I'm sure a lot of people have heard of Absorbing Markov Chains mainly because of Google Foobar. One of the levels there was to, given an input of a bunch of states and chances to go between the different states, find the percentages of going from one state to a "terminating" state in an unlimited number of steps. When I got to that question, I did not have time to learn this technology. I am very embarrassed to admit that because I can't let things go... I cheated that challenge by hard-coding the answers from somewhere online. I hope there's a button somewhere to redo it - I can't check right now because it's down for maintenance.
I think the least I can do to make up for my mistake is to make the guide I wish I had, so even somebody like me can understand them. Here we go:
Why use Absorbing Markov Chains?
Absorbing Markov Chains can calculate the percentage to go from one state to another, even if such a calculation loops forever.
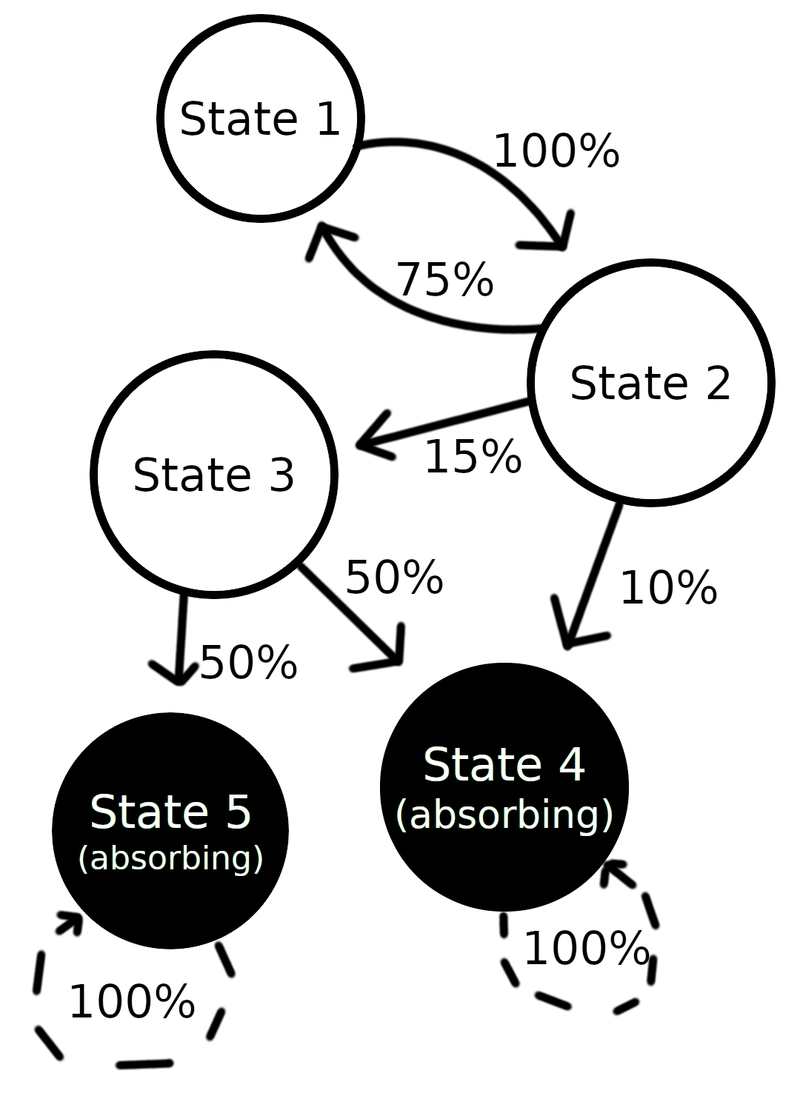
They can be as simple or complicated as you like.
Understanding
Before I go on, I would like to point out that some of the following images have been remade as SVGs so you can infinitely zoom them without losing quality. Because dev.to's CDN just converts them to PNGs, you can find them all here.
1. Convergence
Initially the biggest question to me was: How can there be a finite answer? Won't there be an infinite number of combinations?
Imagine a box being built by materials that are half the size of the existing material. Since you can divide infinitely, is there really a finite answer?
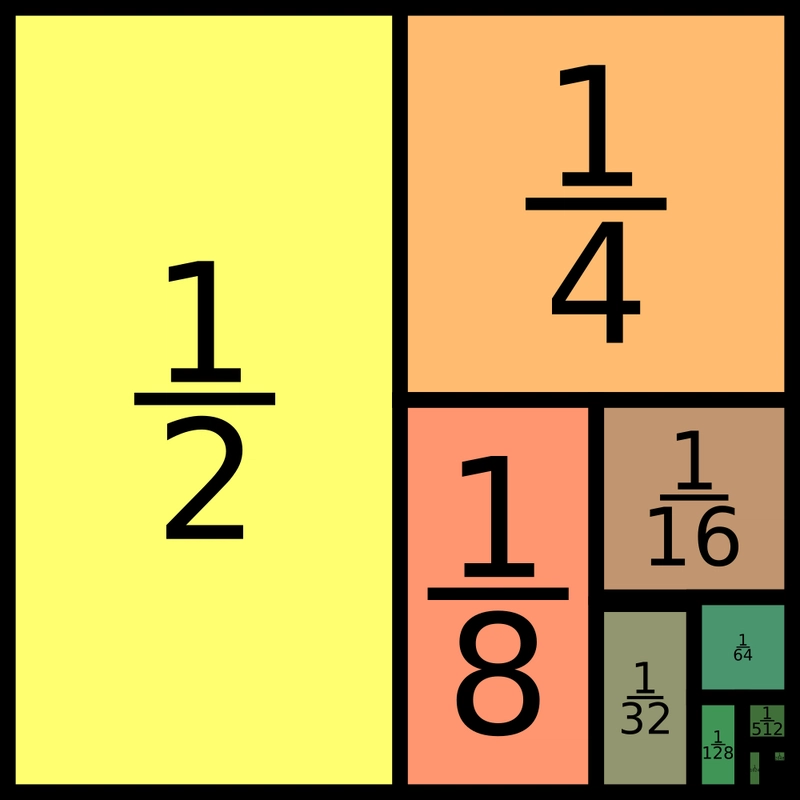
... Well! Since the box is slowly working towards 1 infinitely, we can just count 1 as the finite answer.
Similarly,
1/2 + 1/4 + 1/8 + 1/16 + ... = 0.9999999... ≈ 1
Notice I used the "almost equal to" sign there. But technically, I didn't even need to. Because in math, there's proof that 0.99999999... IS 1! The secret lies in the fact that infinity has some quirky rules. Here, let me show you something a friend showed me recently:
// As you know:
9x = 10x - x
// Now do this on 0.99999...
x = 0.99999...
0.99999... * 10 = 9.99999...
9.99999... - 0.99999... = 9
// Therefore...
0.99999... * 9 = 9
0.99999... = 1
This works because normally when you multiply by ten, you add one more number before the decimal point and remove one after it. But since removing one from infinity is still infinity, there's still the same amount of numbers after the decimal point, which means they cancel out.
2. Crash course on matrices
Before we continue, I need to give a few crash courses. If you already feel comfortable with any of these subjects you can skip over them if you like. I'll try my best to keep it short and to the point while still being clear!
Matrices are just like 2 dimensional arrays in programming. Doing addition and subtraction on two matrices creates a new matrix where each value in the first matrix is added/subtracted with the corresponding value in the other matrix.

Although, multiplying two matrices is more difficult: Each row/column combination creates a new number in the result matrix that is the sum of each element in the row multiplied with the corresponding element in the column. This means the number of columns in the first matrix must be the same as the number of rows in the second matrix. The result will have the same number of rows as the first matrix and same number of columns as the second.
Yep, this is confusing. Here, let me show you:
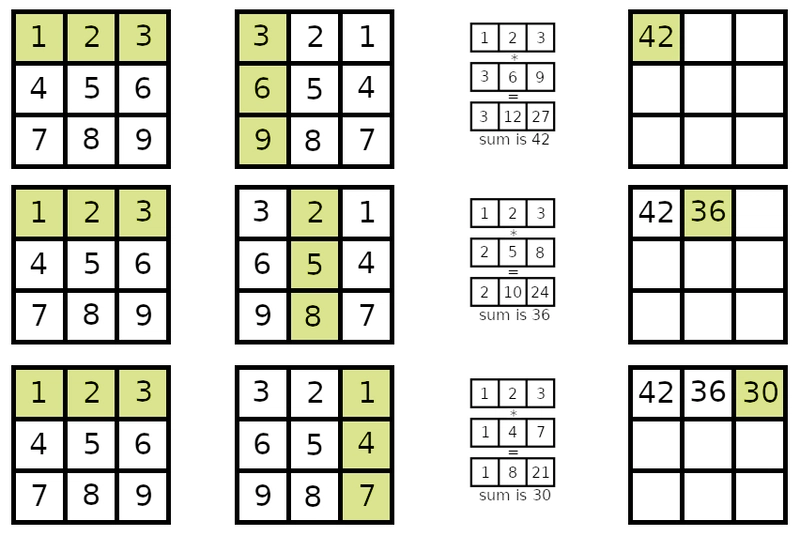
Then, in the above image, it'll do the same thing for every row.
This means that unlike normal numbers multiplying two matrices might give different results depending on the order.
Multiplying a normal number by 1 gives itself. The matrix alternative to this is something called the "identity matrix", which is very simply a bunch of ones on the diagonal.
3. Crash course on matrix inversion
Now, as you might know, inverting something in math is written as taking something to the power of minus one, ^-1. For "normal" numbers, this is often 1/n. But inversion also exists for matrices, and is another matrix that meets the following requirements:
- the original matrix multiplied by the inverse matrix must be the identity matrix
- the inverse matrix multiplied by the original matrix must be the identity matrix
Not all matrices have an inverse, and finding it is a bit tricky! There are special rules for 2x2 and 3x3 matrices, but since we're programmers we need a method for all sizes!
One method of finding an inverse matrix is Gauss-Jordan elimination. It's a cool mathematical technique that's not specific to inverting matrices. It works by applying various "row operations" to each row in order to turn it into the identity matrix, but while doing so also applying the same operation to the result. The result in this case, is the identity matrix.
The row operations are relative operations such as multiplying the row, adding/subtracting any multiple of another row, or swapping two rows.
It's easiest to imagine both the work matrix and result matrix to be both put into one big matrix, but nothing is technically keeping you from having them separate which might be more performant.

Creating an input matrix for Absorbing Markov Chains
Let's create a very very basic example, so we can not only learn how to use this to solve a problem, but also try to see exactly what's going on as we do.

As you can see, we have an Absorbing Markov Chain that has 90% chance of going nowhere, and 10% of going to an absorbing state. We also draw the absorbing state as having 100% chance of going to itself but that honestly doesn't matter in any of the formulas I've seen yet.
We talked about convergence before and because it's an infinitely increasing percentage chance to reach a terminal (absorbing) state, we should expect a 100% chance of reaching state 2. I'll also go as specific as to say we should get an estimated number of 10 steps to reach state 2, as 1/0.1 is 10, how many times 0.1 (10%) is repeated before reaching 1 (100%).
To calculate the result of this, we need to write this as a matrix. Each row will be a state, and each column in that row will be the chance of going to the state with the same row number as that column. I recommend specifying the chance as a fraction, especially if you're making something that calculates this, as fractions never lose precision unlike floats.
Like always, it's easier if I show you:

Creating a fundamental matrix
We have a few things we need to do that applies to all operations you might want to do.
First of all, we need to separate non-absorbing and absorbing states in the matrix. Sort all states so that the absorbing states are at the end (or beginning, if you really really want to. But for this article, I'll assume end). This should allow you to split the input matrix into 4 parts (2 for each dimension):

Secondly, we need a "fundamental matrix". This will allow us to get properties from the chain. Each entry in the fundamental matrix will contain the average number of visits to the state with the same index as the column starting from the state with the same index as the row number. In other words, each entry at position (x, y), must contain the average visits to state x starting from state y.
A cool thing about Markov chains is that you can get a matrix where each entry at position (x, y) contains the probability of transitioning from state y to state x in exactly k steps, simply by taking Q^k (yes, that's an exponent, those work on matrices too, Q*Q*Q*Q etc).
So to get the fundamental matrix, we want to sum together the probability of each number of steps ranging from 0 to infinity. Luckily though, it's been proven that you can get the exact same result using the formula N = (I - Q)^-1.
^Image ^stolen ^from ^Wikipedia
So following the equation N = (I - Q)^-1, where N is the fundamental matrix, Q is the sub-matrix we just established, and I is an identity matrix with the same size as Q (will always be square), we can calculate the fundamental matrix.
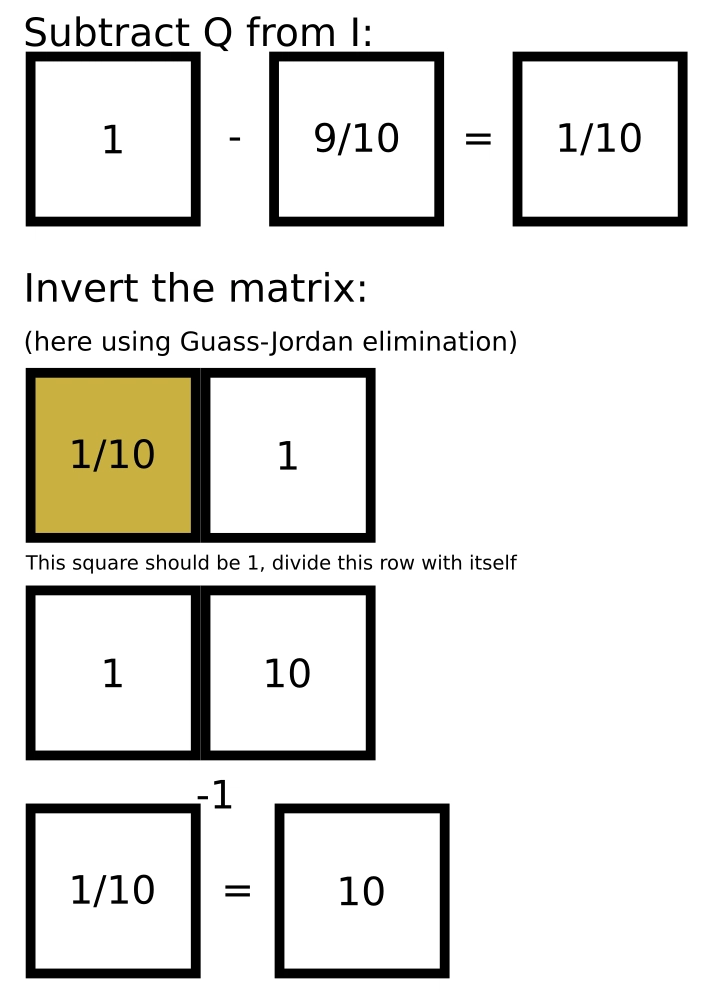
Our fundamental matrix is now [10].
Getting the average number of steps to reach an absorbing state
Since each row in the fundamental matrix has columns that each give the average number of times to visit the state with the same index as column, starting from the state with the row's index, we can get the average number of steps to complete by summing together each row, resulting in the average number of visits in total starting from there.
In math, a trick to sum each row in a NxN matrix is to multiply it by a 1xN (1 column, N rows) matrix where each row is a one.
The formula is t = N1, where t is the matrix of average number of steps from each starting state to an absorbing state, and 1 is the 1xN matrix mentioned.
Obviously, since our example matrix is 1x1, multiplying it is really simple...

And, as you can see, the average number of steps to reach the absorbing state is 10, just as we guessed!
Getting the percentage chance to reach each absorbing state
So, this is probably the step you've been wanting to read. After all, getting a percentage for each state sounds more interesting than the average number of steps it takes to reach any (absorbing) state.
The formula for this is B = NR. Remember R from the sub-matrix we cut earlier? Multiplying the matrix containing the average number of visits to each non-absorbing state with the matrix containing the probabilities to transition into an absorbing state in one step, we get the probabilities of entering an absorbing state after any number of steps.

The final result is a matrix where each column is the chance for the state with that index has to reach the index of that row. In this case non-absorbing state 1 has 1 (100%) chance to reach absorbing state 1 (actually state 2). Seems correct!

^(Example output here is the output of https://en.wikipedia.org/wiki/Absorbing_Markov_chain#String_generation)
Final notes
There's a famous quote:
If you can't explain it simply, you don't understand it well enough.
^(Sadly couldn't find who said it, but it's frequently miss-attributed to Einstein.)
And I admit I certainly don't understand this witchery well enough. But I hope that my article may still have given you a little more insight. Wikipedia and other sources I've found just seem to state the facts, but don't try to explain them for 5 year olds. I might not be able to explain them well either, but the least I can do is try.
I have implemented this here: math-types

Top comments (1)
Thank you for this article, it helped me a lot. I got to level 3 and got the Doomsday Fuel task and had no idea how to approach it, even though I have CS degree and I'm ok with matrices, I never touched Markov chains so this article was very insitful. Thank's a lot.