This article was originally published on Medium

It’s a great day at the office, the birds sing, the flowers bloom and the coffee is very pleasant. That day, the client told us about a new requirement that, at the time, we thought would be piece of cake… we were so wrong…
The client told to us that they needed to migrate all the content from their current CMS to the new Content Delivery Stream we were building. “Move content from one node to another” sounds quite easy, but there were a lot of problems to solve behind that phrase.
Old vs New
The client wanted a fancy, brand-new Content Delivery Stream including a Headless CMS, Serverless backend and a frontend to display the content of it. Their current CMS has a lot of problems: from poor client-side performance and a slow delivery stream, to server down-time.
The architecture we proposed looks like this:

CMS users can create and manage content inside a Headless CMS based on WordPress. When users publish an Article, the CMS sends it to the Content Stream. The Content Stream uses AWS Serverless Lambdas to transform and confirm the content. Content gets hosted on an ElasticSearch service. Web clients visit the frontend and can navigate on the website. The frontend was built in VueJS and Nuxt.js (server-side rendering for VueJS). The frontend fetches the data from ElasticSearch to display the content. For third-party news feeds, content is loaded using the WordPress REST API.
What are we going to move?
The requirement was clear for us:
The team needs to move around half a million articles from their old CMS into the new Content Delivery Stream. The content must be available for the frontend and for CMS users to manage inside it. The articles must show the same content as the old CMS and should be flexible enough to edit it in WordPress.
Designing the migration process
The client provided us an ElasticSearch endpoint containing all the data to be migrated instead of querying their database directly. At first we thought of doing a Migration from their ElasticSearch to our Delivery ElasticSearch to have the content ready for external visitors of the website but there was a problem with this approach: the content will not be available in WordPress to edit it and manage it. After seeing this problem, we started doing some research on getting the content “On Demand” using a similar process as the ElasticPress Plugin for WordPress. Because of the lack of time to do this requirement, we dropped the idea.
In the next iteration of this design process: we decided to insert the migrated Content into WordPress: we already had a Plugin that transforms the content and the metadata into the required schema that ElasticSearch needs; we only needed to convert every article from the client’s ElasticSearch to WordPress post schema.
For this, we thought in automating the ingest from ES client to our WordPress instance, our first choice was using the Amazon Simple Queue Service (SQS for short) to throttle the Content Ingestion. The plan was simple and this diagram was born:
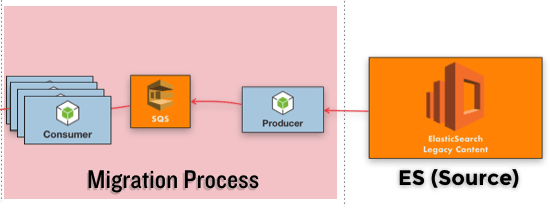
We only needed a SQS Producer (to grab from ES and ingest it to an SQS queue) and a couple of SQS Consumers (to listen to the queue and insert the messages into WordPress). Our technology choice was NodeJS because there are two easy-to-use SQS Producer and Consumer modules for NodeJS available in NPM.
At the time we were developing the SQS Producer we faced an important problem: ElasticSearch’s limit of 10K documents on from + size queries was causing this problem. To solve this, we decided to use the Scroll API to access to every document in chunks.
Other problem that we faced when we were developing the Producer was that if the process died, the state wasn’t saved and everything needed to be ingested again.
To avoid this problem we saved the state of which articles where ingested. To keep track of the last ingested document into SQS we saved the UUID of that document in a database every time the process runs again. It checks the latest UUID in the database. The Scroll API then knows from where to start, using the UUID.
The consumer process was easy to make. We created a NodeJS script that would listen to the queue and it would got data in chunks of ten. After, it would try to insert them into WordPress. If the process failed fifteen times, SQS would send the broken messages into a Dead Letter queue. To keep the process alive we used PM2.
After creating the SQS Producer and Consumers, we started developing the content transformers for the WordPress REST API. At first, we decided to get every dependency inside WordPress but we started to notice the requests took a lot of time. Transforming and fetching data inside the CMS was a lot of work for WordPress and MySQL. After a tough afternoon brain storming how to solve this problem, we decided to fetch all the dependencies in the SQS Producer. We transferred that work to Node instead of WordPress to avoid Requests timeout from the API.
After that change in the Producer everything started to go fine. We decided to start testing the migration process and noticed that MySQL and PHP were taking too long transforming and inserting the data into the CMS.
We decided to use Amazon Aurora to scale up the database power. Things started to look a little bit better after that but we noticed that the process was going to take many days to finish. With around 50 Articles per minute, the whole process would take forever so we decided to scale-up, the CMS, vertically.
We created a Terraform template to create a cluster of 5 WP instances with the same big power and all of them connected to Aurora. Every request passes through an Elastic Load Balancer (AWS ELB) and using a round robin will access to each instance.
At last, we had our first architecture design of the migration process:
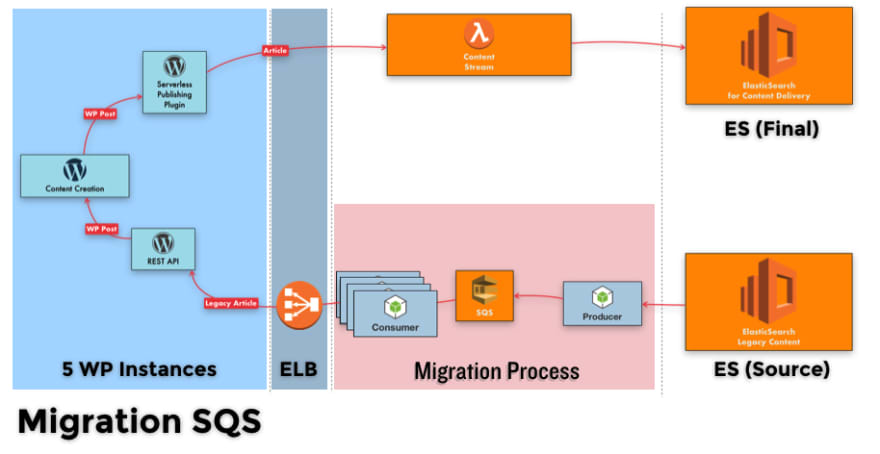
We were so proud at that moment because everything started to flow super nicely! but we knew this could be improved to speed up the process a little bit more. We decided to go to the next level by using Amazon Kinesis.

We decided to change the SQS Producer to be a hybrid supporting SQS and Kinesis ingestion. For the Consumer, we created a lambda function that gets triggered when a new event is ingested into Kinesis Stream. At that moment, we could get around 150 per minute and guess what! The process was too much for WordPress and started timing out. The answer was vertically-scaling up the EC2 instances. At last, our migration process with Kinesis was finished.
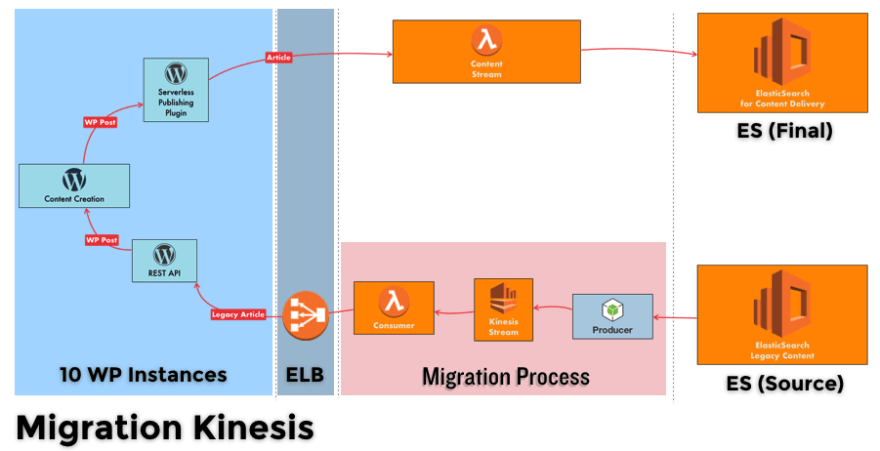
At this point everything started to going exceptionally well, extremely good time per requests, great number of requests per minute handled… Then everything started getting dark for us.
The bumps on the road
We thought at the moment we were out of trouble but we were so wrong. The first bump was when we hit 100k articles and everything came tumbling down:
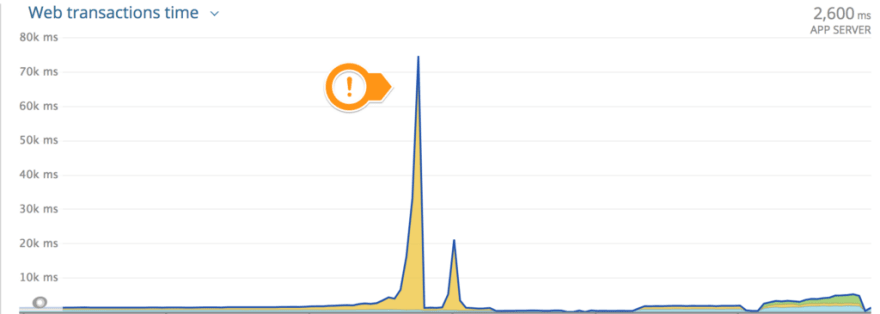
We were surprised by this: we never thought something like that peak could happen in the process until we noticed something interesting:

We noticed that getting the dependencies to send it to the Delivery Stream was taking too long «but WHY!?!» We noticed that the wp_postmeta table from WordPress had around 1.5 million rows, lots of the values weren’t indexed and required lots of time for MySQL to resolve. This problem was serious because we were facing a probable design problem in the way WordPress stored the Article metadata. To solve this, we installed the ElasticPress Plugin to save all the content from WordPress into another ElasticSearch instance. Everything started to run normally again!

Another problem we faced is, the process in Kinesis finished abruptly.

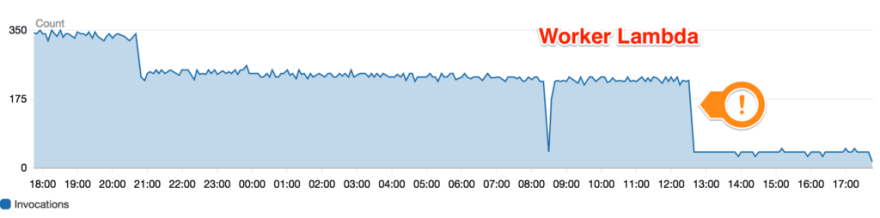
Fortunately, this just was a configuration problem that was solved easily by changing the data retention period of the event in the AWS Console

Another problem we faced in our tests, was the number of request per minute being at an incredibly slow rate when the database had around 1 million Articles:

To solve this, the operation team suggested us to use the HyperDB Plugin for WordPress to manage easily the read and writes replicas since we are using AWS RDS Aurora as Database Infrastructure. After the configuration of the plugin, the results were very satisfying:

Time to run the data migration
After all this bumps, we were finally able to run the data migration in the client’s infrastructure. We set up everything and we started the process at the first hour in the morning and after 10k articles we started noticing slowness in the process, time outs and very high CPU usage in the AWS Aurora cluster.
We made some tests again in our infrastructure and everything fine but their infrastructure wasn’t working! something fishy was going on. We were facing an interesting and unpredictable problem. So close yet so far, we started to debug the process using new relic and we noticed something interesting in their infrastructure:


After some exhaustive debugging, the architecture developer found a bug in the scalability strategy, the problem was fixed and the number of instances started to look more consistent but we still noticed slowness and we found this:
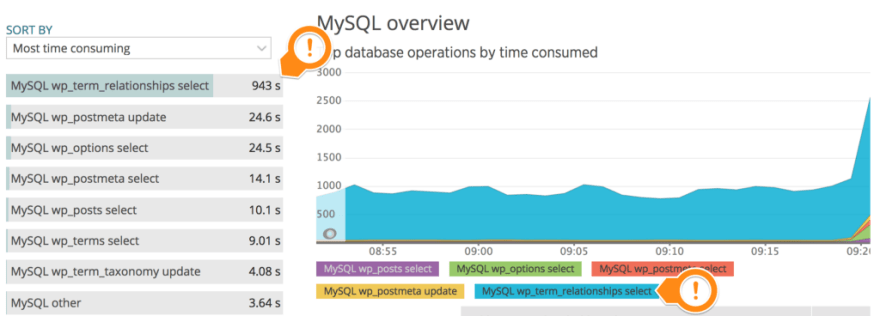

For some strange reason, that select was taking a lot of time and the database CPU was peaking up to 100% of usage. This problem was interesting to solve because we need to replicate the same problem in our infrastructure. We found that each post insert makes a request to that table to increase the count of terms. We clearly don’t need that for our CMS, so we made some query improvements and optimisations but the problem was still there. We decided to add a caching layer using Redis and the plugin Redis Object Cache and the result was better than we expected:
Before Caching
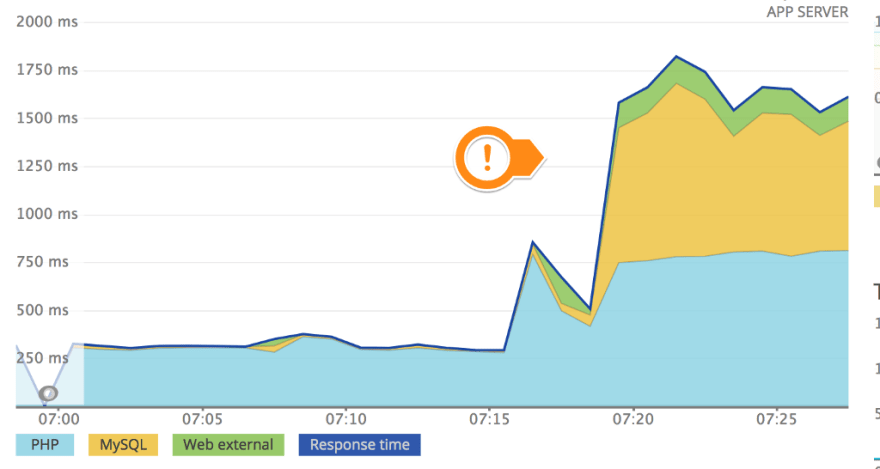

After Caching

Conclusion
A valuable lesson that we learned is that data migrations are not as easy as they sound. This whole experience helped us to understand data migrations better and the learn value was very high for us. Right now, the solutions provided in this article are effectively working for the content migration. I really recommend you to be part of a development process for this kind of projects.
Special Thanks
Thank you so much to Vero Leon, Eder Diaz, Rafa Salazar and Eduardo Romero for helping me making this article even better!





Top comments (0)