
With the advent of new decade, as hardware gets modern (like Flash disk instead of magnetic ones), the concept of database and web-services needs to be modernised as well.
So, what's the problem with traditional systems and databases?
Relational Database representation compared to client side (usually Object Oriented) representation are completely different. To overcome this No-SQL was introduced (ex. mongo, couchdb etc). However, even then they were developed keeping in mind the magnetic disks and were not tuned for optimal usage for new hard disk systems like flash disks. One such optimized store for new era hardware is rocksdb, which had the benefit of being developed later. Similarly we need to come up with new concepts which makes both server and client side development easy as far as data management and services are concerned.
In comes the concept of Quarks (the name originally given by one of my esteemed colleagues Dr. Russel Ahmed Apu). Quarks plan to provide a uniform structure to address architectural problems, a proposed step in the right direction to modern software development. As micro-services concept gain popularity, there needs to be a mindset and attitude change towards server side programming. Having a separate heavy-weight stand alone db will not be a feasible solution in the upcoming decades; hence Quarks concepts can be considered a paradigm shifting solution towards how services are written.
Quarks serves as a small lightweight easily distributable service which eliminates the need of writing a lot of apis in the server side. There is also no need to create data models in servers in simple scenarios and having to link them to a separate stand alone DB. At the heart of quarks is the concept of simplicity. Programming in modern era should be simple - the program shouldn't have to worry about traffic management, threads, scaling and distributing of the system when the need arises.
For scaling - simply replicate the Quarks Servers, put a standard load balancer (like nginx) in front to distribute api calls. The Quarks services will communicate with each other and interchange data if needed.
Why it is named Quarks is because quarks services act like small particles (read light weight micro-services) and create a large system eventually! Getting it up and running is as easy as dropping an executable in hosting-server and running it.
A majority of modern apps now a days has to deal with data and Quarks provide a mechanism to cache, store, retrieve and operate on this data fast (taking advantage of modern hardware) with clever querying techniques.
It is probably better to explain the usage of Quarks with a real life example.
Before moving on to the example, here is the essence in two lines:
- User-->[Quarks.Store] ->ThreadManagement->[Cache/Ram]->Queue->PersistentStorage
- User-->[Quarks.Query]->ThreadManagement->fetch to [Cache/RAM]->return
Will discuss how the scaling happens for huge data in a bit after we go through a use case scenario.
User Story - A public chatting system
Step 1 : User types name and asl (age sex location) and
choose from a list of chat channels and clicks join.
Call goes to nodejs/php server through api or socket.
server generates a user_id and assigns a user to a channel
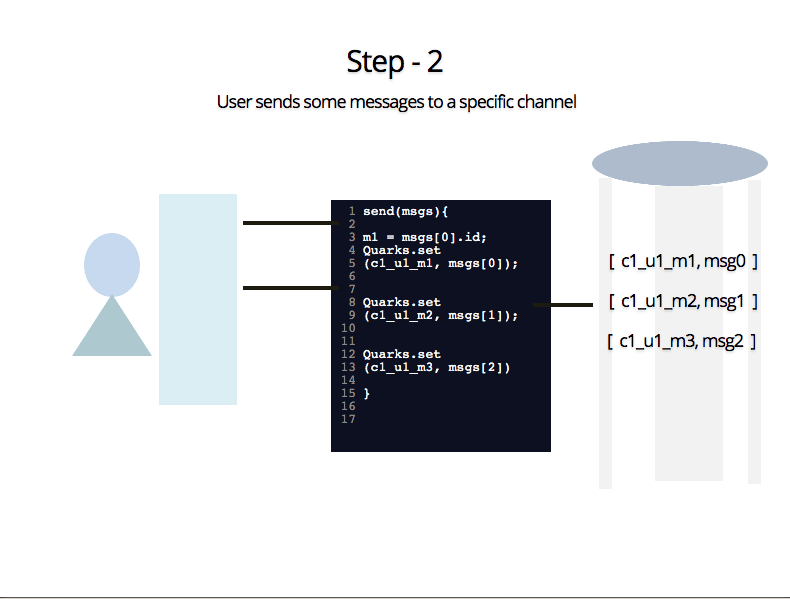
Step 2 : User sends some messages to a specific channel
Step 3 : On re-entry user can see all messages for that channel.
We address these steps as follows:
(Using diagrams to illustrate the solution)
where c1=Channel Name, u1=User ID, m1 = message id and data is saved as key value pair through Quarks.set


When I talked about clever querying, have a look at how using wild card search it is possible to retrieve the desired info from loads of data.
Needless to mention that all the saving, server hits, request queuing, traffic handling, thread management is now a part of the Quarks system which takes the headache.
Now on to scaling and having a distributed system..
As the traffic grows we can create new instances of the Quarks instance (let's call them core) and these can be controlled by a multicore/multi-instance manager. Illustration below:
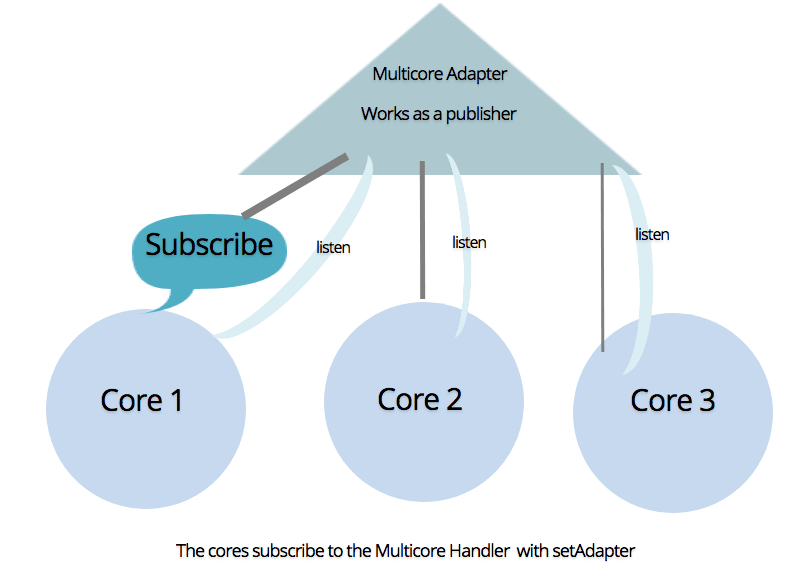
Basically, the idea is having a lot of light weight easily drop-able servers (calling them Quarks Cores) and an adequate balancing server (planning to name it Boson). Once the Boson is running, the cores would be able to talk to each other and fetch a lot of results very fast!
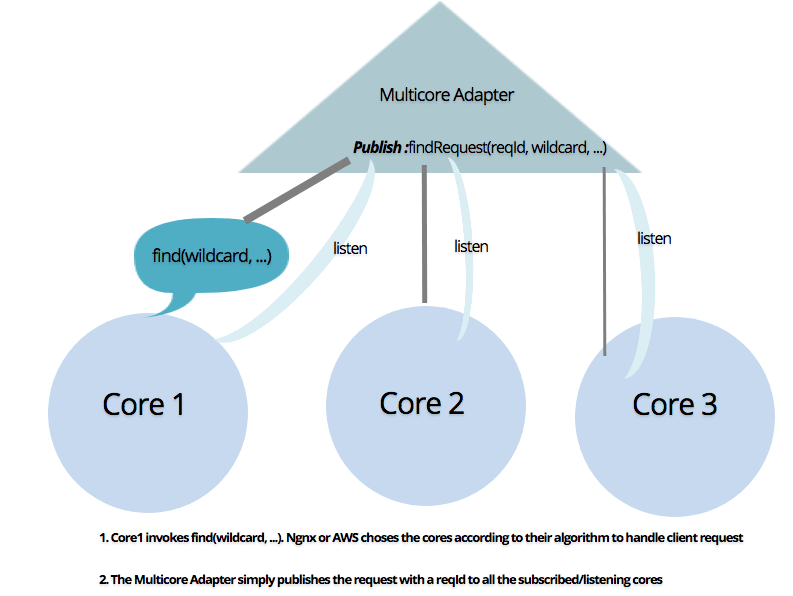
So, how does the fetchMessages for a multi-core system look like? Not too much different from what you saw in Step-3. fetchMessages invoke a find query on Quarks.

Again, an illustration on how Quarks is working on the query internally:
[added March 15, 2020] - There has been an evolution of thoughts so to speak,
and how Quarks would work more gracefully has been described in the follow up article: https://dev.to/lucpattyn/quarks-architecture-2lk4
First, the find request is carried on to the multicore manager which publishes the request for all of the listening cores to process:
Finally, as results become available, the manager aggregates them and returns to the requesting core which was invoked by the client.
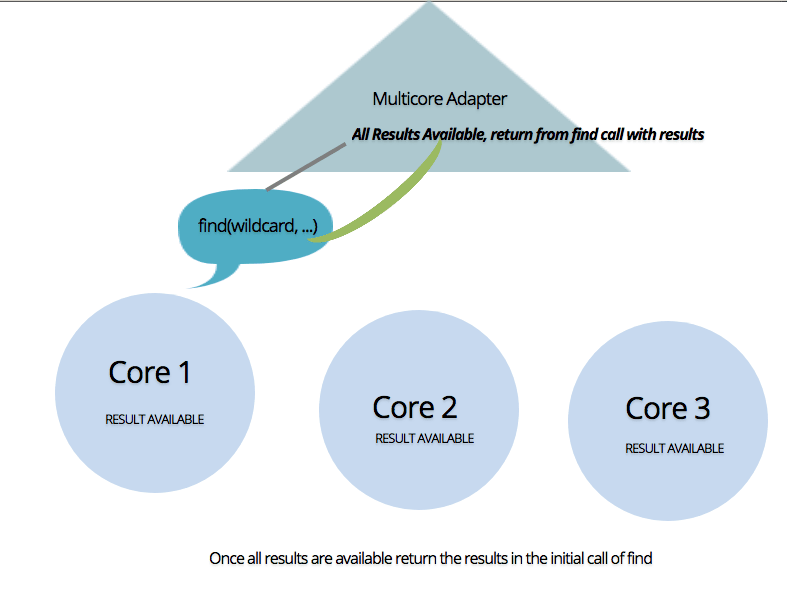
Point to note - in client side coding we will hardly notice the difference.
Some key features provided by Quarks:
1) Persistence of data - Quarks will provide a mechanism , where after a certain amount of memory / cache is filled, it will send batch data for serialisation/ dumping to database for later retrieval. That reduces the hits to persistent storage. However, it will provide a mechanism where it can dump to persistent storage immediately if required.
2) Querying on data - Quarks will be able to query on the value (as well as key) through ORM style queries and apply business logics on the queried data.
Sample Query Format , ..
query items which are up for sale with key like item* (i.e item1, item2 etc.) which have rating greater than 3 and are approved, then find the sellers of such items (items has a seller_id field that contains the user_id of the seller) and lastly list all orders associated with the sellers whose delivery type is pickup (not home delivery).
Keys for order object looks like ord*_user* (i.e ord1_user1, ord2_user1 etc.)
Sellers have user ids in the form of user1, user2 etc.
{
filter:
[
{
keys: "item*",
where: [{rating:{gt:3}},{approved:{eq:1}}]
filter:
{
map: {field:"seller_id", as:"sellers"},
filter:
{
map:
{
prefix:"ord*_"
field:"user_id",
suffix:"" ,
as:"orders"
},
where:{deliveryType:{eq:"pickup"}}
}
},
]
}
Here after getting a set of objects through filtering, map specifies how to join/include additional results by forming a wild card search through concatenating of
i) a prefix,
ii) field value of an existing object given the field name and a
iii)suffix.
So, after getting a list of sellers along with the items, we are cleverly querying the orders for those sellers by forming an wildcard compare string which is of the form ord*_user*.
Scripting languages like javascript (through v8 engine) will be allowed to apply business logic in the queried data. We would be able to use plugins too for computation and calculation.
3) Sorting - Sorting will be done based on both query and applying server side logics if necessary through scripts/plugins.
4) Expiry - Efficient data expiry mechanism will be provided in the server side.
Lastly, Quarks can reside on the same memory space along with business logics by means of simple scripts or plugins (dynamically loaded libraries) without the need of having a separate server for storing data. Lightweight servers quering on the data of the same memory space will make results retrieval much faster than traditional systems.
Now the million dollar question - Is Quarks already developed? No! It's a concept which we are working on and hopefully will have something solid to show in next 6 months. We plan to use following technology:
a) C++ Crow Webserver for serving client requests
b) Good JSON Parsing C++ Library (not decided yet, probably will go with the one provided in Crow)
c) ZeroMQ for PUBSUB.
"If we make some progress, rest assured you would be seeing more articles on Quarks in this site."
- Modified Nov - 1, 2019 - The above statement now needs changing as we have got Quarks up and running!
Also rocksdb and v8 javascript engine has been introduced and ZeroMQ to be integrated for internal communications between Quarks Cores.
Code repo to be found here: https://github.com/lucpattyn/quarks
Just to re-iterate one more time, Quarks is a system as well as a philosophy and set of concepts and guidelines (ex. longer reads, short bursts of writes .. more of that in due time) to make modern day programming easy and simple. We will have more discussions on this some other day.
Updated 30th Oct, 2020:
Like to provide a little more clarity on where Quarks differs compared to the traditional architecture frameworks:
Traditional Framework:
client->api gateway->backend server logic->makes query to a separate server db (latency occurs)->fetches data->works on the fetched data->produce results->sends back to client
Quarks Framework:
client->api gateway->quarks data lookup(apply business logic while lookup)->sends data back to client
*reducing round trip to separate servers and eliminating a few steps in between.
Updated 24th July, 2022:
Follow up article about Quarks architecture -
https://dev.to/lucpattyn/quarks-replication-for-a-scalable-solution-1h64
Signing off for now,
Mukit

Top comments (0)