Last week, I came across the following question: “Is there an async producer/consumer collection these days in .NET?”
Why yes, there is! Using System.Threading.Channels, we can create producer/consumer pairs, and we can even chain them together in a pipeline.
In this post, I will try to explain concurrency, producer/consumer, and System.Threading.Channelsconcepts using a practical example, to refresh our collective memories.
Example scenario: generating Twitter cards for my blog
As an example for this blog post, I’ll create a “Twitter cards image generator” for my blog. I’ll not dive into image generation itself too much. There’s the excellent ImageSharp to generate images in .NET Core, and other posts have good examples of how to use it, such as Khalid Abuhakmeh’s “Generate YouTube Thumbnails with ImageSharp and .NET Core”.
The application will do the following:
- Read all filenames from the directory that contains my blog posts (a local copy of this)
- For every file name:
- Try to parse the YAML front matter (the header content here), to get the post title, author and publish date
- Generate the image
- Save the image
My code contains a class called ThumbnailGenerator, which does the heavy lifting:
public class ThumbnailGenerator
{
public Task<FrontMatter?> ReadFrontMatterAsync(string postPath) { }
public Task<Image> CreateImageAsync(FrontMatter frontMatter) { }
public Task SaveImageAsync(Image image, string fileName) { }
}
Using that class, I wrote a piece of code that executes the steps from the list above:
var generator = new ThumbnailGenerator();
var postPaths = Directory.GetFiles(Constants.PostsDirectory);
foreach (var postPath in postPaths)
{
var frontMatter = await generator.ReadFrontMatterAsync(postPath);
if (frontMatter == null) continue;
var cardImage = await generator.CreateImageAsync(frontMatter);
await generator.SaveImageAsync(
cardImage, Path.GetFileNameWithoutExtension(postPath) + ".png");
}
If all goes well, I should get a directory filled with Twitter cards for all of my blog posts, images like this:

We’re done here, right? Well, yes and no…
Concurrency and async/await
The above code is quite slow, taking a good 45 seconds to generate all Twitter cards. It would be good if we could speed it up with some added concurrency. ReadFrontMatterAsync() is I/O-bound (reading from disk), while CreateImageAsync()is CPU-bound (generating an image and calculating stuff).
Ideally, we would run these tasks concurrently so that while we’re waiting for the filesystem to give us back data, we can run the necessary calculations to generate an image.
Remember when everyone told you to use async/await so code could run concurrently? That’s still good advice, except you don’t get concurrency automatically. Even though the example above is using await ..., there will always be just one task that is scheduled to execute.
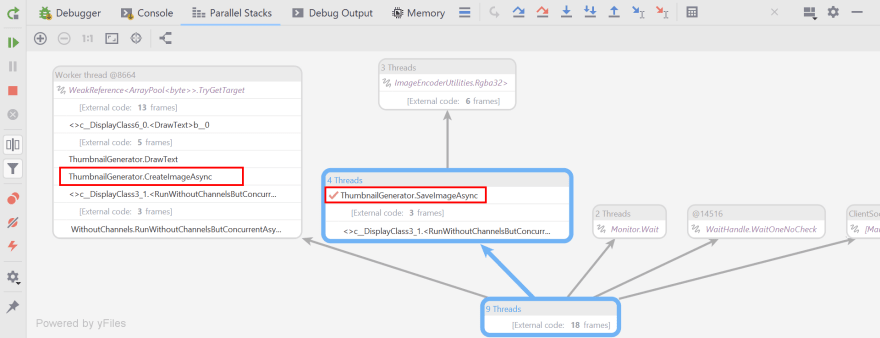
Here’s what the Parallel Stacks (in Rider) show when we pause on a breakpoint in SaveImageAsync():

In frameworks like ASP.NET Core, the framework itself schedules elements of the request pipeline concurrently. In this example, it looks like we’re on our own…
What can we do to run these tasks concurrently? One approach could be to schedule our tasks like this:
var generator = new ThumbnailGenerator();
var tasks = new List<Task>();
var postPaths = Directory.GetFiles(Constants.PostsDirectory);
foreach (var postPath in postPaths)
{
tasks.Add(new Func<Task>(async () =>
{
var frontMatter = await generator.ReadFrontMatterAsync(postPath);
if (frontMatter == null) return;
var cardImage = await generator.CreateImageAsync(frontMatter);
await generator.SaveImageAsync(
cardImage, Path.GetFileNameWithoutExtension(postPath) + ".png");
}).Invoke());
}
await Task.WhenAll(tasks);
Executing this piece of code and inspecting the Parallel Stacks again, we can now see various tasks are running concurrently. While the breakpoint is in SaveImageAsync(), we can see CreateImageAsync() is also scheduled to execute.
We’re done here, right? Well, yes and no…
Producer/consumer pipelines
The last example above has some issues, in that we have no control over concurrency, and the task scheduler will run tasks as it sees fit. Additionally, imagine we run this code on a directory with thousands of posts, not hundreds. There is a big chance we’ll exhaust memory on our machine, as the tasks capture the image created by CreateImageAsync() in memory.
Instead of having concurrent, procedural code, we could rethink this problem as a producer/consumer problem, and create a pipeline of those. Producers would produce messages that are sent to a queue-like structure, consumers would process messages from that queue.
Every step in our procedure is a producer/consumer combination:
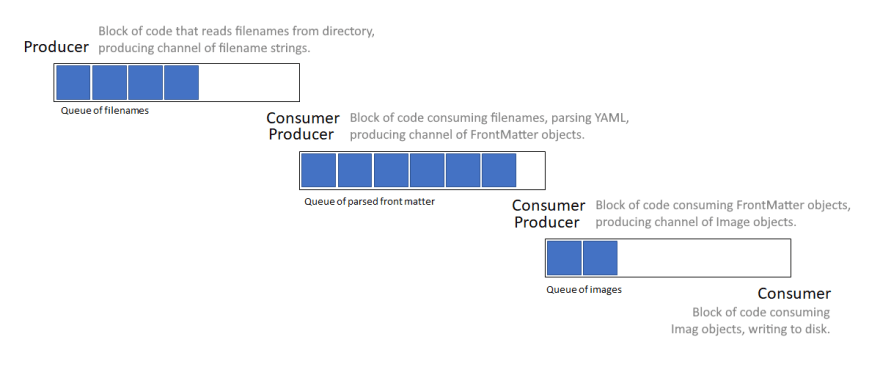
- A filename producer reads filenames from disks, and adds them to a queue-like structure.
- A consumer reads from that queue, and for every message, parses YAML front matter. This is then added to the next queue-like structure.
- A consumer reads from that queue, and for every message, creates an image. This is then added to the next queue-like structure.
- A consumer reads from that queue, and for every message, stores the image to disk.
It almost looks the same as our procedure, but now we can increase concurrency in a more controlled manner. For example, we could run 1 filename producer, 2 YAML parsers, 10 image generators, and 4 image writers, depending on what the workload of each task is.
We could create such pipeline of producers/consumers, and then… We’re done, right? Well, yes and no…
Unbounded concurrency vs. bounded concurrency
For some producer/consumer pairs, the data synchronization construct (the queue-like construct I mentioned before) can be unbounded. That means we are okay with them containing an unlimited number of messages.
For other producer/consumer pairs, it could be better to have a bounded way of doing things. For example, the queue-like construct that holds generated images may exhaust memory if we allow an unlimited number of messages, so perhaps we could limit the amount of messages allowed, and tell producers to back off when that limit is reached.
What to use?
To communicate between steps in our pipeline, we could use a Queue or another collection, such as a List in .NET. But when multiple threads and tasks are involved, we will run into concurrency issues pretty fast. When adding data to the collection, we may need to lock it. When reading data from it, we may need to do so, too.
Such construct could look like this: (courtesy of Stephen Toub in “An Introduction to System.Threading.Channels”)
public class QueueLikeConstruct<T>
{
private readonly ConcurrentQueue<T> _queue = new ConcurrentQueue<T>();
private readonly SemaphoreSlim _semaphore = new SemaphoreSlim(0);
public void Write(T value)
{
_queue.Enqueue(value);
_semaphore.Release();
}
public async ValueTask<T> ReadAsync(CancellationToken cancellationToken = default)
{
await _semaphore.WaitAsync(cancellationToken).ConfigureAwait(false);
_queue.TryDequeue(out var item);
return item;
}
}
The above snippet uses a ConcurrentQueue to store data, and by using a SemaphoreSlim we can help notify consumers when data is available.
Did you know (or did you remember) this type of construct exists in .NET?
Hello, System.Threading.Channels!
The System.Threading.Channels namespace provides us with the necessary constructs to make building a pipeline of producers/consumers easier, without having to worry about locking and other potential concurrency issues. It also provides bounded and unbounded “channels” (the name that is used for our queue-like construct).
Note:
System.Threading.Channelsis always available in .NET Core. For .NET Framework, install theSystem.Threading.Channelspackage if you want to use it.
The System.Threading.Channels namespace contains a static Channel class that gives us several factory methods for creating channels. A channel usually comes in the form of Channel<T>, a data structure that supports reading and writing.
Here’s how we can create a channel for our first producer/consumer pair, the one that gives us a stream of blog post paths:
var postPathsChannel = Channel.CreateUnbounded<string>(
new UnboundedChannelOptions() { SingleReader = false, SingleWriter = true });
var postPaths = Directory.GetFiles(Constants.PostsDirectory);
foreach (var postPath in postPaths)
{
await postPathsChannel.Writer.WriteAsync(postPath);
}
postPathsChannel.Writer.TryComplete();
A couple of things to unwrap…
- We are creating an unbounded channel of
stringvalues, because we expect the file paths to not exhaust memory. It’s just some strings, right? - The unbounded channel is created for multiple readers, and a single writer. It’s not required to specify these options, but it helps optimize the data access structure for scenarios with multiple readers/writers.
- We’re posting messages to the channel using
WriteAsync(), and once all messages are posted, we complete the channel (TryComplete()), to let consumers know that no new data is going to come.
On the consumer side, we can process this channel:
var frontMatterChannel = Channel.CreateBounded<(string?, FrontMatter?)>(
new BoundedChannelOptions(10) { SingleReader = false, SingleWriter = false });
while (await postPathsChannel.Reader.WaitToReadAsync())
{
while (postPathsChannel.Reader.TryRead(out var postPath))
{
var frontMatter = await generator.ReadFrontMatterAsync(postPath);
await frontMatterChannel.Writer.WriteAsync((postPath, frontMatter));
}
}
frontMatterChannel.Writer.TryComplete();
A couple of things to unwrap…
- While
postPathsChannelhas not been completed, weTryRead()messages. - If a message is present, we process the front matter. The processed front matter is then posted to the next channel,
frontMatterChannel. - The
frontMatterChannelchannel is a bounded one. If there are 10 messages in there, theTaskreturned byWriteAsync(), by default, will not complete until capacity is available. Since we are usingawait, this will essentially “wait” for capacity, while other tasks in our program can run. - Similar to our previous producer, we
TryComplete()thefrontMatterChannelto let the next consumer know there will not be new data coming.
For every step, we’ll do something like the above. There are some good examples of producer/consumer patterns in the .NET Core GitHub repo.
If you want to have a look at the full implementation, it’s available on GitHub.
We’re done, right? Well, yes and no…
Hello, Open.ChannelExtensions!
After writing a few pipelines of producers/consumers, the channel setup, writing, completion, … becomes cumbersome rather quickly.
This is where Open.ChannelExtensions comes in. It helps simplify working with System.Threading.Channels. It can read from and write to channels, pipe channels into other channels, filter, batch, join, and more.
The entire pipeline we created above could be rewritten using Open.ChannelExtensions:
var generator = new ThumbnailGenerator();
await Channel
.CreateBounded<string>(50000)
.Source(Directory.GetFiles(Constants.PostsDirectory))
.PipeAsync(
maxConcurrency: 2,
capacity: 100,
transform: async postPath =>
{
var frontMatter = await generator.ReadFrontMatterAsync(postPath);
return (postPath, frontMatter);
})
.Filter(tuple => tuple.Item2 != null)
.PipeAsync(
maxConcurrency: 10,
capacity: 20,
transform: async tuple =>
{
var (postPath, frontMatter) = tuple;
var cardImage = await generator.CreateImageAsync(frontMatter!);
return (postPath, frontMatter, cardImage);
})
.ReadAllAsync(async tuple =>
{
var (postPath, _, cardImage) = tuple;
await generator.SaveImageAsync(
cardImage, Path.GetFileName(postPath) + ".png");
});
Not quite as short as our procedural version, but there are some nice things we get from using this approach:
-
Source()is a producer. Based on data (all files in the blog post directory), the first channel in our pipeline is populated. -
PipeAsync()is a consumer/producer. We can see there are 2 of those, the first parsing front matter, the second generating images. -
ReadAllAsync()is a consumer. It does not produce data, and is essentially the final step in our pipeline. In this example, it writes image files to disk. - Both concurrency (how many tasks should be used for a consumer/producer?) and capacity (how many messages to buffer?) can be controlled. Using these we can control the way our pipeline behaves.
Conclusion
The original, procedural version of our code took 45 seconds to execute. The channels version takes 16 seconds. So what changed?
Using System.Threading.Channels, we ensure concurrency of different kinds of workloads:
-
ReadFrontMatterAsync()is I/O-bound (reading from disk), and mostly waits for the filesystem -
CreateImageAsync()is CPU-bound (generating an image and calculating stuff), and requires memory and CPU cycles
Concurrent execution does not necessarily mean parallelism! We’re using async/await and channels to make it easier for the task scheduler in .NET to shuffle our tasks around. The default ThreadPoolTaskScheduler will use threadpool threads, and thus, run our code in parallel, but that’s an implementation detail. We are merely splitting our application’s workload, so it can wait for I/O and consume CPU at the same time.
Bounded and unbounded channels exist and can help us control how many messages fit on our channel, to make sure we don’t exhaust memory.
System.Threading.Channels does not help with chaining channels and creating pipelines from them, we need to create those ourselves. The Open.ChannelExtensions helps here by providing extensions on top of System.Threading.Channels.
Further reading
While I only covered some concepts, there’s much more to explore in the realm of channels and pipelines!
- An Introduction to System.Threading.Channels (Stephen Toub)
- An Introduction to System.Threading.Channels (Steve Gordon)
- C# Channels - Publish / Subscribe Workflows (Denis Kyashif)
- C# Channels - Timeout and Cancellation (Denis Kyashif)
- C# Channels - Async Data Pipelines (Denis Kyashif)
- How to implement Producer/Consumer with System.Threading.Channels (Davide Guida)
- System.Threading.Channels README.md (.NET team)
And while not in .NET, Kotlin: Diving in to Coroutines and Channels (Jag Saund) is a brilliant explanation of concurrency, coroutines (Kotlin’s Task equivalent) and channels.

Top comments (0)