In recent years, the Modern Data Stack, a suite of frameworks and tools has emerged in the world of Data and Business Intelligence and is dominating in enterprise data; Data Lakes and Warehouses, ETL and Reverse tools, Orchestration, Monitoring and much more.
One big unfilled hole in the MDS is Enterprise AI. Machine learning is dominated by Python tools and libraries. There have been attempts to transpile Python code to SQL for the MDS, but it is highly unlikely that Data Scientists will start performing dimensionality reduction, variable encodings, and model training/evaluation in user-defined functions and SQL.
MDS; a SQL centric paradigm.

SQL is ubiquitous across the modern data stack, from data ingestion and the different forms of data transformations between data warehouses, lakes, and BI tools. SQL is the language of choice for the MDS. Its declarative nature makes it easier to scale out compute to process large volumes of data, compared to a general purpose programming language like Python - which lacks native distributed computing support.
Machine Learning; a Python centric world.
Just as SQL dominates in analytics, Python dominates Data Science. Python’s grip on machine learning is so pervasive that Stack Overflow’s survey results from June 2022 show that Pandas, NumPy, TensorFlow, Scikit-Learn, and PyTorch are all in the top 11 of the most popular frameworks and libraries across all languages. Python has shown itself to be flexible enough for use within notebooks for prototyping and reporting, for production workflows (such as in Airflow), for parallel processing (PySpark, Ray, Dask), and now even for data driven user interfaces (Streamlit). In fact, even entire serverless ML systems with feature pipelines, batch prediction pipelines, and a user interface can be written in Python, such as done in this Surf Prediction System from PyData London.
Modern Data Stack vs Modern AI Stack: closing the gap
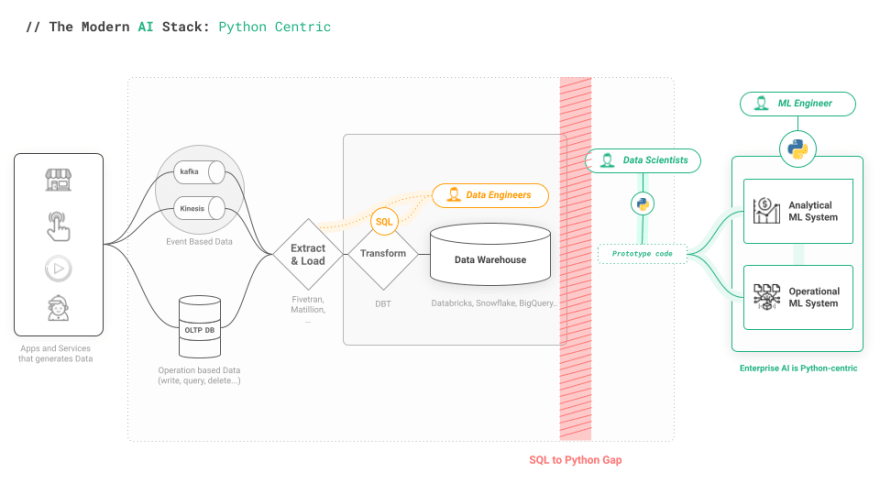
One reason models never make it to production is simply that the production MDS stack is not designed to make it easy to productionize machine learning models written in Python. Data scientists and ML Engineers are often left with prototypes that work on data dumps, without feature pipelines written in Python that are not connected to the MDS and inference pipelines that cannot connect make use of historical or contextual features because they are not connected back to existing data infrastructure. Snowflake introduced Snowpark, acknowledging the need for general purpose Python support in the MDS, but without its own Feature Store, Snowpark by itself is not enough.
How do we empower Data Scientists to access data in the MDS from Python without overwhelming them with the complexities of SQL and data access control? The Feature Store is one part of the solution to this problem. It is a new layer that bridges some of the infrastructural gap. However, the first Feature Stores came from the world of Big Data, and have primarily supported Spark, and sometimes Flink, for feature engineering To date, there has been a noticeable lack of a Python centric Feature Store that bridges the gap between the SQL world and the Python world.
Enters Hopsworks 3.0, the Python-centric feature store.

Hopsworks was the first open-source feature store, released at the end of 2018, and now with the version 3.0 release, it takes a big step to bridge the Modern Data Stack with the machine learning stack in Python.
With improved Read and Write APIs for Python, Hopsworks 3.0 allows data scientists to work, share, and interact with production and prototype environments in a Python-centric manner. Hopsworks uses transpilation to bring the power of SQL to their Python SDK and seamlessly transfer data from warehouses to Python for feature engineering and model training. Hopsworks provides a Pandas DataFrame API for writing features, and ensures the consistent replication of features between Online and
Offline Stores.
Hopsworks 3.0 now comes with support for Great Expectations for data validation in feature pipelines, and custom transformation functions can be written as Python user-defined functions and applied consistently between training and inference.
There is more to Hopsworks 3.0, and you can read about it in their very recent release blog.
For a more direct experience, use their newly released serverless app.hopsworks.ai ; allowing to use Hopsworks 3.0 without any infrastructure requirements; in less than 2 minutes and a colab notebook.

Top comments (0)