
Tema recomendado para la lectura:
Introducción
La sincronización de relojes en un sistema distribuido consiste en garantizar que los procesos se ejecuten de forma cronológica y a la misma vez respetar el orden de los eventos dentro del sistema.
Existen 2 tipos de relojes:
- Físicos: relacionado con el tiempo real.
- Lógicos. lo importante es el orden de los eventos, no en el tiempo que ocurren.
Dentro de los relojes físicos encontramos 2 tipos de sincronizacion:
- Externa: los relojes se sincronizan con una fuente de tiempo externa fiable.
- Interna: los relojes no se sincronizan con una fuente de tiempo externa.
Algoritmos
Cristian
- Para relojes físicos con sincronizacion externa.
El algoritmo de Cristian es un método, dentro de la computación distribuida, para la sincronizacion de relojes. Consiste en un servidor conectado a una fuente de UTC y unos clientes que se sincronizan con dicho servidor.
Funcionamiento
- Un proceso p hace una petición de tiempo al servidor en un mensaje mr.
- Al momento de enviar la peticion guarda una marca tiempo Tr de ese momento.
- El servidor responde con un mensaje mt en el que incluye su tiempo Tutc.
- El proceso que recibe el mensaje mt guarda la marca de tiempo de llegada Tt.
- El proceso debe hacer una estimación previa a actualizar su reloj, debido al tiempo de transmisión del mensaje por la red. Tutc + RTT/2 = Tcliente, donde RTT= (Tt - Tr).
- El proceso p actualiza su reloj con Tcliente.

Inconvenientes
- Presenta la posibilidad de fallo debido a la existencia de un único servidor. Cristian sugiere múltiples servidores de tiempo sincronizados que suministren el tiempo. El cliente envía a un mensaje de petición a todos los servidores y toma la primera respuesta recibida.
- El algoritmo no contempla problemas de mal funcionamiento o fraude por parte del servidor.
Berkeley
- Para relojes físicos con sincronizacion interna.
Se creo para entornos en los cuales no se tienen fuentes de tiempo UTC, gracias a este algoritmo los relojes del entorno puedan mantenerse sincronizados de igual manera. Es un algoritmo centralizado, ya que el servidor se va a elegir entre todos los nodos del entorno, así quedando un maestro y resto serán todos esclavos. La esencia del algoritmo es que el maestro solicita a los esclavos su hora periódicamente para así poder obtener la diferencia promedio entre todas las horas (incluyendo la propia hora del maestro), así el maestro envía esa diferencia promedio a todos los esclavos, y todos incluido el maestro actualizan sus horas.

Funcionamiento
Depende del libro o la fuente en donde aprende este algoritmo puede variar si el coordinador de tiempo es quien obtiene la diferencia individual entre su hora con cada esclavo o si el cliente ya le da la diferencia, de igual manera, al final resulta ser lo mismo, en el algoritmo hay un coordinador activo que solicita las horas para actualizarlas, no como en el método de Cristian que el coordinar o coordinadores son pasivos. En los pasos yo opte por que el cliente pase la diferencia. Ahí vamos:
- Coordinador solicita el tiempo de los esclavos pasando su propio tiempo Tmaestro.
- Los esclavos devuelven la diferencia entre el tiempo del maestro Tmaestro recibido en el mensaje y su tiempo Ten (Tiempo de esclavo n). Es como decir "estoy así de lejos de ti coordinador". La formula seria DEn = Tmaestro - Ten, donde DTn significa Diferencia de Tiempo n.
- El coordinador recibe todas las DTn y tiene su propia diferencia de tiempo también que es 0, ya que el participa en la operación.
- El coordinador hace un promedio con todas las diferencias de tiempo y obtiene la diferencia de tiempo promedio DTP.
- El coordinador recuerda esta DTP y se las envía a los esclavos. Y ahora todos realizan la siguiente formula para actualizar sus relojes RELOJnuevo = [DTn + (DTP)] + RELOJactual.
Recordar que para las operaciones las variables son tiempo, hay que respetar sus unidades.
Inconvenientes
- En caso de que el maestro falle, dejará de preguntar la hora y, en consecuencia, se perderá la sincronización.
- En el paso de mensajes entre maestro y esclavos y viceversa se ha de tener en cuenta el retraso que genera el propio envío de los mensajes por lo que tendremos errores a la hora de sincronizar.
- Otro de los problemas de ser un algoritmo centralizado será el de tener que elegir un nuevo maestro debido a que se puedan producir fallos en el tratamiento de los datos para llevar a a cabo la sincronización, buscando un maestro que cometa menor cantidad de fallos y el sistema se mantenga en correcto funcionamiento.
Protocolo de tiempo de red
- Para relojes físicos con sincronizacion externa.
Network Time Protocol (NTP) es un protocolo de Internet para sincronizar los relojes de los sistemas informáticos a través del enrutamiento de paquetes en redes con latencia variable. NTP utiliza UDP como su capa de transporte, usando el puerto 123. Está diseñado para resistir los efectos de la latencia variable. Es principalmente utilizado sobre Internet a diferencia de Cristian y Berkeley que usan mas a menudo en intranets.
Los objetivos y características de diseno de NTP son:
- Proporcionar un servicio habilitando a los clientes a través de Internet ser sincronizados precisamente a UTC.
- Para proporcionar un servicio confiable que pueda sobrevivir a largas pérdidas de conectividad.
- Para permitir que los clientes se vuelvan a sincronizar con la frecuencia suficiente para compensar las tasas de deriva que se encuentran en la mayoría de las computadoras.
- Para proporcionar protección contra interferencias con el servicio horario, ya sea malicioso o accidental.
El servicio NTP es proporcionado por una red de servidores ubicados en internet.
- Los servidores primarios: conectados directamente a la fuente de tiempo UTC.
- Los servidores secundarios: son sincronizados, en ultima instancia, con los primarios.
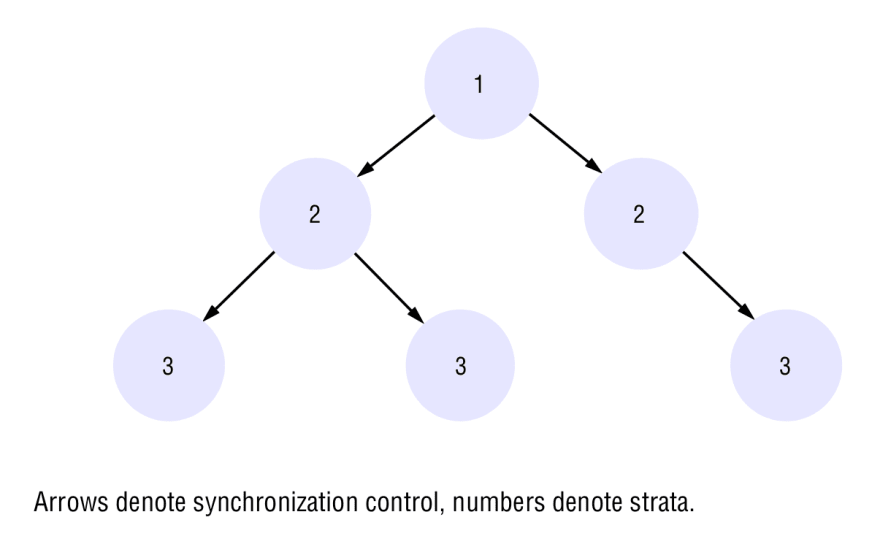
Estos servidores son conectados es una jerarquía lógica llamada subred de sincronizacion. Cuyos niveles se llaman estratos.
- Los relojes UTC están en el estrato 0.
- Los servidores primarios ocupan el estrato 1. Son la raíz.
- Los servidores secundarios ocupan el estrato 2. Y son sincronizados con los primarios.
- Los servidores que ocupan el estrato 3 se sincronizan con los del estrato 2.
- Y así hasta el estrato n.
- Los servidores de nivel más bajo (hoja) se ejecutan en las estaciones de trabajo de los usuarios.
Lamport
- Para relojes lógicos.
Para sincronizar relojes lógicos, Lamport definió una relación llamada ocurrencia anterior. La expresión a -> b se lee como "a ocurre antes que b". Esta relación de ocurrencia puede verse en 2 situaciones:
- Si a y b son eventos del mismo proceso, y a ocurre antes que b, entonces a -> b es verdadera.
- Si a es el evento en el que un proceso envía un mensaje, y b es el evento de recepción del mensaje por otro proceso, entonces a->b también es verdadero.
2 conceptos importantes
- La ocurrencia anterior es una relación transitiva, por lo que si a->b y b->c, entonces a->c.
- Si 2 eventos x y y ocurren en 2 procesos diferentes que no intercambian mensajes (ni siquiera indirectamente), entonces x->y no es verdadera, ni tampoco y->x, entonces se dice que estos eventos son concurrentes.
Las reglas del algoritmo
Lo que se necesita es una manera de medir la noción de tiempo del tal forma que a cada evento a podemos asignarle un valor de tiempo C(a) en el que todos los procesos coincidan. Estos valores de tiempo deben tener la propiedad de que si a->b, entonces C(a) < C(b).
Ademas, el tiempo de reloj C solo incrementa, nunca disminuye. Solo es posible hacer correcciones agregando un valor positivo.
Funcionamiento
Consiste en dos momentos, cuando:
- envía un evento: el proceso debe incrementar su reloj y enviar su tiempo.
- recepción de evento: el proceso debe comparar entre su tiempo actual y el que recibió, al máximo entre ellos incrementarlo y tomarlo como su nuevo tiempo.

Vectorial
Lamport dio una buena solución, pero no es la bala de plata, la ocurrencia anterior no asegura que siempre a -> b, miremos el siguiente ejemplo:
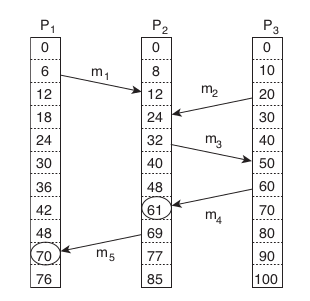
Mas allá del orden de las flechas y los numeros, m1 y m2, con el algoritmo de Lamport usted que dice, m1->m2 o m2->m1?
El problema de los relojes de Lamport es que no capturan la causalidad. Esta causalidad si puede ser capturada por los relojes vectoriales.
En que consisten?
Consiste en que cada proceso tiene un contador o reloj de tiempo vectorial de cada proceso en el sistema. Es decir si tenemos 3 procesos, cada proceso tendrá un reloj vectorial con 3 posiciones, así cada uno sabe del orden de eventos del otro.
Funcionamiento
Consiste en dos momentos, cuando:
- envía un evento: el proceso debe incrementar su propio reloj y enviar el reloj vectorial.
- recepción de evento: el proceso debe comparar entre los tiempo actuales con los tiempos que recibió (menos al suyo), al máximo entre ellos dejarlo en su reloj vectorial. Su tiempo solamente debe incrementarlo.
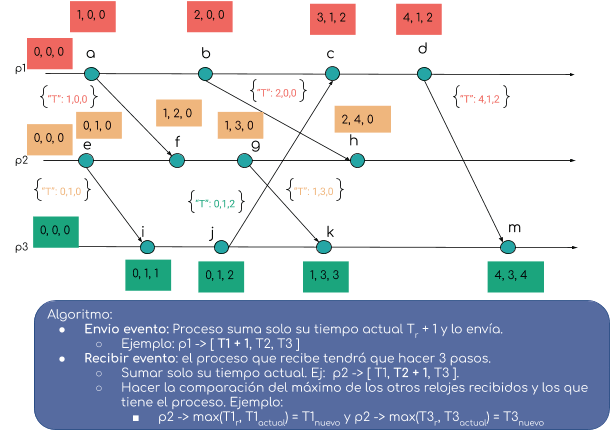
Ahora un buen tema y a relajar!

Top comments (0)