Cada vez mais os sistemas de computação estão envolvidos no dia-a-dia da sociedade, por vezes através de novos modelos de negócio que só seriam possíveis com a tecnologia, ou integrando-se a fluxos tradicionais com a automatização e otimização de um trabalho. Dentro da ciência da computação, há vários campos que estudam cada aspecto deste vasto impacto da tecnologia na sociedade, especialmente sobre a construção dessas aplicações que servirão a diversos propósitos.
Uma classe especial dessas aplicações são os sistemas corporativos que, dentre outras definições, são sistemas robustos que lidam com informações sensíveis e vastas. A construção de aplicações corporativas é marcada pelo rigor em requisitos não-funcionais, como segurança, desempenho e disponibilidade, o que torna-se uma das tarefas mais difíceis para o time de desenvolvimento prover num software, principalmente quando a aplicação é disponibilizada para uma larga base de usuários, seja frequente ou recorrente, com picos instântaneos.
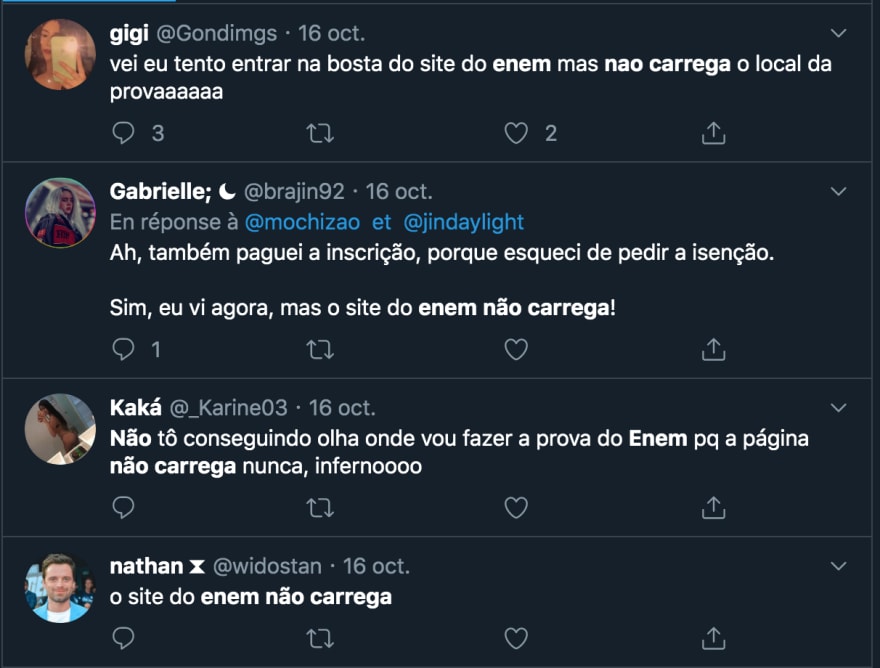 Comentário no Twitter sobre o sistema do ENEM no dia que os locais de prova do exame de 2019 foram divulgados
Comentário no Twitter sobre o sistema do ENEM no dia que os locais de prova do exame de 2019 foram divulgados
 Falha de segurança no sistema do SISU, Sistema de Seleção Unificiado do INEP, permitiu que usuários alteressem dados de outros usuários
Falha de segurança no sistema do SISU, Sistema de Seleção Unificiado do INEP, permitiu que usuários alteressem dados de outros usuários
Os casos demonstrados acima representam a quebra destas métricas importantes para os sistemas corporativos, e que podem tanto ocasionar um downtime da aplicação como também compremeter as informações pessoais dos usuários, com possíveis repercussões legais.
Mas a parte mais interessante da ciência é que pode-se estudar o que deu errado e estabelecer boas práticas para evitar que tais problemas ocorram novamente (ou pelo menos minimizar a chance de algo dar errado), e isso tem sido feito há um bom tempo. Nesse post tentarei explicar alguns conceitos básicos de como arquiteturar um sistema corporativo na internet e também fornecer algumas dicas para que você possa estudar mais.
TL;DR
- Sempre que puder, se livre da responsabilidade: faço uso de uma arquitetura serverless (ex: Firebase Cloud Functions e AWS Lambda) e serviços de terceiros para autenticação. Caso isso não seja possível, recomendo estude BEM o que você quer fazer, as soluções disponíveis, e principalmente as experiências que alguém já teve com essas soluções.
Autenticação
Quando começa-se a projetar uma aplicação que vai fornecer acesso a usuários finais, sempre é necessário planejar como será a solução de segurança da aplicação, pois essa parte do sistema provavelmente terá o impacto mais extensivo ao longo dos fluxos de execução.
Uma boa dica geral para lidar com autenticação é terceirizar ao máximo a responsabilidade, principalmente quando se trata de guardar senhas de usuários. Atualmente uma boa opção é utilizar o Login Social, onde, através do protocolo oAuth, os usuários podem se conectar no sistema identificando-se através de algum provedor de acesso, utilizando suas contas no Google, Facebook, Github ou em algum serviço especializado como OpenId. Essa solução pode apresentar problemas de privacidade e potencialmente pode haver algum usuário que não terá conta em nenhum dos serviços que você escolheu para servirem como provedor.
Mas, se você precisa (ou quer) ter total controle dos dados de segurança e deseja implementar um modelo de autenticação "clássico" usuário-e-senha uma boa estratégia é o uso de um padrão como o JWT (Json Web Token). Vai ser possível encontrar implementações compatíveis para os mais variados frameworks por ser uma tecnologia já bem consolidada na internet, valendo sempre uma atenção na hora de guardar a senha dos usuários que é, como falei, uma tarefa de muita responsabilidade. O uso de um algoritmo de hash como o bcript vai tornar o módulo de autenticação mais robusto, mas é também importante o uso de HTTPS, dica que vale para todo o sistema em si. Você pode saber mais sobre HTTPS aqui, e conseguirá certificados gratuitamente no Let's Encrypt.
MultiFactor Authentication
Mesmo com as soluções acima implementadas, são cada vez mais frequentes, principalmente pela maior abrangência dos sistemas corporativos, os vazamentos de dados (por parte de outras empresas ou brechas de seguranças em linguagens de programação e em frameworks), por isso tem-se tornado comum a implementação de uma segunda maneira de autenticação, principalmente baseado em "senhas temporárias" utilizando aplicativos como Google Auth, Microsoft Authenticator ou Authy e também o serviço de SMS, onde o número de celular torna-se um verificador de identificação. Este segundo passo é utilizado como prova após o acesso convencional (com e-mail e senha, por exemplo), para garantir que mesmo que a senha do usuário tenha sido roubada não será possível acessar o sistema sem a segunda verificação.
Obs: Alguns serviços de autenticação também oferecem o acesso apenas através do serviço de verificação através do número de celular do usuário, já esta é uma informação pessoal de verificação, mas nos últimos anos têm sido comuns casos de clonagem de número SIM, deixando aberto a invasores utilizarem desse privilégio para acessar serviços em nome da vítima que teve seu número clonado (saiba mais sobre esses casos aqui). Recentemente, procuradores da justiça federal do Brasil tiveram suas conversas no aplicativo Telegram publicadas após criminosos se apropriarem das contas através de uma falha no serviço de caixa postal (saiba mais aqui). Então, por enquanto, é recomendável evitar autenticação baseada em número de celular.
Dica: Você pode utilizar facilmente boa parte das soluções descritas aqui através dos serviços Auth0 e Firebase Auth, ambos com planos gratuitos.
Passwordless Authentication
Nos últimos anos, com a adoção cada vez maior dos serviços web pela população em geral, os desenvolvedores e as empresas de tecnologia têm notado que as senhas estão se tornando obsoletas), e tem sido comum a adoção de práticas de autenticação que não dependem do usuário necessariamente ter uma senha no serviço (e também sem a utilização de um provedor externo com Google ou Facebook). Isso pode ser implementado de diversas maneiras, como através de um envio de e-mail, mas os browsers e as grandes empresas têm trabalhado no padrão WebAuth, que faz o uso de chaves criptográficas para prover autenticação, além de se integrar com serviços biométricos como o Apple TouchID. Essa tecnologia oferece a robustez e a segurança para se tornar um dos padrões de autenticação na internet num futuro próximo, vale a pena checar.
Dica: No projeto de um sistema corporativo, é importante saber bem a diferença entre autenticação, que é o ato de verificar se um usuário é realmente "ele mesmo", e autorização, que verifica as permissões que um certo usuário ostenta dentro da aplicação.
Disponibilidade e desempenho
Talvez esses pontos sejam a maior preocupação do ponto de vista estrutural de um sistema corporativo, impactando tanto a experiência do usuário final como o custo financeiro de operação do sistema. E com certeza é uma das tarefas mais complicadas tecnicamente pois envolve o gerenciamento de diversos recursos que podem ser ou não ser compartilháveis ou replicáveis ao longo do tempo.
Um exemplo da particularidade desse problema ocorre quando, como visto nas imagens do início do post, são liberados os locais de prova dos candidatos do ENEM no sistema web e causam um pico de acesso repentino que faz a aplicação parar de responder em alguns casos ou apresentar lentidão para os usuários. Inicialmente poderia pensar-se na solução de criar uma infraestrutura fixa que possa sempre suportar o número máximo de acessos que o sistema recebe (por exemplo, em um dia de divulgação das notas), mas em todo o resto do ano estaria disperdiçando-se recursos desnecessários para uma carga "comum" e potencialmente gastando mais dinheiro do que seria necessário.
Nessa sessão, falarei de algumas passos para prover um bom desempenho em um sistema corporativo através de uma arquitetura escalável, que se adapta de acordo com o número de acessos.
Anos atrás havia a discussão sobre estratégias de escalar um sistema verticalmente, onde o mesmo sistema com instâncias únicas de cada parte passam a rodar em uma máquina bem mais potente ou horizontalmente, onde as partes do sistema são "replicadas" para trabalhar em mais de um processador ou, mais , mais de uma máquina. A primeira opção não tem sido muito usada por, principalmente, ser bem mais caro aumentar o limite de processamento de uma única máquina.
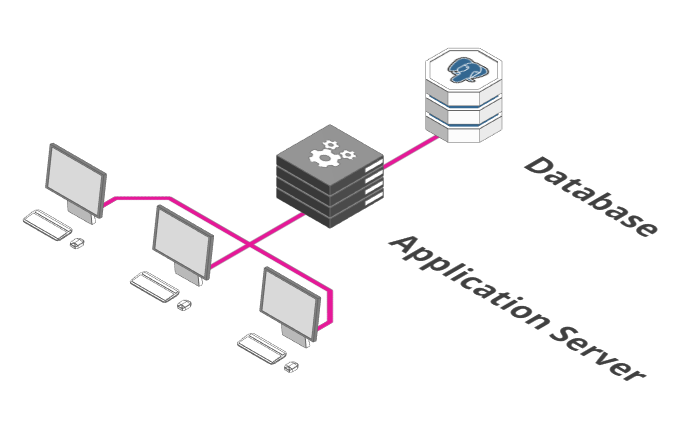
1. A arquitetura original
 Fonte: https://arcentry.com/blog/scaling-webapps-for-newbs-and-non-techies/01-initial-700.png
Fonte: https://arcentry.com/blog/scaling-webapps-for-newbs-and-non-techies/01-initial-700.png
Muito provavelmente a arquitetura básica de um sistema web se parece com isso. Um servidor, geralmente servindo conteúdo por uma porta HTTP, conectado à um banco de dados instalado na mesma máquina. Simples e fácil de gerenciar, consegue acomodar poucos clientes sem muitos acessos simultâneos.
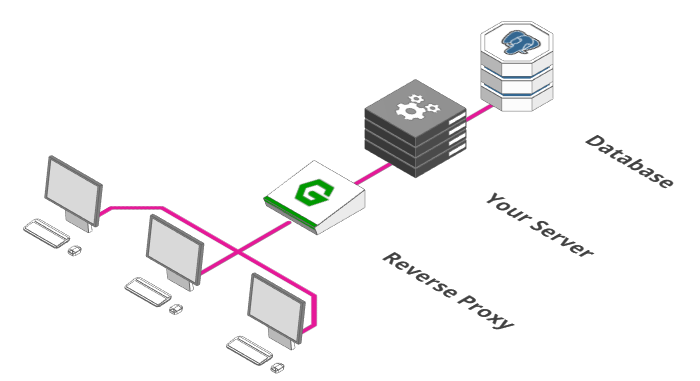
2. Adicionar um Proxy Reverso
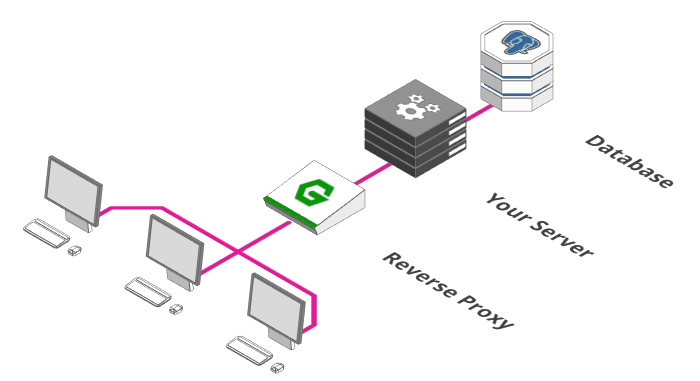 Fonte: https://arcentry.com/blog/scaling-webapps-for-newbs-and-non-techies/02-reverse-proxy-700.png
Fonte: https://arcentry.com/blog/scaling-webapps-for-newbs-and-non-techies/02-reverse-proxy-700.png
Um Proxy Reverso (como o Nginx) serve como porta de entrada para sua aplicação, além de outras funcionalidades que podem ser adicionadas. Ele vai redirecionar as requisições recebidas para o servidor (ou os servidores) adequado, também mascarando detalhes de implementação que podem ser "vazados" caso você use o próprio framework do seu servidor como porta de entrada da aplicação. Além de facilitar para a expansão da sua arquitetura corporativa, um proxy reverso pode implementar as seguintes funcionalidades:
- Health Checks: Integrado com alguma ferramenta, como um bot para o Slack, estará verificando se os seus servidores estão funcionando corretamente, notificando o administrador caso algum problema seja reportado
- Rotamento: A funcionalidade "principal", que é redirecionar as requisições para os "resolvers" corretos - talvez você sirva arquivos estáticos utilizando HTTP2 ou um CDN próprio e deseje uma resolução diferente para estes arquivos.
- Autenticação: Caso use um provedor externo de autenticação, o proxy pode também resolver se o usuário que está tentando acessar tal recurso tem autenticação e autorização devidas
- Firewall: Pode servir de "guarda" para impedir acessos indevidos a outras portas e serviços do seu servidor.
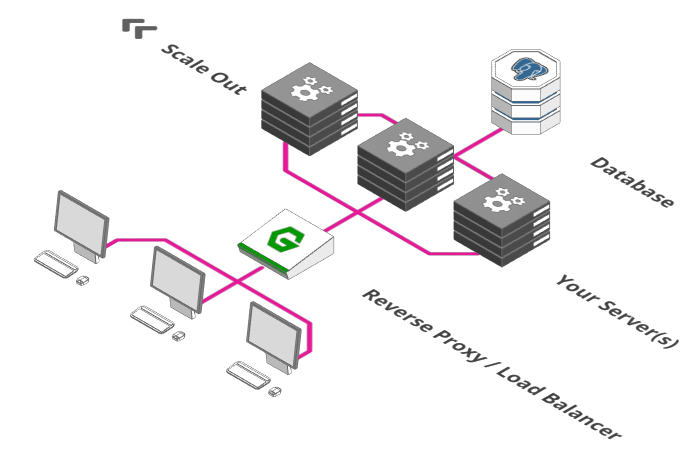
3. Load Balancer
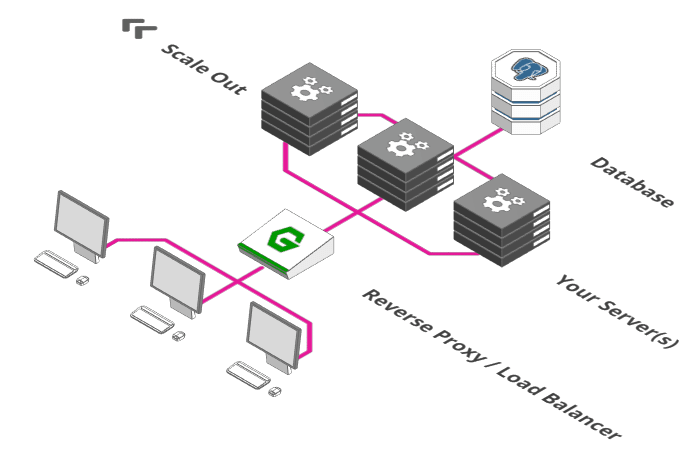 Fonte: https://arcentry.com/blog/scaling-webapps-for-newbs-and-non-techies/03-load-balancer-700.png
Fonte: https://arcentry.com/blog/scaling-webapps-for-newbs-and-non-techies/03-load-balancer-700.png
Aqui começa a ficar interessante e é um dos passos principais para atingir bons resultados de desempenho, além de ser o "núcleo" da escalabilidade de uma aplicação: Load Balancing. Se uma instância do seu servidor consegue processar 100 requisições simultâneas e você precisa que sua aplicação suporte 200, você adiciona outra instância do seu servidor e o seu load balancer irá rotear as requisições entre as duas instâncias de servidores ,criando, no final, uma aplicação só que suporta 200 requisições simultâneas.
Na prática, esse escalonamento deve ocorrer dinamicamente (a alocação de mais instâncias, talvez em outras máquinas, on-the-fly) e a própria API do Load Balancer deve dar suporte a isso. Você pode saber como fazer isso no Nginx aqui.
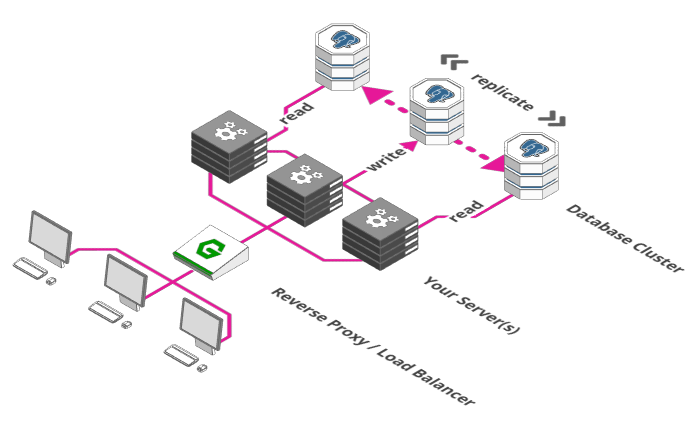
4. Escalando o banco de dados
 Fonte: https://arcentry.com/blog/scaling-webapps-for-newbs-and-non-techies/04-database-scale-700.png
Fonte: https://arcentry.com/blog/scaling-webapps-for-newbs-and-non-techies/04-database-scale-700.png
Uma hora ou outra o gargalo vai acontecer na camada do banco de dados da sua aplicação - por mais que você tenha servidores escalados, a lentidão e indiponibilidade vai recair sobre o banco de dados, que é compartilhado -, e, nesse caso, é mais complicado resolver apenas com uma replicação dinâmica do seu Load Balancer, isso porque deve ser uma requisito manter a consistência dos dados nas diversas instâncias do seu banco, e a solução para esse problema vai depender muito da engine de banco de dados que você irá utilizar. Uma solução "média" é dividir as réplicas do banco de dados em dois grupos: uma de escrita e outra(s) de leitura, configurando uma replicação master/worker, onde as escritas que uma instância realiza são replicadas para as instâncias de leitura.
Para grandes sistemas, talvez essa replicação não seja suficiente. Recomendo ler sobre conceitos mais avançados, utilizando o banco de dados PostgreSQL, aqui.
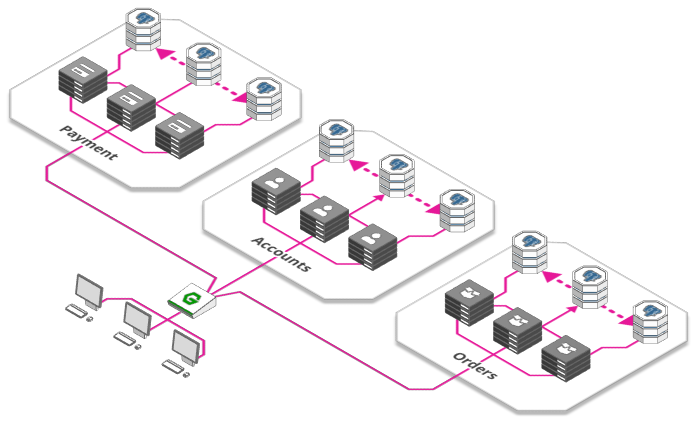
5. Microserviços
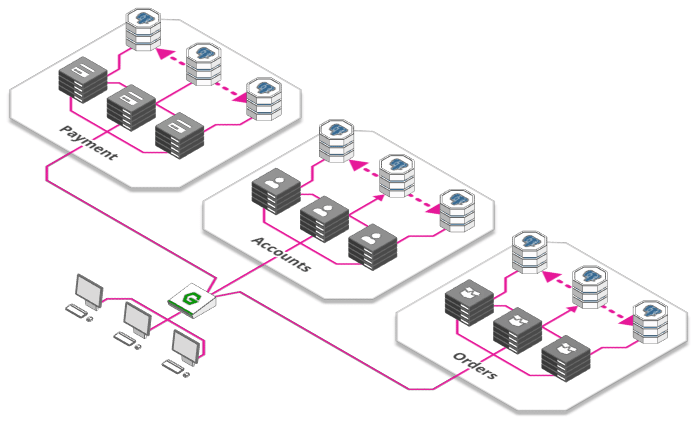 Fonte: https://arcentry.com/blog/scaling-webapps-for-newbs-and-non-techies/05-microservices-700.png
Fonte: https://arcentry.com/blog/scaling-webapps-for-newbs-and-non-techies/05-microservices-700.png
Essa buzzword dos últimos anos se popularizou como boa prática para estruturação de grandes sistemas, mas sua eficácia vai depender bastante do domínio da aplicação. Uma arquitetura de microserviços consiste em dividir o sistema em unidades lógicas - módulos - que se comunicam entre si como se fossem sistemas separados. Dessa forma, a escalabilidade pode focar em um serviço específico que tenha tal demanda, enquanto outra da aplicação que não precise de tanto recursos permanece intacta.
O uso de microserviços também pode auxiliar na divisão de trabalho dos desenvolvedores, onde podem haver times que são divididos pelos microserviços da aplicação, trabalhando independentemente de outros times da empresa, com seus próprios fluxos, além de poderem utilizar diferentes bancos de dados, diminuindo o problema no uso de um banco de dados centralizado.
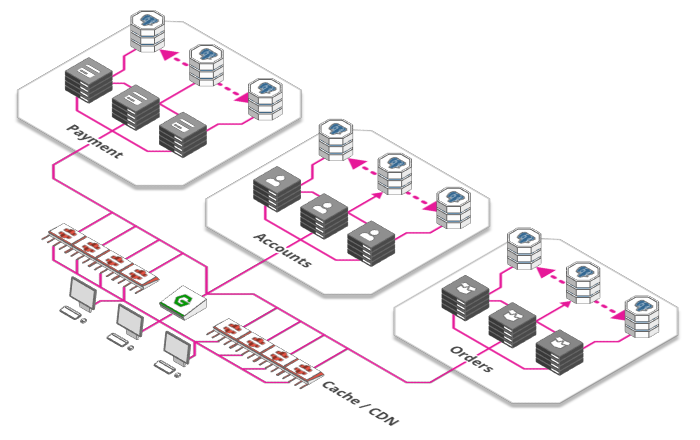
5. Caching
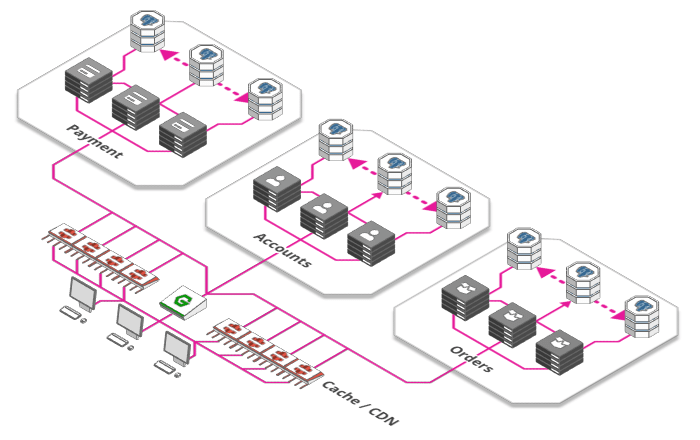 Fonte: https://arcentry.com/blog/scaling-webapps-for-newbs-and-non-techies/06-cdn-700.png
Fonte: https://arcentry.com/blog/scaling-webapps-for-newbs-and-non-techies/06-cdn-700.png
Essa sessão também será um dos pontos mais importantes em uma arquitetura de um sistema corporativo, e poderá ser aplicada ao longo de todo um fluxo de uso, como no cliente web, na "borda" do seu servidor, nas camadas de serviço, no banco de dados... Ao invés de sempre recalcular alguma resposta que não muda com frequência, ou buscar um arquivo estático no seu sistema, uma camada de cache vai "guardar" dados recuperados previamente e respondê-los imediatamente caso o mesmo pedido seja feito num tempo estabelecido (ou utilizando outra política).
Um cache bastante útil e distribuído globalmente é o CDN, sigla para Content Delivery Networks, e é utilizado na borda da aplicação, com foco na entrega de arquivos estáticos. A Cloudfare oferece várias opçÕes para que você possa configurar sua CDN, além de estar presente em várias localizações físicas pelo mundo, estando sempre perto do seu usuário final.
Já para um cache personalizado, que pode ser montado entre as camadas da sua aplicação, o banco de dados em memóriaRedis é uma boa opção.
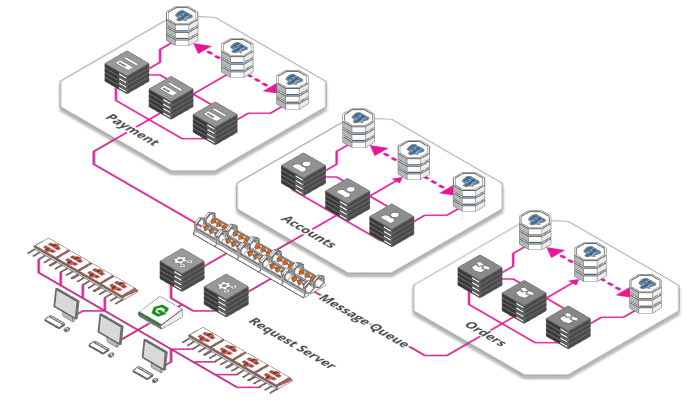
6. Filas de mensagem
 Fonte: https://arcentry.com/blog/scaling-webapps-for-newbs-and-non-techies/07-message-queue-700.png
Fonte: https://arcentry.com/blog/scaling-webapps-for-newbs-and-non-techies/07-message-queue-700.png
As filas de espera são tão antigas quando a falta de capacidade do ser humano de processar toda a demanda, e o seu uso em sistemas de informação não é muito diferente. Em uma arquitetura distribuída, em microserviços ou com vários servidores escalados, uma maneira eficiente de prover a comunicação entre os agentes internos é o uso de filas de mensagens, o que cria uma "tolerância a falhas e a latência" entre os serviços que se comunicam. Dessa forma, o pedido e a resposta se tornam mais desacoplados, impedindo que um serviço que processa várias requisições com rapidez fique parado por estar esperando um serviço que leva mais tempo para processar requisições. A fila funciona como um buffer.
Um exemplo de serviço de fila de mensagens para aplicações web é o SQS, da Amazon.
Conclusão
As boas práticas para planejar e manter um sistema corporativo são muitas e estão sempre em renovação, com apenas algumas delas sendo comentadas aqui. O mais importante é que isso motive-o a pesquisar mais sobre o tema e, além disso, estar sempre a par das soluções mais robustas que são usadas pela comunidades, por isso é importante a comunidade que você faz parte. Talvez algo que nunca mude seja o fato que não é uma tarefa simples e que demanda sempre um estudo cuidadoso quando for a hora de implementar alguma solução. O uso de uma arquitetura Serverless facilita bastante, mas também há trade-offs que devem ser verificados.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Top comments (0)