
Building resilient APIs with chaos engineering.
I don’t deal with failure well. But I’ve gotten better at it because I fail a lot. In fact, the more I fail, the better I anticipate all the ways I can possibly crash and burn and shore up those vulnerabilities.
This anticipation could keep me up at night, but I’m stronger for it instead.

On Better Practices, we’ve previously talked about how working in the cloud is growing increasingly complex as teams continue to adopt microservice and distributed architectures. Some approaches are to enable flexibility with an API-first approach or to increase velocity by using containers and an orchestration engine.
Another approach is with chaos engineering.
Distributed systems are inherently chaotic, and a number of organizations are embracing this chaos as they move to the cloud. They intentionally inject failure into their system in order to identify previously unknown vulnerabilities.
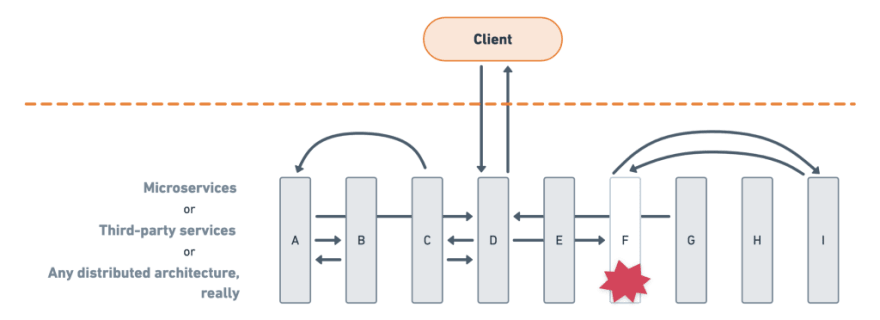
What happens when one of your dependencies fail? By proactively controlling the conditions of a failure, you can learn from your system’s response on your own terms, instead of during an unanticipated outage.
What is Chaos engineering?
When Netflix famously transitioned from a monolithic architecture over to a distributed cloud architecture, they worried about how potential downtime would impact their users. The Netflix team introduced Chaos Monkey to pseudo-randomly kill instances in order to simulate random server failure.
They wanted to make sure they could survive this type of failure and better understand the impact of such a failure on their customers. The goal was to fortify their distributed systems to expect and tolerate failure from other systems on which they depend.

-Casey Rosenthal, CEO at Verica
Shortly thereafter, the Netflix team introduced a virtual Simian Army, with each new Monkey tasked with inducing another type of failure — such as degrading a service or killing an entire region. Since then, the chaos community has developed a number of tools to more precisely cause chaos in a controlled manner.
Today, there’s a number of companies who have embraced the principles of chaos engineering. Some teams might focus on failure injection testing or disaster recovery training, while adopting only the tools and practices that work for their specific goals.
Across all of these programs, a disciplined approach teaches them how to improve their systems so they can better tolerate future, unplanned failures.
Why worry about something that isn’t going to happen?
Why look for trouble?
A chaos experiment is like running a fire drill. Imagine that you’ve already created an emergency protocol in case of a fire, sent it out to everyone, and you test the fire alarm once a month to make sure it’s functioning.

Now what happens when you run the fire drill? You might discover that there’s a few rooms where the alarm can’t be heard, most people don’t remember where they’re supposed to meet, while others ignore the drill and stay at their desks.
By proactively testing how a system responds to failure conditions, you can identify and fix failures before they become public-facing outages. Failures in production are costly, so Chaos Engineering lets you validate what you think will happen with what is actually happening in your systems.
“Breaking things on purpose” in order to build more resilient systems prepares your team in the event of an earthquake, a zombie attack, or whatever else comes your way.
Who is responsible for Chaos engineering?
In a microservice architecture, the engineers building the services frequently have responsibility for deployment and uptime. In an organization with a traditional DevOps team, those DevOps engineers may own these service levels. Some companies have specialized teams of Site Reliability Engineers (SRE) or Production Engineers (PE) tasked with continuous improvement and production support.
Initially, the people with the highest motivation to implement chaos engineering are those who feel the pain of a failure in production, like the ones on call.
I started doing [chaos engineering] so I would get woken up less in the middle of the night and better understand my software.
It boils down to who gets paged — if that’s an SRE or Ops team, they have the most incentive to start doing this work and making their lives better.
— Kolton Andrus, CEO at Gremlin
Other people with a vested interest are the ones tasked with incident management or post-mortem analysis. The difference here is that incident management is a reactive process with steps taken to prevent reoccurrence. With chaos engineering, your experiments are conducted proactively by anticipating what could go wrong.

Right now, the vast majority of people implementing chaos engineering tend to be quality-driven and production-focused operations engineers.
However, it also makes sense to introduce the responsibility of resiliency earlier in the development cycle, when the cost of bugs is lowest, to reduce financial and other consequences in production. As such, there’s an emerging trend of testers who focus on production testing in addition to traditional pre-release testing.
So who owns Chaos?
- Specialized roles — Site Reliability Engineers (SRE), Production Engineers (PE)
- Functional teams — DevOps, Test and Quality Assurance (QA), Research and Development (R&D)
- Domain knowledge experts — Traffic, database, data, storage
The initial owners of chaos engineering will be determined by your team’s current infrastructure, talent, and goals. Furthermore, this responsibility may shift as more organizations migrate to the cloud, and chaos engineering becomes more mainstream and begins to augment traditional testing.
How can you start a chaos program?
You don’t need a special job title or even Netflix-level traffic to begin dabbling in chaos. The chaos community has developed a number of shared resources to help advance this emerging discipline. Organizations like Google, Twilio, PagerDuty, and many more have adopted their own approaches to chaos engineering.
In some cases, it’s a curious tester who kicks off a single chaos experiment after notifying the rest of her team. Maybe it’s a handful of engineers huddled together to plan their failures during a gameday. Or it’s a directive from senior management to scope out a chaos program after one particularly costly outage.

Once again, the implementation you choose will be determined by your team’s current infrastructure, talent, and goals.
-Casey Rosenthal, CEO at Verica
A common pitfall is not clearly communicating the reasons why you are adopting chaos engineering practices in the first place. When the rest of the organization doesn’t yet understand or believe in the benefit, there’s going to be fear and confusion. Worse yet, there’s the perception that you’re just breaking stuff randomly and without a legitimate hypothesis.
How do you run a chaos experiment?
While there’s many ways to run your chaos experiments, most processes echo the scientific method with a continuous cycle of hypothesis and experimentation.

Plan an experiment. First, create a hypothesis about the steady-state behavior of your systems. Focus on if your systems do work, not how they work. Then think about what could go wrong. Perhaps a server goes down (as they do). Maybe it’s your third-party payment system, a specific cluster, or an entire region that’s experiencing an outage.
Start small. Initiate an attack that’s small enough to give you information about how your systems react in a production environment. You can’t always predict how users will behave. Instead of testing code in an isolated environment, test a complete system in production comprised of users, code, environment, infrastructure, a singular point in time, and more.
Measure the impact. Observe the impact of your attack by comparing it to your steady-state metrics to reveal any known and unknown issues. At this point, you can either turn up the juice on your attack or roll it back if there were unintended and potentially harmful side effects.
Learn more about your systems. Validate or update your hypothesis, and shore up your vulnerabilities. Make these improvements, and then be prepared to automate your experiments to run continuously.
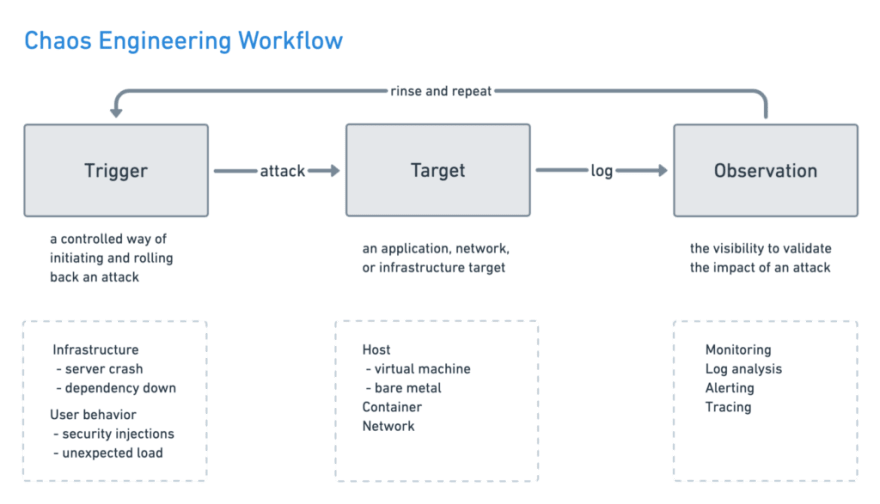
Just like a fire drill, your team is developing a muscle memory by practicing how to respond when the stakes are controlled, instead of practicing during an actual emergency. By methodically performing these automated tests, you can learn more about your systems’ real-world behavior.
If you’re just getting your feet wet with chaos engineering, consider starting with your APIs. We’ve previously talked about using APIs to create additional load or security injections and other user behavior. Now you can test your fallbacks by simulating the outage of external third-party APIs or killing your own internal APIs.
When a company measures their critical services, APIs are often considered second-class citizens.
- Tammy Butow, Principal Site Reliability Engineer at Gremlin
One way to experience an API outage is by simply unplugging a server. But what if the servers aren’t yours, or they’re hard to reach? Or you realize you’ve unplugged the wrong machine? Oops. You can’t just plug it back in and expect service to resume right away. Don’t do that.
Another way to experience an API outage is by using a Postman mock to return a 500 internal server error. This works, but it’s still just a simulation. While we can simulate outages in a test environment, there’s only one way to capture the unquantifiable conditions that cannot be replicated in an isolated test environment.
Eventually we want to break stuff in production 😈
A Postman recipe for creating chaos with Amazon EKS and Gremlin

Let’s start with an example e-commerce app where users can browse items, add them to the cart, and purchase them. Then we’ll shut down a container and see what hijinks ensue.
- Trigger: Gremlin is a failure-as-a-service and offers a free version with limited attack types. We’ll be using Postman with the Gremlin API to trigger our attacks. Spoiler alert . . . this is so we can easily automate these chaos tests with our continuous integration pipeline.
- Target: We’ve previously talked about deploying scalable apps with Docker and Kubernetes. Amazon EKS is a managed Kubernetes service that runs on AWS. It ain’t cheap. If you’re already running on hosts, containers, or another cloud platform, swap out EKS with your own target.
- Observability: We’ll use Prometheus as our time-series database and Grafana to visualize the effects of our attacks. Both are open-source and have a free version. If you’re already using something else for steady-state monitoring, swap out Prometheus and Grafana with your own toolset.
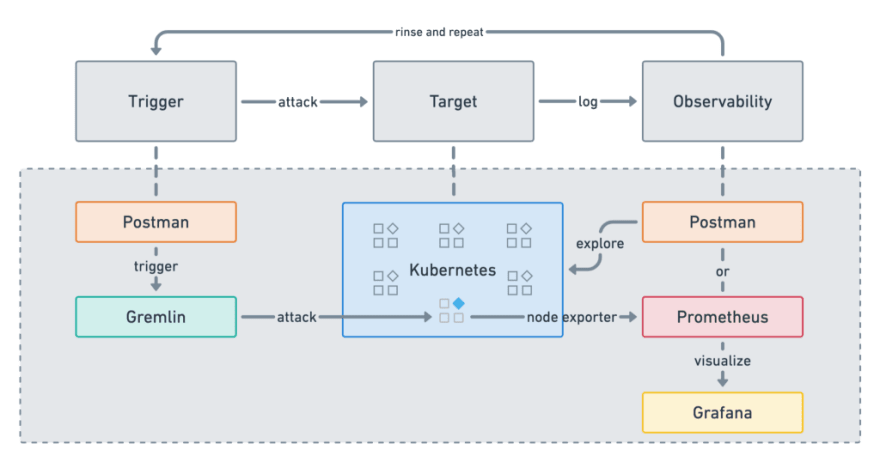
Set up Gremlin and create a Kubernetes cluster on EKS
If you want to jump to the end, go ahead andclone this example. Otherwise, let’s begin with this helpful guide to install Gremlin to use with Amazon EKS. You’ll need an AWS account, the AWS CLI configured to use eksctl to create the EKS cluster, and a Gremlin account.
- Step 0 — Verify your account AWS CLI Installation
- Step 1 — Create an EKS cluster using eksctl
- Step 2 — Load up the kubeconfig for the cluster
- Step 3 — Deploy Kubernetes Dashboard
- Step 4 — Deploy a Microservice Demo application
- Step 5 — Run a Shutdown Container Attack using Gremlin (skip)
After that, you should have a sample app deployed on AWS EKS and Gremlin running on your Kubernetes dashboard.


Set up Grafana and Prometheus
If you’re still with me, let’s set up Monitoring Kubernetes Clusters with Grafana. This particular guide starts with Google Kubernetes Engine (GKE) instead of EKS, but most of the remaining steps are the same after you create your cluster.
- Step 0 — Create a GKE cluster (skip)
- Step 1 — Lots and lots and lots of yaml configuration
- Step 2 — Configure your cluster settings on Grafana (skip)
Instead of configuring your cluster settings on Grafana, you can simply import an existing dashboard if your monitoring tools are running on your cluster. Check out the README inthe sample repo for more details on how to manage external access to the apps running inside the cluster.
After that, you should be able to observe the steady-state metrics of all the nodes in your cluster.
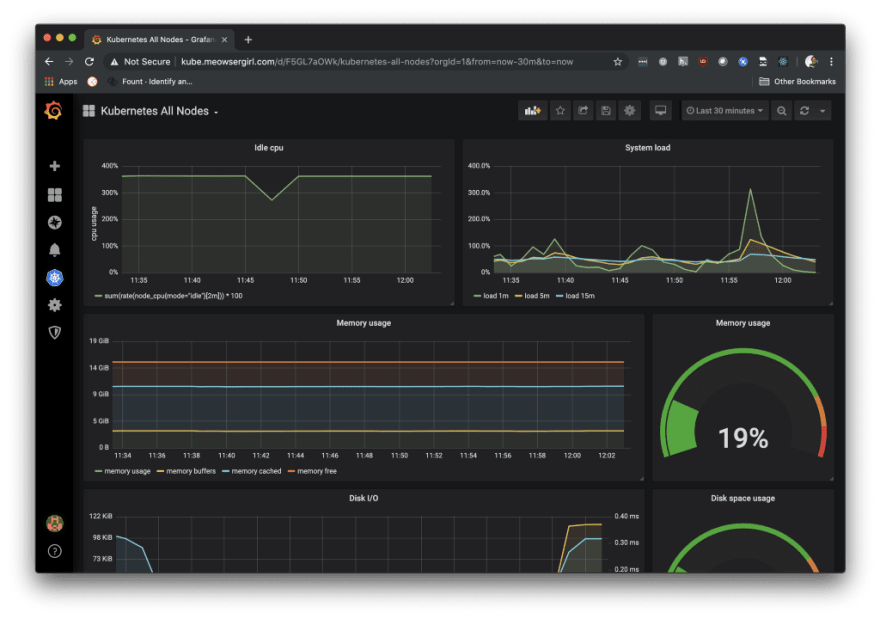
Programmatically manage your chaos experiments
A Kubernetes pod is composed of one or more containers that share a network stack. If we attack a single container within a pod, the impact should be observed for all containers collocated within that pod. Optionally, we can further specify container ports to restrict the impact of our attack.
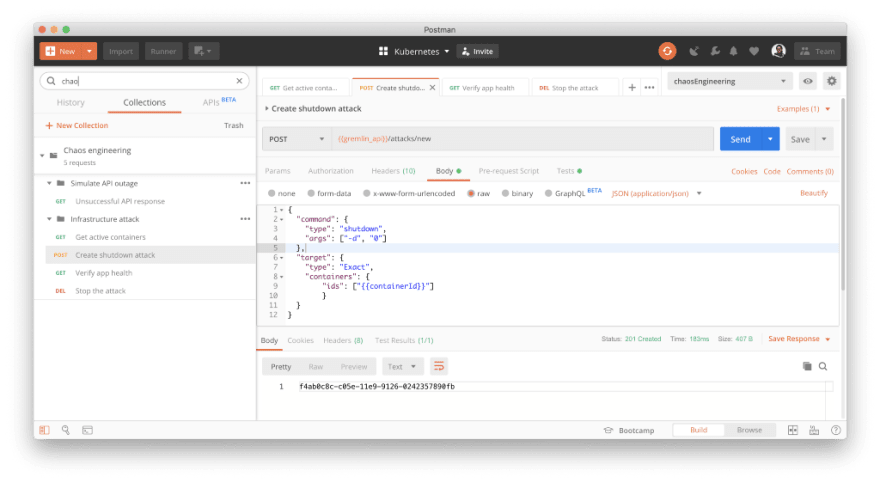
In the last step of the Gremlin tutorial, we shut down a container using Gremlin’s UI. We could also use an API to run our attacks so that we can programmatically manage our chaos experiments.
Let’s use Postman to shut down a single container via the Gremlin API.
In the Postman app, import the template Chaos engineering which includes a corresponding environment chaosEngineering. Check out the Chaos engineering documentation for step-by-step instructions.

You’ll first need to update the Postman environment with your gremlin_api_key and your_deployed_app_url. Then look for the folder called Shut down a container.
- Get a list of our active containers
- Shut down a specified container
- Verify the health of our app
- Stop the attack (if you need to)
Our hypothesis is that if we shut down the container running cartservice, EKS will give us a new one, and we won’t suffer any downtime. However, if we experience unintended effects, let’s be prepared to stop the attack.
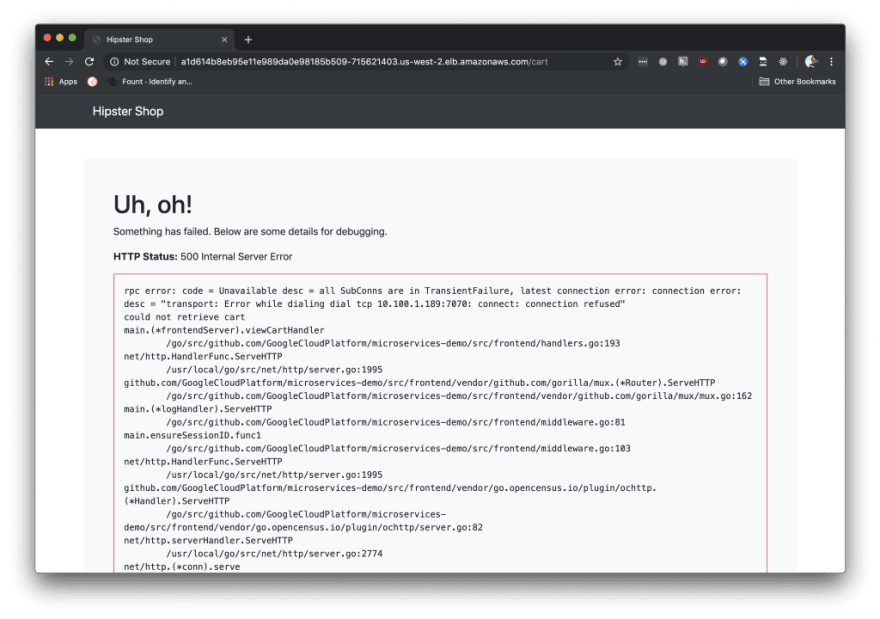
Yikes! When we shut down the cartservice container, we see a 500 error on our shopping cart page. We see this in our browser and also in Postman if we make a GET request to our deployed app’s URL.
If you completed the last step of the Gremlin tutorial, you already know this is because cartservice uses Redis instead of Redis Cluster. Now that we have revealed this vulnerability, we can have a broader discussion with other team members about your data solution.
In the meantime, let’s make a DELETE request using the Gremlin API to stop our attack, and add some code to Postman to only stop our attack if we see a 500 internal server error.
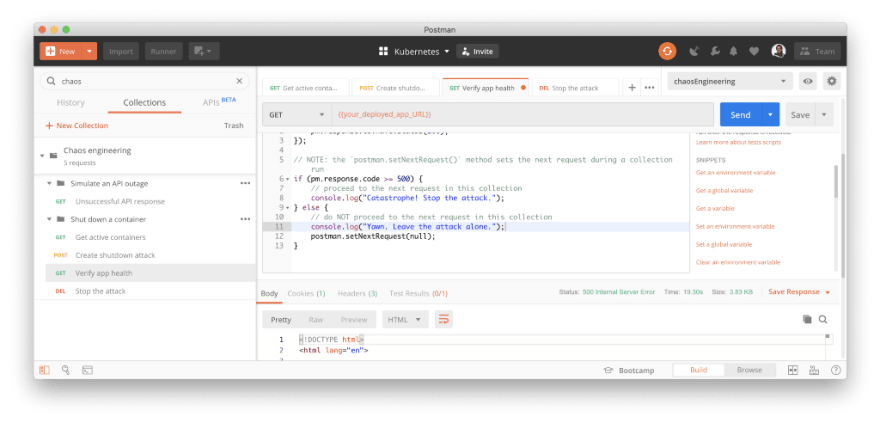

In this manner, we can use Postman and the Gremlin API to explore what happens when we break a specific part of our system. Beyond manual testing, however, we’ve also seen how to automatically run our integration tests using the collection runner and a little bit of code.
🎓 Advanced challenge: now that we know how to use the Postman app to manage our chaos experiments, how can we can automate chaos testing with our continuous integration (CI) pipeline or continuous testing process? Here’s a clue. And here’s a better clue.
A final thought about Chaos Engineering
So what happens when one of your dependencies fail? A valuable chaos test will not only teach you about your systems, but also your people. The human response is frequently one of the more difficult aspects to test in a proactive and systematic fashion. It’s probably easier to test the impact of a server crash.
When chaos experiments impact production traffic and users in real life, other teams will be impacted and hopefully notified before any experiments begin. Your team’s ability to communicate and collaborate will inevitably impact the resiliency of your systems.

The biggest limitation in the fear of delivering software faster is the focus on adding more pre-release testing.
Chaos engineering is all about building trust in our resiliency and mean time to recovery. In time, we have less fear that any one change will bring down our products and when issues do occur, we are practiced in triaging and deploying fixes faster, building confidence that we aren’t fragile.
- Abby Bangser, Platform Test Engineer at MOO
For many teams, chaos engineering will require a mental shift in how failures are perceived in the organization. It’s great to identify a failure and bring it to the attention of the rest of your team. However, it’s even better to create a process that anticipates potential failures, and then reveals new information to help shore up your vulnerabilities.
Chaos engineering is not just about building more resilient software, but also building a culture of resiliency within an organization. A team that truly celebrates failures, instead of hiding them, will enable the broader organization to learn and grow stronger from these experiences.





Top comments (0)