We have discussed cache consistency before, and at that time we mentioned it is possible to achieve good consistency if we implement read-aside cache correctly. To further improve consistency, a more complex solution must be used, e.g., write through cache or write behind cache.
Today, we are going to discuss another common scenario of caching, Dogpile Effect.
Dogpile Effect means when the system is under heavy volume of traffic, whenever a cache invalidates, either by cleanup or timeout, it will have a huge impact.
For example, if a cache entry is accessed by 100 requests at the same time, once the entry expires, 100 requests will hit the backend system directly, which is a serious challenge for the backend system.
Therefore, let's see what approaches are available to deal with Dogpile Effect. There are three common approaches as follows.
- Warm Up Cache
- Extend Cache Time
- Exclusive Lock
Each of these three options has its own pros and cons, and in fact, they are already widely used.
Question, do you know which one is the
race_condition_ttlof the cache store in Ruby on Rails?
Warm Up Cache
Before we talk about this approach, let's review the read path of the read-aside cache.
- First, all read requests are read from the cache.
- If the cache fails to read.
- Then read from the database, and write back to the cache.
The problem occurs when the cache is missed.
When there are lots of read requests under a high volume system, it will result in lots of database accesses. If we can keep the cache active anyway, can't we solve Dogpile Effect?
Thus, the approach is to replace the cache TTL with a background thread that updates all caches periodically, e.g., if the cache TTL is 5 minutes, then update all caches every 5 minutes, so that cache invalidation is no longer encountered.
But such an approach has its drawbacks.
- It is very space inefficient if applied to all cache entries.
- In some corner cases, caching still invalidates, such as an eviction triggered by cache itself.
Although this is a simple and brutal approach, I have to say it works very well in some situations. If we have a critical cache that has to deal with a lot of traffic and the cost of updating is high, then keeping that cache fresh is the most effective way.
As long as we avoid updating all cache entries, then it won't take up a lot of space and will be less likely to trigger corner cases.
Extend Cache Time
Warm up cache can work well on specific critical cache, but if no critical cache is defined at all, then the benefits of warm up cannot be applied effectively.
Therefore, the second approach is suitable for general purposes.
When reading a cache, if a cache timeout is found, then extend the cache time slightly and start updating the cache. If there is a concurrent read request, the later read request will read the cache with the extended time to avoid accessing the backend database simultaneously.
Assuming that the cache TTL is 5 minutes, we set each cache to have a one-minute extension time, as shown in the Gantt chart below.
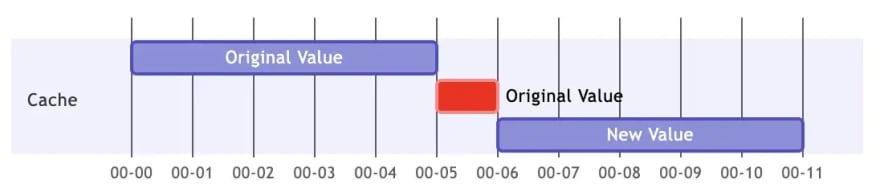
In the time interval 0-5, reading the cache will get the original value. If someone reads during the time interval 5-6, although the cache expires, the cache will be extended, so the original value will still be available. But at the same time, the first person who reads in the interval 5-6 must be responsible for updating the cache, so after the time point 6, the cache will be updated to the new value.
Let's use a sequential diagram to represent the two concurrent request scenarios.

Suppose the cache has already timed out. When A fetches, it finds that the cache has timed out, so it first writes the original value back to the cache and performs the regular read operation to fetch the value from the database, and finally writes the new value back to the cache.
However, B finds that the cache has not expired when it reads, because the cache is extended, so it can get the original value.
With this approach, only one of the N concurrent requests needs to access the backend, and the rest of the N - 1 requests can still fetch the value from the cache.
Actually, Ruby on Rails's race_condition_ttl is this implementation. Lines 855 and 856 in the link above are the operations that extend the cache time.
This approach looks like an effective way to handle high volume traffic, with only one request for access to the backend, right?
The answer is, no, not really.
This is obviously useless when facing a high-concurrency scenario. Let's continue to describe the problem in a sequential diagram.

The same A and B as earlier, but this time A and B occurred very close to each other. As you can see from the sequential diagram, B has already happened when A tries to write the original value back to the cache, so B also feels he is the first one.
When N requests arrive completely at the same time, then such an implementation still cannot solve Dogpile Effect.
Exclusive lock
Extending the cache time seems to have solved most of the problems, but it's still not good enough in a high-concurrency system. Therefore, we need a way to serialize the high-concurrency scenario. Previously, we introduced the concept of the exclusive lock.
https://medium.com/better-programming/redis-as-a-lock-are-you-sure-a870c9f22ad8
In this approach, we are trying to avoid multiple concurrent requests to go through the cache by exclusive lock.
First, an exclusive lock must be acquired before the cache can be updated. Only those who can acquire the lock are eligible to update the cache, i. e. access the database, while the rest of the people who do not acquire the lock must wait for one of the following two conditions.
- whether the cache has been updated
- whether the lock can be acquired
The wait-and-acquire lock must also verify whether the cache has been updated in order to further avoid duplicate database accesses.
Of course, there is an obvious drawback to this approach. Making the concurrent process serializable would significantly reduce concurrency. In addition, the waiting is an extra overhead that not only consumes resources but also affects performance.
It's worth mentioning that we often say Redis is not reliable, so in this scenario, is it necessary to use Redlock to further improve reliability?
It depends.
In general, no, even if Redis is not reliable enough to be used exactly once, the rare occurrence of a leak is not a problem in this scenario. This is not a scenario that requires strong consistency, but at best a few accesses to the database.
Conclusion
In order to address a common problem with caching, Dogpile Effect, we have reviewed three common approaches.
The scenario where the warm up cache is applicable is the "critical cache". Once we can narrow down the scope of the cache, then keeping it fresh is the most intuitive and easy way for us.
Extending the cache time is a general purpose approach that can effectively tackle a variety of high volume scenarios. By providing a time buffer, the cache is allowed to serve for a longer time until the cache is updated by "someone".
Exclusive lock is a high-concurrency specialization approach. In order to avoid concurrent requests from hitting the backend system, concurrent requests are turned into sequential requests through a serializable mechanism.
Each of these three approaches has its own advantages and benefits, but in fact, extend cache time and exclusive lock can be combined into a total solution. I will explain the implementation details of this in code in the next article.
Let's call it a day.

Oldest comments (3)
Nice, post.
During exclusive lock, order of calls also matter. What I mean is, B should make a database call only after update lock is acquired. If not, B will make DB call and find it has no update lock, in that case we are not improving overall load to DB.
Also, what about thundering herd problem? Looking like we might need additional logic on top of exclusive lock to better manage thundering herd problem?
If we are using some atomic operation for handling locking, we should never have to worry about thundering herd. For example, make Redis be a lock, so we therefore can leverage its atomic property.
If we concern about the reliability of Redis, we can adopt Redlock as an alternative.
The images are not visible for many of your posts, including this