singularity and returns it.
Ok, that's it for today. In the following article I would like to talk about how we are using Bayesian Networks or even how we prepare for onboarding.
BTW, if you are interested in the project, we are still looking for devs!
👋 Bye

Top comments (0)