This post contains a collection of code snippets you can paste into the browser’s console and get useful data back. It’s like scraping a web page, but instead of doing it inside a Node script, you do it in the browser’s console. Because you shouldn’t run code that you don’t understand in your console, I explain how most of the snippets work. As a result, you may learn some JavaScript tricks you haven’t seen before, learn how to accomplish basic tasks without using a framework/library (the code is not optimized for performance though), and extract some useful data from the pages you visit. Before we see the code, I want to explain some syntax you’ll encounter throughout the snippets.
In the browser, the $ function is an alias for document.querySelector. For example, if you run $('body') in the console, you’ll get back the body element which is the same as running document.querySelector('body'). The $$ is the equivalent for document.querySelectorAll. I use both of those aliases to save some space in the code snippets.
The $$ returns a NodeList that lacks many of the useful array methods such as map and filter. For that reason, I use the Array.from(notAnArray) method to transform it into an array.
I also use the Set constructor new Set(array) that returns a Set object that contains all the unique values inside an array. Here, we face the same issue with the $$ alias, so I transform the Set to an array with the Array.from method.
Table of contents
- Show outlines to find overflows
- Get all the different tags used in a page
- Typography
- Add an external library
- Extract more CSS properties from a page
- Show me the code
- Get all the links from a page
- Images
- Dark mode DIY
- Show duplicated ids
Show outlines to find overflows
Find which elements cause overflows by adding a red outline to all the body elements. This can also help you understand how inline elements work.
Array.from($$("body *")).forEach((el) => {
el.style.outline = "1px solid red";
});
Get all the different tags used in a page
It’s not the most exciting one, but you may discover new elements to use or at least see what elements other sites use.
Array.from(
new Set(Array.from($$("body *")).map((el) => el.tagName))
).sort();
You get all the elements inside the body element with $$("body *") call that returns a NodeList, you make it an array, you transform that element array to an array with the tag names (strings), you keep only the unique tags with the Set constructor, and finally, you transform the Set to an array. The sort() call at the end sorts the array in alphabetical order.
Typography
Print a table with all the characters
See what characters a website uses. Use this if you want to adjust the font files by creating subsets to make sure they cover those characters.
Array.from($$("body *")).filter(
(tagName) =>
![
"defs",
"style",
"STYLE",
"IFRAME",
"path",
"g",
"svg",
"SCRIPT",
"NOSCRIPT",
"",
].includes(tagName)
);
You start by getting all the elements inside the body and filter out those elements that don’t contain human-readable text, for example, scripts, styles, iframes, etc.
Array.from($$("body *"))
.filter(
(tagName) =>
![
"defs",
"style",
"STYLE",
"IFRAME",
"path",
"g",
"svg",
"SCRIPT",
"NOSCRIPT",
"",
].includes(tagName)
)
// See here
.map((el) => el.innerText)
.filter(Boolean)
.join("")
.split("");
You transform the elements (with map) to an array that contains their inner texts, you keep only the values that are truthy with filter(Boolean)—this will remove empty strings (""), undefined, and more—and you transform it into an array of characters with the join("") and split("") array methods. join("") joins the array into a string value without a separator, and split("") splits that string into an array that contains individual characters.
console.table(
Array.from(
new Set(
Array.from($$("body *"))
.filter(
(tagName) =>
![
"defs",
"style",
"STYLE",
"IFRAME",
"path",
"g",
"svg",
"SCRIPT",
"NOSCRIPT",
"",
].includes(tagName)
)
.map((el) => el.innerText)
.filter(Boolean)
.join("")
.split("")
)
)
// See here
.map((char) => char.codePointAt())
.sort((a, b) => a - b)
.map((codePoint) => ({
unicode: codePoint.toString(16).toUpperCase(),
character: String.fromCodePoint(codePoint),
}))
);
Keep only the unique characters (with Set), transform the characters to code points and sort them, and finally, print the result. The result is an array with the characters, along with their Unicode hex numbers.
See what fonts a website uses
Or, more specifically, get the different values of the font-family CSS attributes of all body elements. You accomplish that with the help of the getComputedStyle method:
new Set(
Array.from($$("body *")).map((el) => getComputedStyle(el).fontFamily)
);
In case you’re wondering, you cannot do the same with el.style because the CSS properties of that object are not populated from the stylesheets. el.style is used for setting properties with JavaScript. See all the differences between getComputedStyle and el.style.
Firefox developer tools do a much better job at this task with the Fonts tab, that’s inside the Inspector tab.
More typographic data
Get the font families and the different font sizes that are used in:
console.table(
Array.from(
new Set(
Array.from($$("body *")).map((el) => {
var { fontFamily, fontSize } = getComputedStyle(el);
// Notice this line
return JSON.stringify({ fontFamily, fontSize });
})
)
)
// And this line (see below for an explanation)
.map((uniqueKey) => JSON.parse(uniqueKey))
.sort(
(a, b) =>
a.fontFamily.replace('"', "").toUpperCase().codePointAt() -
b.fontFamily.replace('"', "").toUpperCase().codePointAt()
)
);
The Set constructor finds the unique values from arrays that contain primitive values. In this case, we want both the family and the size of an element, so the first thought might be to create an object for each element and store that information there. If you do that, Set will not work because it will compare the objects by reference, not by the inner value to find if they are unique. For this reason, you serialize the object to a string with JSON.stringify and later transform it back to an object with JSON.parse (see the highlighted lines).
I have a post that tackles a similar issue which is the difference between deep/shallow copy and the assignment operator. It contains useful references to other resources to learn more about the subject.
Highlight characters from a specific script
A use case for me is that some Greek characters are identical to Latin, for example, Τ/T or O/Ο. This code helps me find these small mistakes I make while writing text.
var regEx = /\p{Script_Extensions=Latin}/gu;
Array.from($$("h1, h2, h3, h4, p"))
.filter((el) => regEx.test(el.innerHTML))
.forEach((el) => {
el.innerText = el.innerText.replace(regEx, "$&\u0332");
});
Regular expressions are not the most readable code in the world, but they have some cool features. One of them is the Unicode property escapes (e.g: /\p{property}/u). You can use them in regular expressions to find characters from a specific script, emojis, punctuation marks, and more—see the link for more properties. Don’t forget to add the Unicode flag (u) when you use Unicode property escapes. I’m also using $& in the string replace method to refer to the matched string.
I mark the characters with the mark Unicode character (combining low line u+0332). I initially thought to parse the HTML of the elements (not the innerText) with regular expressions and wrap the characters with <mark> elements, but, as it turns out, parsing HTML with regular expressions is probably a bad idea.
Test a font
See how a Google Font looks on a page. To do that, you create a style element, you add it inside the head element, and you use it.
var ibmSans = Object.assign(document.createElement("link"), {
href:
"https://fonts.googleapis.com/css2?family=IBM+Plex+Sans:ital,wght@0,400;0,700;1,400;1,700&display=swap",
rel: "stylesheet",
});
document.head.appendChild(ibmSans);
// Use the font
Array.from($$("body, h1, h2, h3")).forEach((el) => {
el.style.fontFamily = "'IBM Plex Sans', sans-serif";
});
In the previous example, I use a “trick” with Object.assign to create an element that looks like the React API for creating elements, for example:
// This
var redDiv = Object.assign(document.createElement("div"), {
style: "background-color: red; width: 100px; height: 100px;",
});
// Looks similar to this React.createElement(tag, props, children)
var redDiv = React.createElement(
"div",
{
style: {
backgroundColor: "red",
width: "100px",
height: "100px",
},
},
null
);
Add an external library
Vanilla JavaScript is cool, but sometimes you wish you had access to an external library to help you do the job. In the following example, you can add lodash with an external script from unpkg:
var script = document.createElement("script");
script.src = "https://unpkg.com/lodash@4.17.20/lodash.js";
script.onload = () => {
console.log(_.map([1, 2, 3], (n) => n * 2));
};
document.head.appendChild(script);
// prints [2, 4, 6] when the script loads
The code above shows how to add an external script to a page with JavaScript. To add a different library from NPM, replace the :package from the following snippet with the package name, enter the URL in the browser, and unpkg will redirect you to the correct file. If not, you’ll have to browse the directory to find the file yourself, and in this case, don’t forget to remove the /browse/ from the URL:
unpkg.com/:package@latest
# And the original sample from unpkg:
unpkg.com/:package@:version/:file
Extract more CSS properties from a page
With the following snippet, you get all the different box shadows, but you can use it for any other CSS property you’re interested in.
Array.from(
new Set(
Array.from($$("body *")).map((el) => getComputedStyle(el).boxShadow)
)
).sort();
Or create an object with the box shadows, colors, borders, and background images.
Object.entries(
Array.from($$("body *")).reduce(
(data, el) => {
const style = getComputedStyle(el);
data.boxShadows.add(style.boxShadow);
data.colors.add(style.color);
data.colors.add(style.backgroundColor);
data.borders.add(style.border);
data.borders.add(style.borderTop);
data.borders.add(style.borderRight);
data.borders.add(style.borderBottom);
data.borders.add(style.borderLeft);
data.backgroundImages.add(style.backgroundImage);
return data;
},
{
boxShadows: new Set(),
colors: new Set(),
borders: new Set(),
backgroundImages: new Set(),
}
)
).map(([key, values]) => ({
[key]: Array.from(values)
.sort()
.filter((cssVal) => cssVal && cssVal !== "none"),
}));
Show me the code
Show all the elements that are usually hidden. More specifically, this snippet shows all the head elements, and from the body, it shows the scripts, styles, and noscript elements.
document.querySelector("head").style.display = "block";
Array.from(
$$("head > *, body script, body style, body noscript")
).forEach((el) => {
var pre = document.createElement("pre");
var code = document.createElement("code");
pre.style.backgroundColor = "black";
pre.style.color = "white";
pre.style.padding = "1em";
pre.style.marginBottom = "1.5em";
pre.style.overflowX = "auto";
pre.style.zIndex = 9999;
code.style.backgroundColor = "inherit";
code.style.color = "inherit";
pre.appendChild(code);
code.appendChild(el.cloneNode(true));
el.insertAdjacentElement("afterend", pre);
code.innerText = code.innerHTML;
});
In the previous snippet, you create a pre and a nested code element, and you style them. You also add the code in plain text inside the code element (see below how). The plan is to use them like this:
<pre>
<code>
// How to greet from the console.
console.log("Hello world");
</code>
</pre>
You use the insertAdjacentElement method to insert the <pre> right after the original element. The alternative is to get the parent node of the element with el.parentNode and append a child with the appendChild method. You set the code element’s inner text to its inner HTML which is the original (cloned) element’s HTML. If you don’t use the cloneNode() method to create copies of the original elements, the scripts and the styles will be rendered useless, and the page will not work as before.
Infinite scrollers, default styles on <pre> elements, and fixed elements can mess-up the result.
Get comments from inline scripts and styles
I’m not sure why you’d want to use this; maybe to read the licenses and the inner thoughts of your fellow developers? My favorite comments are the DO NOT CHANGE, all in caps of course.
Array.from(document.querySelectorAll("script, style"))
.map((el) => el.textContent)
.filter(Boolean)
.reduce((result, code) => {
var weirdRegEx = /(?<!:)(?<comment>\/{2}.*?)\n|(?<commentMulti>\/[*\s]*\*[\s\S]+?\*[*\s]*\/)/g;
var comments = [];
for (let match of code.matchAll(weirdRegEx)) {
var comment = match.groups.comment || match.groups.commentMulti;
comments.push(comment);
}
return result.concat(comments);
}, []);
The regular expression for single-line comments gives many false positives though. For example, it may return base64 encoded data that match.
You could use either of textContent and innerText to get the text of styles and scripts, so it doesn’t matter which one you choose in this case. See all the differences between textContent and innerText.
This is a visualization of the regular expression for single-line comments created by the Regulex app. The (?<name>thing to name) creates a named capturing group that is easier to access via match.groups.name instead of match[1].
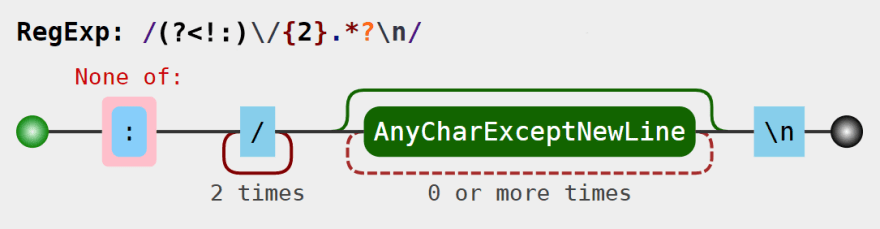
// Single-line comment
And this is a visualization of the regular expression for multiline comments:

/*
Multiline
comment
*/
The dot special character . in regular expressions matches all characters except newlines. To match all characters including newlines, you can use [\s\S].
Get all the links from a page
Print the URLs and the text of the links in a table. Screen readers offer something similar with the rotor function:
console.table(
Array.from(
new Set(
Array.from($$("a"))
.map((link) =>
link.href
? JSON.stringify({
url: link.href,
text: link.innerText,
})
: null
)
.filter(Boolean)
)
)
.sort()
.map((serialized) => JSON.parse(serialized))
);
If you don’t like the table from console.table, you can use a regular console.log. In Chrome’s console, you can resize the columns of the table and sort the data by column.
Images
Display only the images
Display only the image elements inside the page’s body—it removes the body content.
var images = document.querySelectorAll("img");
var body = document.querySelector("body");
body.innerHTML = "";
body.style.overflow = "auto";
images.forEach((img) => {
var wrapper = document.createElement("div");
wrapper.appendChild(img);
body.appendChild(wrapper);
});
Show background images too and change styling
I have a more elaborate solution because the images many times have some default styling, such as absolute positions or weird widths. If you want a more consistent result, it’s better to create new image elements. This also creates image elements for the background images:
var images = document.querySelectorAll("img");
var backgroundImages = Array.from(document.querySelectorAll("body *"))
.map((el) => getComputedStyle(el).backgroundImage)
.filter((css) => css !== "none")
.map((css) => ({
// The .*? in the middle will match zero or more characters,
// but as few as possible (non-greedy, greedy is the default).
// If you use .* it will consume the ending quote and the URL
// will be invalid.
src: css.match(/url\(["']?(.*?)["']?\)/)?.[1],
alt: null,
}));
var body = document.querySelector("body");
body.innerHTML = "";
body.style.overflow = "auto";
var elements = Array.from(images)
.concat(backgroundImages)
.filter(({ src }) => src)
.map((img) => {
var newImage = document.createElement("img");
newImage.src = img.src;
newImage.alt = img.alt || "";
newImage.title = img.alt || "";
newImage.style.display = "block";
newImage.style.width = "auto";
newImage.style.outline = "1px dashed red";
return newImage;
});
body.append(...elements);
I use append because I want to add multiple elements at once—see all the differences between append and appendChild. You can render the images in a mosaic layout (kind of) if you add some flex styles to the body element:
body.style.display = "flex";
body.style.flexWrap = "wrap";
body.style.alignItems = "flex-start";
This is a visualization of the regular expression for background image URLs:
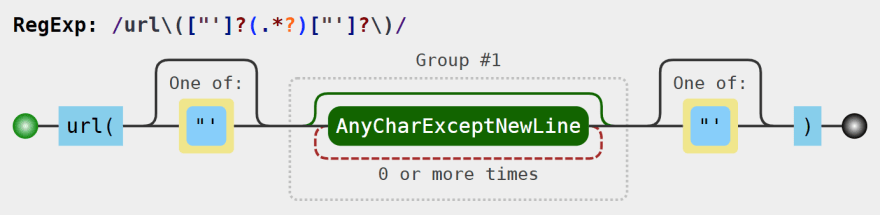
Dark mode DIY
This trick uses the invert CSS filter to create a dark mode if the site doesn’t offer the option. I first saw it in a post on how to create a theme switcher by Heydon Pickering.
var filter = "invert(1)";
var root = document.querySelector("html");
root.style.backgroundColor = "white";
root.style.filter = filter;
var allElements = Array.from(document.querySelectorAll("body *"));
allElements.forEach((el) => (el.style.backgroundColor = "inherit"));
var media = Array.from(
document.querySelectorAll('img:not([src*=".svg"]), video')
);
media.forEach((el) => (el.style.filter = filter));
Show duplicated ids
Ids on a page should be unique and it may be hard to notice if you don’t test with a tool like axe or Lighthouse. Duplicate ids are not always the result of your code; external libraries can cause them too. This snippet will help you identify this issue.
var elementsWithIds= Array.from($$("[id]"));
var ids = elementsWithIds.map((el) => el.getAttribute("id"));
console.log({
elementsWithIds,
uniqueIds: new Set(ids),
duplicateIds: ids.filter((el, index) => ids.indexOf(el) != index),
});





Top comments (0)