
There are many different tools in the world, each of which solves a range of problems. Many of them are judged by how well and correct they solve this or that problem, but there are tools that you just like, you want to use them. They are properly designed and fit well in your hand, you do not need to dig into the documentation and understand how to do this or that simple action. About one of these tools for me I will be writing this series of posts.
I will describe the optimization methods and tips that help me solve certain technical problems and achieve high efficiency. This is my updated collection.
Many of the optimizations that I will describe will not affect the JVM languages so much, but without these methods, many Python applications may simply not work.
Whole series:
- Spark tips. DataFrame API
- Spark Tips. Don't collect data on driver
- The 5-minute guide to using bucketing in Pyspark
Let's start with the problem.
We've got two tables and we do one simple inner join by one column:
t1 = spark.table("unbucketed1")
t2 = spark.table("unbucketed2")
t1.join(t2, "key").explain()
In the physical plan, what you will get is something like the following:
== Physical Plan ==
*(5) Project [key#10L, value#11, value#15]
+- *(5) SortMergeJoin [key#10L], [key#14L], Inner
:- *(2) Sort [key#10L ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(key#10L, 200)
: +- *(1) Project [key#10L, value#11]
: +- *(1) Filter isnotnull(key#10L)
: +- *(1) FileScan parquet default.unbucketed1[key#10L,value#11] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/opt/spark/spark-warehouse/unbucketed1], PartitionFilters: [], PushedFilters: [IsNotNull(key)], ReadSchema: struct<key:bigint,value:double>
+- *(4) Sort [key#14L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(key#14L, 200)
+- *(3) Project [key#14L, value#15]
+- *(3) Filter isnotnull(key#14L)
+- *(3) FileScan parquet default.unbucketed2[key#14L,value#15] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/opt/spark/spark-warehouse/unbucketed2], PartitionFilters: [], PushedFilters: [IsNotNull(key)], ReadSchema: struct<key:bigint,value:double>, SelectedBucketsCount: 16 out of 16
SortMergeJoin is the default spark join, but now we are concerned with the other two things on the execution plan. They are two Exchange operations. We are always concerned with exchanges because they shuffle our data — we want to avoid it, well, unless there is no choice. But...

We know that we joined by the key column so we will use this information just to get rid of these two exchanges.
How?
Use bucketing
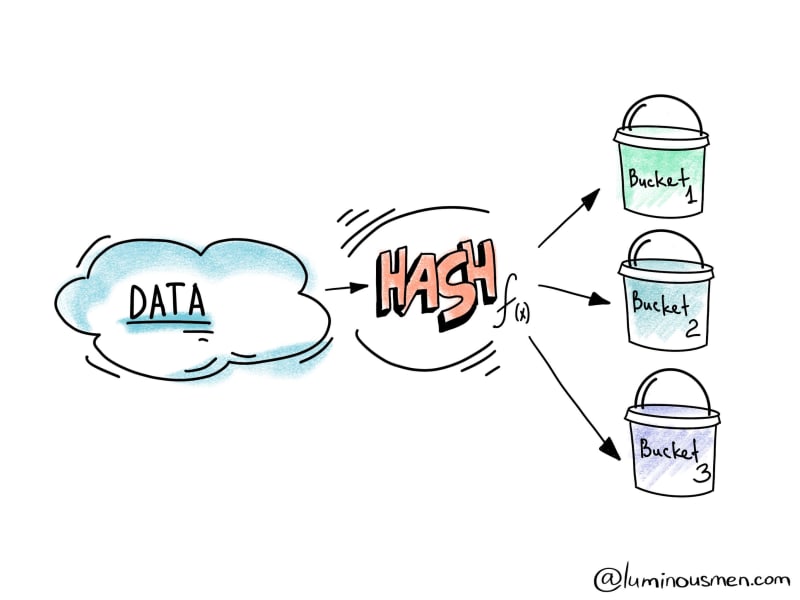
Bucketing is an optimization technique that decomposes data into more manageable parts(buckets) to determine data partitioning. The motivation is to optimize the performance of a join query by avoiding shuffles (aka exchanges) of tables participating in the join. Bucketing results in fewer exchanges (and hence stages), because the shuffle may not be necessary -- both DataFrames can be already located in the same partitions.
Bucketing is enabled by default. Spark SQL uses spark.sql.sources.bucketing.enabled configuration property to control whether it should be enabled and used for query optimization or not.
Bucketing specifies physical data placement so we pre shuffle our data because we want to avoid this data shuffle at runtime.
Oookay, do I really need to do an additional step if the shuffle will be executed anyway?
If you're joining multiple times than yes. The more joins the better performance gains.
An example of how to create a bucketed table:
df.write\
.bucketBy(16, "key") \
.sortBy("value") \
.saveAsTable("bucketed", format="parquet")
So here, bucketBy distributes data across a fixed number of buckets(16 in our case) and can be used when a number of unique values are unbounded. If the number of unique values is limited it's better to use partitioning rather than bucketing.
t2 = spark.table("bucketed")
t3 = spark.table("bucketed")
# bucketed - bucketed join.
# Both sides have the same bucketing, and no shuffles are needed.
t3.join(t2, "key").explain()
And resulting physical plan:
== Physical Plan ==
*(3) Project [key#14L, value#15, value#30]
+- *(3) SortMergeJoin [key#14L], [key#29L], Inner
:- *(1) Sort [key#14L ASC NULLS FIRST], false, 0
: +- *(1) Project [key#14L, value#15]
: +- *(1) Filter isnotnull(key#14L)
: +- *(1) FileScan parquet default.bucketed[key#14L,value#15] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/opt/spark/spark-warehouse/bucketed], PartitionFilters: [], PushedFilters: [IsNotNull(key)], ReadSchema: struct<key:bigint,value:double>, SelectedBucketsCount: 16 out of 16
+- *(2) Sort [key#29L ASC NULLS FIRST], false, 0
+- *(2) Project [key#29L, value#30]
+- *(2) Filter isnotnull(key#29L)
+- *(2) FileScan parquet default.bucketed[key#29L,value#30] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/opt/spark-warehouse/bucketed], PartitionFilters: [], PushedFilters: [IsNotNull(key)], ReadSchema: struct<key:bigint,value:double>, SelectedBucketsCount: 16 out of 16
Here we have not only fewer code-gen stages but also no exchanges.
As of Spark 2.4, Spark supports bucket pruning to optimize filtering on the bucketed column (by reducing the number of bucket files to scan).
Summary
Overall, bucketing is a relatively new technique that in some cases might be a great improvement both in stability and performance. However, I found that using it is not trivial and has many gotchas.
Bucketing works well when the number of unique values is unbounded. Columns that are used often in queries and provide high selectivity are good choices for bucketing. Spark tables that are bucketed store metadata about how they are bucketed and sorted which help optimize joins, aggregations, and queries on bucketed columns.
Thank you for reading!
Any questions? Leave your comment below to start fantastic discussions!
Check out my blog or come to say hi 👋 on Twitter or subscribe to my telegram channel.
Plan your best!

Top comments (4)
Hi, thank you for sharing.
Could you elaborate on the gotchas? And why do you find the use not trivial? Is it because we have to save the df using write method ect? So sometimes we will save the df "normally" and using buckets?
Thank you ;)
Thank you for your support, Maxime!
I say it's not trivial because you have to fulfill at least a few conditions.
Hi, may I ask you what differs between buckets and partitions? I've never used buckets but, using Spark reading mainly Hive tables, I noticed that partitions have too a large impact on shuffling. So what are the main differences? Thanks in advance.
At their core, they are one and the same thing - optimizing data retrieval based on splitting up data by content. The difference is the number of aka separations that will eventually occur. As you said in order to join data, Spark needs the data that is to be joined (i.e., the data based on each key) to live on the same partition. In essence, we want to move the data (shuffle) as little as possible between the nodes of the cluster so that join can happen as parallel as possible (in each partition).
For example, if you're doing any annual financial reports, it makes sense to partition the data by month - you'll have 12 partitions in total. And if there are 12>= executors in the cluster, then doing join by month we can make join absolutely parallel if the dataset with which we join is also partied in the same way.
The same thing happens with buckets, but with data that don't have some logical way to partition (e.g., logs, user transactions, etc.). We can essentially do the same thing as with the partitions but specifying exact number of buckets (aka partitions).
I hope that makes sense. I'm thinking of writing an article on this while it's in my backlog. I hope I get to the point of writing it eventually :)