
In machine learning, one of the most repeated tasks is classifying objects to certain criteria, into multiple categories.
Examples of Classification problems
- is this email spam or not?
- is this a dog or a cat?
- is the stock going up or down?
How SVM works?

Each object you want to classify is represented as a point on plane or let's call it an n-dimensional space
where each coordinate is a feature of the classification process.
SVMs handles the classification tasks by drawing a line dividing the dataset into two groups

and if it's a 3 dimensional plane. it draws a plane like this

and since there are many possibilities to draw a line or a plane that divides the data, SVM tries to find the most fitting line.

SVM create a margin which is a space around the dividing line.
to maximize the distance to points in either categories. and the points that fall on the margin are called the supporting vectors.
SVM needs a dataset which is labeled, that's why SVM is supervised learning algorithm. which means it requires both X (Features) and Y (Output) Values.
SVM solves a convex optimization problem which is also known as a Cost Function
SVM pros & cons
SVM is simple, easy to understand and interpret, easy to use and implement. it also can perform well with small datasets.
yet its simplicity is not always the best.
not all data can always be split by a plane.

A common workaround to this problem is called the Kernel Trick
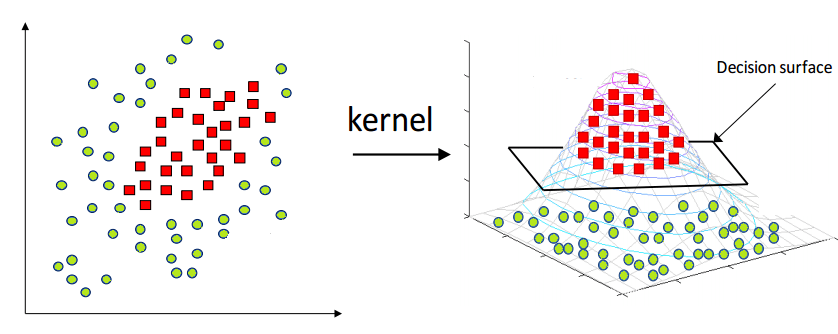
we can augment data with some nonlinear features that are computed from the existing ones. then find the seperating hyperplane.
you can now start implementing SVM models using scikit learn.
opening a lot of doors for a variety of ML applications.





Top comments (0)