
Hello! It's been 6 months that I started my new role as a Data Engineer and I'm excited to work with the best tools to build ETL pipelines at work. One of them is Apache Spark. I'll share my knowledge on Spark and this post the we'll discuss
- The Origins of Big Data Processing
- Hadoop MapReduce
- Hadoop's Shortcomings
- What is Spark?
- Spark's Way Of Doing Things
- Spark Ecosystem
- Spark Components
- Use Cases
- References
- #100DaysOfDataEng and Beyond
1. The Origins of Big Data Processing
The origin of the internet in 1989 enabled us to produce and consume data in all forms of life. This ensured a huge boom in data and in the following years essentially every organization and app became data reliant regardless of their scale.
Big Data/Data Engineering, which deals with the Collection, Processing and Storage of huge volumes of data became a matter of prime importance for business applications. For operational efficiency, demand prediction, user behavior, and other use cases like fraud detection, we need data and also in correct format. This is also know as ETL or Extract(Collection), Transform(Processing) and Load(Storage).
At this inflection point of data growth traditional tools (ex: Relational Databases) fell short this kind of new tasks which required processing petabytes scale datasets and providing the results quickly. This was very pronounced at companies like Google, which essentially crawls the whole internet and indexes the webpages for search results at planetary scale.
Google then came up with a very clever solution to their ever growing data problems called MapReduce, which later became Apache Hadoop; and later on it went on to became the watershed moment in Big Data Processing and Analytics.
2. Hadoop MapReduce
A MapReduce program is composed of a map procedure, which performs filtering and sorting (such as sorting students by first name into queues, one queue for each name), and a reduce method, which performs a summary operation (such as counting the number of students in each queue, yielding name frequencies).
The "MapReduce System" (also called "infrastructure" or "framework") orchestrates the processing on distributed servers, running the various tasks in parallel, managing all communications and data transfers between different parts of the system, and providing for redundancy and fault tolerance.
This initially solved the problems like building a large clusters of data and processing it. But this solution had a huge efficiency problem over time and as the data grew exponentially.
3. Hadoop's Shortcomings
The verbose batch-processing MapReduce API, cumbersome operational complexity, brittle fault tolerance became evident while using Hadoop. With large batches of data jobs with many pairs of MR tasks, each pair’s intermediate computed result is written to the disk. This repeated disk I/O took large MR jobs hours on end, or even days.

Intermittent iteration of reads and writes between map and reduce
computation
4. What is Apache Spark?
Spark is a unified engine designed for large-scale distributed data processing, on premise data centers or in the cloud. Spark provides in-memory storage for intermediate computations, making it much faster than Hadoop MapReduce.
5. The Spark Way Of Doing Things
Spark achieves simplicity by providing a fundamental abstraction of a simple logical data structure called a Resilient Distributed Dataset (RDD) upon which all other higher-level structured data abstractions such as DataFrames and Datasets are constructed. By providing a set of transformations and actions as operations, Spark offers a simple programming model that you can use to build big data applications in familiar languages.
Once an application is built using transformations and actions Spark offers, it builds its query computations as a Directed Acyclic Graph (DAG); its DAG scheduler and query optimizer construct an efficient computational graph that defines the path of execution and can usually be decomposed into tasks that are executed in parallel across workers on the cluster.

A typical Direct Acyclic Graph(DAG) in Spark
6. Spark Ecosystem
Spark supports the following
traditional RDBMS like MySQL, PostgreSQL and etc., NoSQL
- Relational Databases like MySQL and PostgreSQL
- NoSQL Databases like Apache HBase, Apache Cassandra and MongoDB
- Apache Hadoop
- Distributed Event Streaming Platform like Apache Kafka
- Delta Lake
- Elastic Search Engine
- Redis Caching Database and many more...

Apache Spark’s ecosystem of connectors
7. Spark Components and APIs
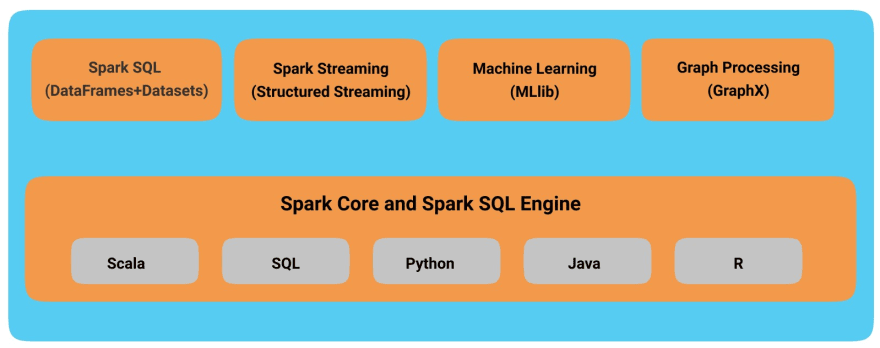
Spark Components and API Stack
Spark Supports languages like
- Scala
- SQL
- Python - PySpark
- Java
- R
7.1. Spark SQL
Spark SQL works well with structured data and you can read data stored in an RDBMS table or file formats with structured data like CSV, text, JSON, Avro, ORC, Parquet and etc.
We can write the SQL queries and access the resulting data as a Spark Dataframe.
// Spark SQL Example
// In Scala
// Read data off Amazon S3 bucket into a Spark DataFrame
spark.read.json("s3://apache_spark/data/committers.json")
.createOrReplaceTempView("committers")
// Issue a SQL query and return the result as a Spark DataFrame
val results = spark.sql("""SELECT name, org, module, release, num_commits
FROM committers WHERE module = 'mllib' AND num_commits > 10
ORDER BY num_commits DESC""")
//Note: You can write similar code snippets in Python, R, or Java,
//and the generated bytecode will be identical,
//resulting in the same performance.
7.2. Spark MLlib
Spark comes common machine learning (ML) algorithms library called MLlib. It provides many popular machine learning algorithms built on top of high-level DataFrame-based APIs to build models.
These APIs allow you to extract or transform features, build pipelines (for training and evaluating), and persist models (for saving and reloading them) during deployment. Additional utilities include the use of common linear algebra operations and statistics.
Note: Starting with Apache Spark 1.6, the MLlib project is split between two packages: spark.mllib and spark.ml. spark.mllib is currently under maintenance mode and all new features go into spark.ml.
# Spark ML library example
# In Python
from pyspark.ml.classification import LogisticRegression
...
training = spark.read.csv("s3://...")
test = spark.read.csv("s3://...")
# Load training data
lr = LogisticRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
# Fit the model
lrModel = lr.fit(training)
# Predict
lrModel.transform(test)
...
7.3. Spark Structured Streaming
Spark Continuous Streaming model and Structured Streaming APIs, built atop the Spark SQL engine and DataFrame-based APIs.
It is necessary for big data developers to combine and react in real time to both static data and streaming data from engines like Apache Kafka and other streaming sources, the new model views a stream as a continually growing table, with new rows of data appended at the end. Developers can merely treat this as a structured table and issue queries against it as they would a static table.
Underneath the Structured Streaming model, the Spark SQL core engine handles all aspects of fault tolerance and late-data semantics, allowing developers to focus on writing streaming applications with relative ease.
7.4. GraphX
GraphX is a library for manipulating graphs (e.g., social network graphs, routes and connection points, or network topology graphs) and performing graph-parallel computations.
It offers the standard graph algorithms for analysis, connections, and traversals, contributed by users in the community: the available algorithms include PageRank, Connected Components, and Triangle Counting.
8. Spark Use Cases
- Processing in parallel large data sets distributed across a cluster
- Performing ad hoc or interactive queries to explore and visualize data sets
- Building, training, and evaluating machine learning models using MLlib
- Implementing end-to-end data pipelines from myriad streams of data
- Analyzing graph data sets and social networks
9. References
- I'm using Learning Spark, 2nd Edition by Jules S. Damji, Brooke Wenig, Tathagata Das and Denny Lee for gaining my Spark knowledge. This article includes examples and images from the same.
10. #100DaysOfDataEng and Beyond
In the upcoming post we'll discuss about how Spark Distributed Execution works and later on we'll explore standalone Spark application example, how Spark is used to build and maintain ETL pipelines at scale.
Recently, I've taken up #100DaysOfDataEng Challenge on Twitter! 🙂 Please Like, Share and Follow for more updates. Thanks you! 🙂
Day 1/100:
— mani #CloudDog☁️#DataDog📊 (@maninekkalapudi) September 7, 2020
📊Started with basic concepts on #apachespark
📊 Installed Spark on my local Windows Machine in Local mode
📊 Read about building blocks of Spark such as Spark driver, SparkSession, Spark Executor n Cluster Manager#100DaysOfDataEng#100DaysOfCloud #CodeNewbie

Top comments (0)