
Hello again! Let's talk about CUDA and how it's gonna help you to speed up the data processing.
No code today! Only theory 😎
Imagine, if you had known there will be no CUDA in the world you would still train any of neural networks forever 🙁 So, what the heck is CUDA?
Intro
CUDA is a parallel computing platform and application programming interface (API) model created by Nvidia (source).
Before we begin, you should understand what is:
- device - video card by itself, GPU - runs commands received from CPU
- host - central processor (CPU) - runs certain tasks on device, allocates memory, etc.
- kernel - function (task) that will be ran by device.
CUDA allows you to implement algorithms using special syntax of C language. The architecture of CUDA let you organize GPU instructions access and manage its memory. All in your hands, bro! Be careful.
Good news - this technology is supported by several languages. Choose the best one 😉
Magic? No 😮
Let's find out how code is launched by GPU.
- host allocates some memory on device;
- host copies the data from its own memory to device's memory;
- host runs kernel on device;
- device performs that kernel;
- host copies results from device's memory to own memory.

There is no step 1 (allocating memory) on figure, but steps 1 and 2 can be merged.

CPU interacts with GPU over the CUDA Runtime API, CUDA Driver API and CUDA Libraries. The main difference between Runtime and Driver API is pretty simple - it's a level of abstraction.
Runtime API (RAPI) is more abstract, aka more user-friendly. Driver API (DAPI) - a low level API, driver level. In general, RAPI is an abstract wrapper over the DAPI. You can use both of them. I can tell you from my experience it's more difficult to use DAPI, because you should think about low-level things, that's not funny 😑.
And you should understand another thing:
If the time spent on creating the kernel will be greater than the time of this kernel actually running, you'll get zero efficiency.
Anyways, the thing is launching tasks, allocating memory on GPU takes some time, therefore you shouldn't run "easy" tasks on it. Easy tasks can be performed by your CPU in milliseconds.
Should you run a kernel on the GPU even if the CPU can compute it more quickly? Actually no... Why? Let's find it out!
Hardware
The architecture of the GPU has built a bit differently than the CPU. Since graphic processors were originally used only for graphical calculations involving independent parallel data processing, the GPU is designed for parallel computing.

The GPU is designed to handle a large number of threads (elementary parallel processes).
As you can see, the GPU consists of many ALU merged in several groups with common memory. This approach can speed up productivity, but sometimes it's hard to program something in that way.
In order to achieve the best acceleration, you must think about the strategy of memory accessing and take into account the GPU features.
GPU is oriented for heavy tasks with large volumes of data and consists of streaming processor array (SPA), that includes texture processor clusters (TPC). TPC consists of a set of streaming multiprocessors (SM), each of them includes several streaming processors (SP) or cores (modern GPU can have more than 1024 cores).
GPU cores work by SIMD principle, but a bit different.

SP can work with different data, but they should execute the same command at the same moment of time. Different threads execute the same command.
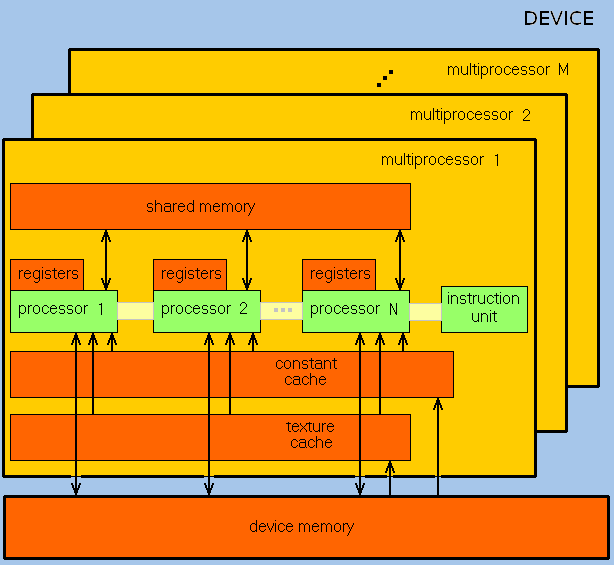
As a result, the GPU actually became a device that implements a stream computing model - there are streams of input and output data, which consist of identical elements, which can be processed independently of each other.

Compute capabilities
Every single GPU has its own coefficient of productivity or compute capabilities - quantitative characteristic of the performance speed of certain operations on the graphic processor. Nvidia called that Compute Capability Version. Higher version is better than lower 😁
| Compute Capability Version | GPU Chip | Videocard |
|---|---|---|
| 1.0 | G80, G92, G92b, G94, G94b | GeForce 8800GTX/Ultra, Tesla C/D/S870, FX4/5600, 360M, GT 420 |
| 1.1 | G86, G84, G98, G96, G96b, G94, G94b, G92, G92b | GeForce 8400GS/GT, 8600GT/GTS, 8800GT/GTS, 9400GT, 9600 GSO, 9600GT, 9800GTX/GX2, 9800GT, GTS 250, GT 120/30/40, FX 4/570, 3/580, 17/18/3700, 4700x2, 1xxM, 32/370M, 3/5/770M, 16/17/27/28/36/37/3800M, NVS420/50 |
| 1.2 | GT218, GT216, GT215 | GeForce 210, GT 220/40, FX380 LP, 1800M, 370/380M, NVS 2/3100M |
| 1.3 | GT200, GT200b | GeForce GTX 260, GTX 275, GTX 280, GTX 285, GTX 295, Tesla C/M1060, S1070, Quadro CX, FX 3/4/5800 |
| 2.0 | GF100, GF110 | GeForce (GF100) GTX 465, GTX 470, GTX 480, Tesla C2050, C2070, S/M2050/70, Quadro Plex 7000, Quadro 4000, 5000, 6000, GeForce (GF110) GTX 560 TI 448, GTX570, GTX580, GTX590 |
| ........ | ......... | ........ |
| 5.0 | GM107, GM108 | GeForce GTX 750 Ti, GeForce GTX 750, GeForce GTX 860M, GeForce GTX 850M, GeForce 840M, GeForce 830M |
| ........ | ......... | ........ |
You can find the whole list here. Compute Capability Version describes a lot of parameters such as quantity of threads per block, max number of threads and blocks, size of warp and more.
Threads, blocks and grids
CUDA uses a lot of separate threads for computing. All of them are grouped in hierarchy like that - grid / block / thread.

The top layer – grid – is related to the kernel and unites all threads performing that kernel. Grid is an 1D- or 2D-array of blocks. Each block is an 1D / 2D / 3D array of threads. In this case, each block represents a completely independent set of coordinated threads. Threads from different blocks cannot interact with each other.
Above, I mentioned the difference from the SIMD architecture. There is still a concept like warp - a group of 32 threads (depending on the architecture of the GPU, but almost always 32). So, only threads within the same group (warp) can be physically executed at the same moment of time. Threads of different warps can be at different stages of the program running. This method of data processing is called SIMT (Single Instruction - Multiple Threads). Warp's management is carried out at the hardware level.
In some cases GPU is slower than CPU, but why?
Don't try to run easy tasks on your GPU. I'm gonna explain that.
- Delay - it's the waiting time between requesting for a particular resource and accessing that resource;
- Bandwidth - the number of operations that are performed per unit of time.
So, the main question is: why does a graphics processor sometimes stumble? Let's find it out!
We have two cars:
- passenger van - speed 120 km/h, capacity of 9 people;
- bus - speed 90 km/h, capacity of 30 people.
If an operation is the movement of one person at a certain distance, let it be 1 kilometer, then the delay (the time for which one person will pass 1 km) for the first car is 3600/120 = 30s, and the bandwidth is 9/30 = 0.3.
For the bus it's 3600/90 = 40s, and the bandwidth is 30/40 = 0.75.
Thus the CPU is a passenger van, the GPU is a bus: it has a big delay, but also a large bandwidth.
If the delay of each particular operation is not as important as the number of these operations per second for your task it is worth considering the use of the GPU.
Thoughts
The distinctive features of the GPU (compared to the CPU) are:
- architecture, maximally aimed at increasing the speed of calculation of textures and complex graphic objects;
- The peak power of the typical GPU is much higher than that of the CPU;
- Thanks to the specialized pipelining architecture, the GPU is much more effectively in processing graphical information than the CPU.
In my opinion, the main disadvantage is that this technology is supported only by Nvidia GPUs.
The GPU may not always give you an acceleration while performing certain algorithms. Therefore, before using the GPU for computing, you need to think carefully if it is necessary in that case. You can use a graphics card for complex calculations: work with graphics or images, engineering calculations, etc., but do not use the GPU for simple tasks (of course, you can, but then the efficiency will be 0).
See ya! And remember:
When using a GPU it's much easier to slow down a program than that speed it up.

Top comments (0)