Overview
Do you want to understand how to turn the increasing quantities of data gathered by your business into actionable insights?
Before getting the important insights you need from BI tools and analytic applications, it's important to first understand a bit about cloud-based data warehouse solutions, which provide the bedrock for performing high-level data analysis and BI in modern enterprises.
In this post, you'll learn what exactly a cloud-based data warehouse is, how the important process of ETL relates to the data warehouse, and you'll get a comparison on two of the major cloud-based data warehouse solutions currently available—Amazon Redshift and Google BigQuery.
By the end of this post, you will be much better placed to choose a cloud-based data warehouse solution that provides a solid platform for analyzing your data and getting the insights from that data that can drive better business decisions.
What is a Cloud-Based Data Warehouse?
Cloud-based data warehouses are centralized repositories of data that utilize cloud infrastructure. In the cloud, a network of remote servers and computing resources are used to provide a data warehouse, instead of local servers hosted on-premise. Before you dive in further, check out this article by Panoply about the benefits of a data warehouse, and this definition and discussion of Redshift by TechTarget.
Data warehouses are vital for the success of any data analytics effort. Traditional on-premise data warehouses are extremely time-consuming and complex to build, requiring a significant investment in physical resources.
The cloud offers important advantages versus the traditional data warehouse, such as:
- There's no need for companies to invest in data warehouse centers or other physical resources hosted on-site
- Cloud data warehouse providers offer effortlessly scalable infrastructure and high performance
Several companies provide cloud-based data warehouse services. Some popular examples include:
- Amazon Redshift—this is a fully managed data warehouse service that requires database admins to provision resources just like they would in an on-premise warehouse. The difference being, of course, that there are no physical resources needed on-site—you can take advantage of AWS (Amazon Web Services) vast cloud infrastructure and customize it to your specific needs. Amazon Redshift is by far the most widely used cloud-based data warehouse—60 percent of attendees at the 2016 Amazon Re:Invent cloud conference said they use Redshift.
- Google BigQuery—Google BigQuery is a serverless service, meaning it abstracts away the provisioning, assigning, and maintaining of resources from its users. At its core, BigQuery uses a query engine that can pore through billions of rows of data at high speed.
- Azure SQL Data Warehouse—this is Microsoft's cloud-based data warehouse offering. The Azure SQL data warehouse is both scalable and fully managed, making it similar to Amazon Redshift.
- Snowflake—Snowflake is a cloud-based data warehousing service that allows users to store data on Amazon S3 and analyze that data using a query engine. Each cloud-based data warehouse service comes with its own pros and cons. At present, Amazon Redshift and BigQuery are two popular options, offered by two of the world's leading cloud providers, so it makes sense to compare them to understand what you can expect from these services.
Before comparing Redshift and BigQuery, though, it's important to understand the ETL process and how it relates to data warehousing.
What is ETL in the Data Warehouse
All enterprises that want to analyze historical data within a single data repository such as a data warehouse are faced with a common challenge—how to extract data from disparate sources, get that data into a cleansed, unified format, and load the data into the warehouse for use with BI tools and analytic applications.
ETL (Extract, Transform, Load) is one of the oldest methods for getting data from source systems to the data warehouse—something that is still required even with cloud-based systems. ETL uses a separate transformation engine outside the data warehouse to get data into an aggregated, structured format ready for warehouse use.
Some experts argue that the powerful modern cloud-based warehouses negate the need for a separate transformation process—data can be extracted in its raw form from sources and loaded instantly into the warehouse for unparalleled accessibility. Within the warehouse, queries can transform the data as it is needed by analysts.
The counter argument to ETL being outdated is that it requires significant knowledge beyond the scope of the layman BI analyst to manipulate and understand raw data. Consolidated data that uses a common structure and is understandable in business terms is required for many analysts to gain insights from that data.
Next you'll find out the differences and similarities between BigQuery and Redshift, including how to ETL data into these systems, and whether ETL is actually needed in both Redshift and BigQuery.
Redshift vs. BigQuery
The following points outline how BigQuery and Redshift compare with each other:
Cost
Redshift has a straightforward cost structure in which you pay either on-demand as you use cloud instances or you can get a cheaper rate by reserving cloud instances for up to three years. In BigQuery, you pay for storage at a rate of $0.02/GB and querying at $5 per GB data processed.
The separation of querying and storage makes BigQuery's cost structure both unpredictable and complex compared to Redshift. Furthermore, while BigQuery initially appears cheaper than Redshift, once you use the data by querying it in BigQuery, it quickly becomes more expensive than Redshift.
Performance
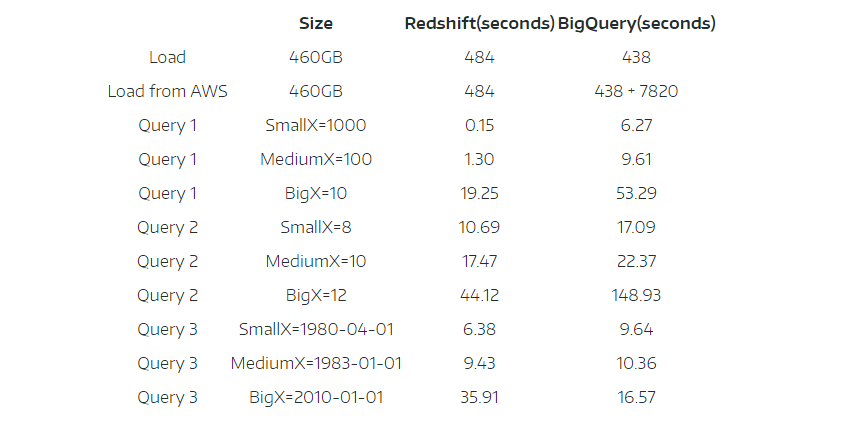
The below table shows how the two services performed when querying the same dataset with three different queries. Note that Redshift has been optimized for performance in this test with data compression and sort keys, which is more indicative of how it would be used.
ETL
Redshift's powerful infrastructure ensures it can quickly transform raw data within the service, which is known as an ELT data integration approach.
However, there are several tools available that can prepare data for use with Redshift by rapidly performing ETL for you, so that you don't tie up cluster resources. The advantage of ETL to Redshift services is that the users such as analysts can immediately begin querying the data with their analytic tools once it's loaded into Redshift—there is no need to aggregate, join, or otherwise cleanse the data.
BigQuery relies upon ETL for getting data from transactional databases into its system for analysis. This article gives an overview of how to perform ETL from a relational database into BigQuery. Without ETL in BigQuery, expect to pay a lot of money to transform the data using BigQuery UI.
Usability
By abstracting away details of underlying hardware and configurations, BigQuery is easier to use. However, once it's set up, Redshift is simple to work with for analysts. Both BigQuery and Redshift integrate well with all popular BI tools.
Both databases support a wide range of classic data types, like text, integers, floats, and booleans. BigQuery doesn't allow user-defined precision for stored values, while Redshift does. User-defined precision is important in applications where exact numeric operations are required, such as for financial data analysis. Both platforms have excellent documentation available, ensuring most issues you encounter while using the services have a clear solution.
Architecture
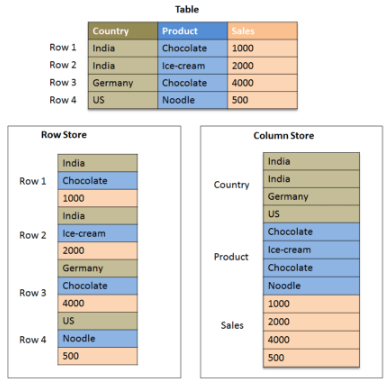
Even though the actual computing resources used in BigQuery are hidden from the end user, both BigQuery and Redshift have similar architectural structures. Both use massively parallel processing (MPP), which distributes queries across multiple servers for fast query execution. Additionally, both services use a columnar storage structure, making analytical queries much easier and faster to run.
Redshift vs. BigQuery - Which Should You Choose?
Redshift outperforms BigQuery in most analytical use cases, and it also has a simpler, cheaper cost structure. BigQuery is easier to get started with, but Redshift's customizability and its capability to store values with user-defined levels of precision make it more flexible.
Both Redshift and BigQuery have similar architectural designs and both services are ideal for use with high-speed modern ETL tools that can quickly extract, prepare, and load data for analytical use.
Redshift is the most popular cloud-based data warehouse service for a reason—it is the best.
Closing Thoughts
- Enterprises are quickly realizing how beneficial cloud-based data warehouses are for analytical purposes. Amazon Redshift and Google BigQuery are two examples of popular cloud-based warehouse solutions.
- Even with a cloud-based data warehouse service, you still need to figure out the best way to get data from all your source systems inside the data warehouse for analysis and reporting—ETL is one such method to achieve this.
- When deciding on a cloud-based data warehouse solution, it's important to consider factors such as cost, usability, performance, design, and whether it supports ETL or another data integration method.





{kind=link}
Top comments (0)