Last week we talked about the difference between scalability and elasticity, and the concept of solutions was mentioned at a high level. In this article, let's take a look at some practical solutions.
First, if you haven't read the last article, I suggest you read it first. This time we are solving the elasticity problem rather than scalability. As mentioned before, the two most common solutions to the elasticity problem are caching and messaging.
Therefore, in this article, we will list some common practical solutions and briefly analyze the advantages and disadvantages. Let's get started.
Read-aside Cache
When talking about caching, the most commonly used mechanism is the read-aside cache.
The advantage is that it is very easy to understand and implement, and already provides a good consistency level. I've explained how it works in my previous article, but let's review it again.
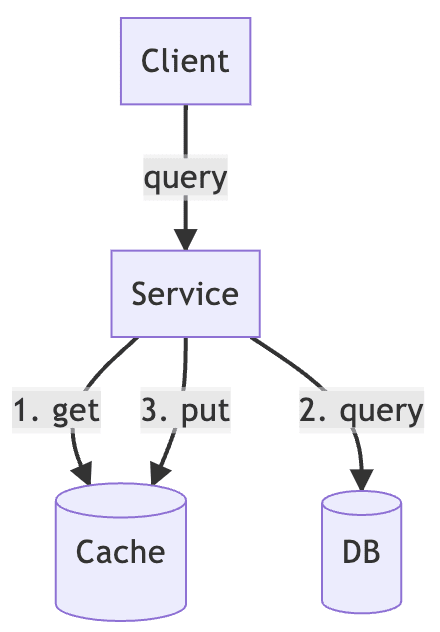
The read mechanism of the read-aside cache is very simple: first try to get the data from the cache, and if you cannot get it, then get it from the database instead, and save it back to the cache. In this way, the next request for the same data can be taken directly from the cache.
How to ensure that the cached data is up-to-date (consistency)?
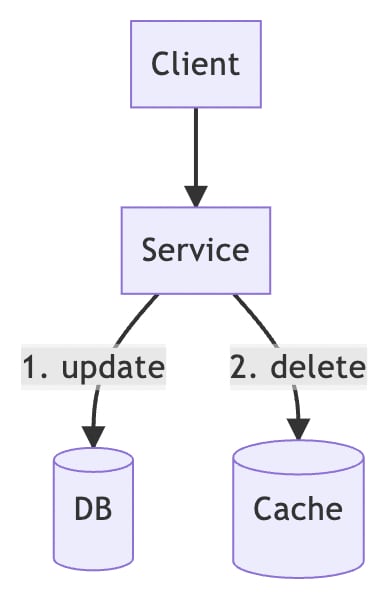
After updating the database, the corresponding records of the cache should be cleared immediately. When the same request comes in next time, it will be taken from the database first and the latest result will be written back to the cache.
It looks like both read and write are perfect, so the read-aside cache should have a high degree of consistency! In fact, not really.
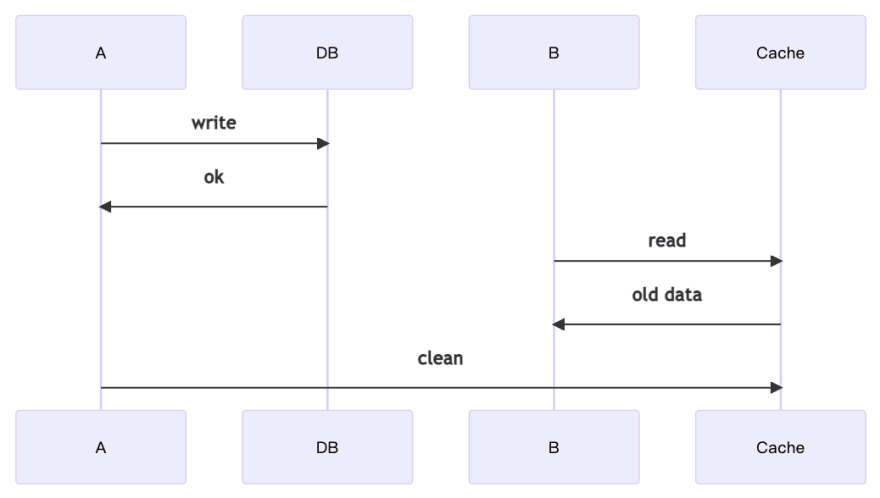
According to the above sequential diagram, we can find that both A and B are behaving correctly, but put together, they make an error, and B gets inconsistent data. This is the first problem.
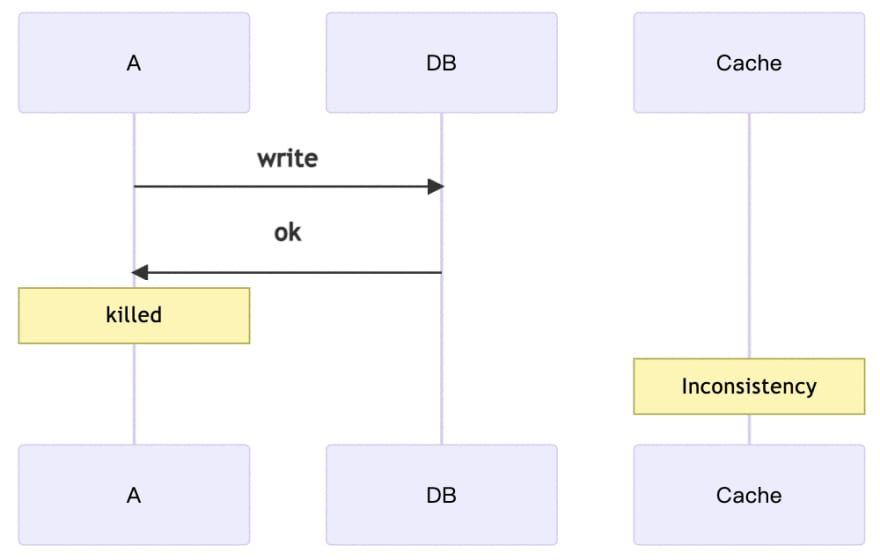
The second type of error is more intuitive, when A wants to update the data, A is killed after finishing the database update, probably due to bugs or application upgrade and so on. Then the data in the cache will remain inconsistent for a long time, until the next update or timeout.
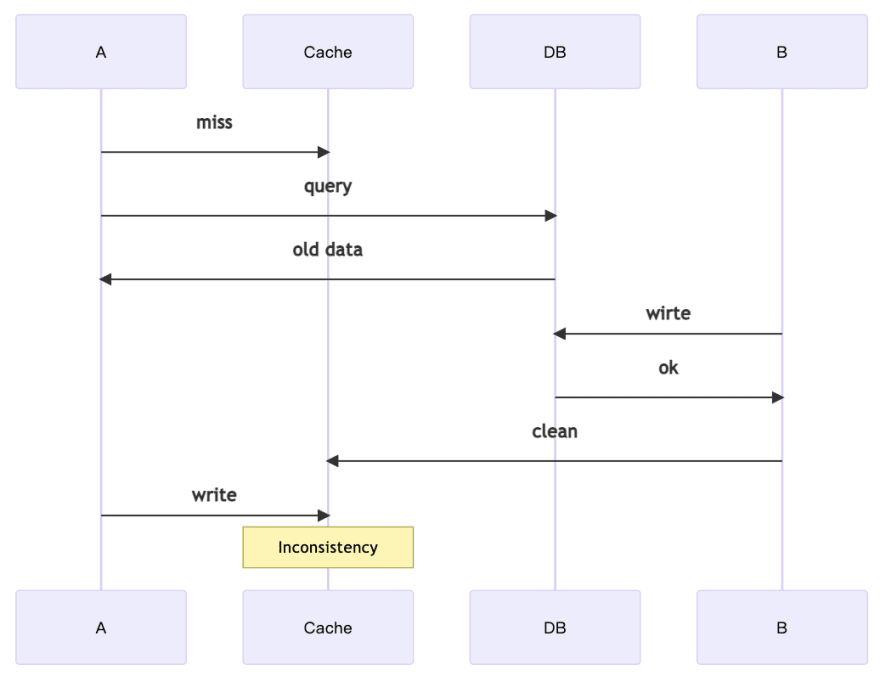
The third error is similar to the first one in that the individual actions of A and B are correct, but put together they are wrong. This inconsistent cache data will also remain for a while until the next update.
These details have been explained in my previous article, if you want to know more can also be used as a reference.
In fact, problems 1 and 3 can be greatly mitigated by modifying the implementation of the application. In the first problem, when A finished writing the data, don't do anything else, then clean up the cache quickly to reduce the possibility of being touched by B.
The same is true for problem 3. When A finishes querying, don't do too much processing and write back the cache as soon as possible, which can also greatly reduce the chance of occurring after B.
However, there are three potential problems with read-aside caching.
- If a cache has a large scope of content, it can be difficult to determine when to clean it and to implement it. On the other hand, when many places have to be cleaned up, it may make the cache less effective.
- Dog pile effect. This refers to when a high-traffic system accesses cache frequently, if it encounters clearing cache or cache expiration, these traffic will still occur on the database. And the database may not be able to hold up.
- No graceful shutdown. Problems 1 and 3 can be improved by modifying the application, but problem 2 is not always possible, especially when the application fails, there is basically nothing to do.
Denormalization
If we have to take data from many places, it is ideal to put it all together and take it only once.
Conventionally, in order to avoid data duplication in RDBMS, we would create individual tables according to the data type, and then join each other through foreign keys.
But this will cause a problem, if it is an aggregated data must be pulled from each table, in the traffic and data volume of the system is not large, this approach is reasonable, and will have good performance. However, in a big data scenario, such performance is tragic.
The performance of JOIN is not good enough for large data, and it is even worse if it is a subquery.
Therefore, the idea of denormalization is to put all the data together and pull all the required data through a single query. Common practices include Facts Tables, etc., but this article does not focus on data modeling, but on system architecture.
However, the problem is that reading from one place is possible, but what about writing to it? The original tables are already in use by clients, so do we need to find all the clients to modify them? No, it's too much work!
There are two ways, synchronization and asynchronization.
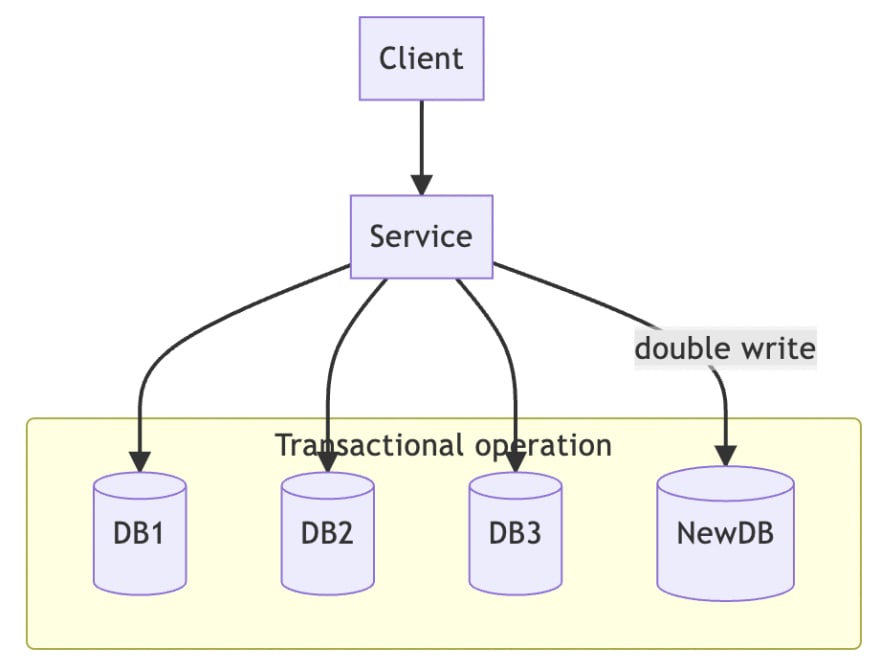
This is an architecture of synchronization. The following DBs can be treated as databases or tables or even caches.
When the service needs to write data, originally only DB1, DB2 and DB3 need to be written, in order to achieve denormalization, but also need to write NewDB in code, and NewDB is the result of aggregation.
If someone needs to aggregate results, they can pull them directly from NewDB. If the owners of these DBs all belong to the same functional team, then this implementation looks acceptable.
On the contrary, if the team that needs to consolidate the results is another functional team, such an architecture will not work. First, the other functional team has to find all the updates, then they have to make changes within the service, and they have to do it transactionally.
For a cross-functional team, such a workflow is unrealistic and impossible. Hence, asynchronous data replication is introduced.
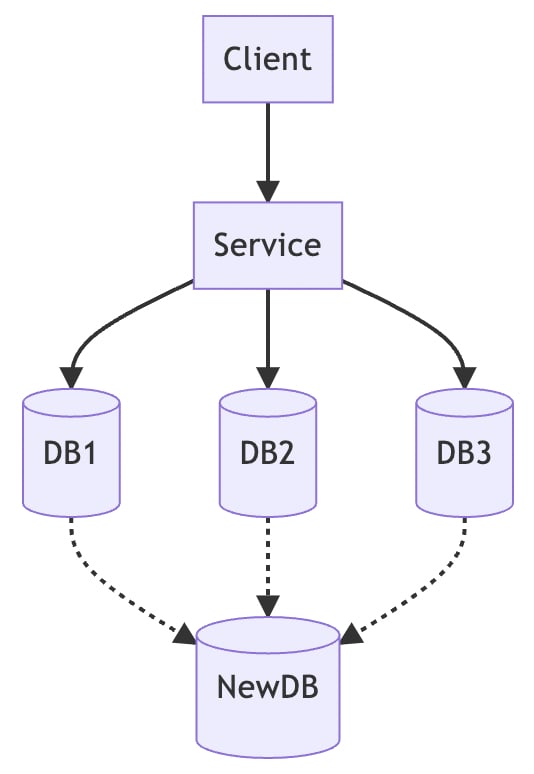
This architecture should be very common in my previous articles, it is in fact CQRS.
Nevertheless, there are various practices to implement CQRS, some of which are listed below. The following is a list of common practices from long to short time intervals.
ETL
DBs -> Batching -> Materialized View
This is the most common practice nowadays, and almost all data engineers do it this way. Data is migrated from one place to another through batch processing, whether it is Hadoop or Spark.
Some transformations and business logic may be added in the process. In order to make the data more accessible, if RDBMS is used as the NewDB, then Materialized View may be added. The data is snapshotted by predefined rules, and if the data is updated, it is refreshed to respond to the calculation of new data.
But data migration is a very costly practice, so ETL does not happen all the time, instead, it happens once an hour or even once a day.
Therefore, the data obtained from NewDB will not be the latest, but a snapshot at a certain point in time.
CDC
In order to keep the data as up-to-date as possible, we know that ETL is not enough. Therefore, CDC is another common practice.
DBs -> Debezium -> Kafka -> Streaming DB
When data is updated, it is captured by Debezium, streamed out to Kafka, and finally written to a streaming database.
The streaming database is made available to external users, so the streaming database must be able to support not only streaming writes, but also rapid query capabilities.
There are many mainstream streaming databases, and Apache Pinot is the most popular one recently.
Because CDC streams are updated in real time, external users can get almost real-time data.
Streaming
Another mechanism for real time streaming comes from the service that originally wrote the data.
Service -> Kafka -> Stream Handler -> RocksDB
When the service finishes updating the original database, it actively sends an event to Kafka and Kafka dispatches it.
In such a system, it is most common to use a streaming framework to do the pre-processing of the streams and store them in the database. Common streaming frameworks include Apache Flink or Apache Samza, and of course the recent Kafka Stream.
For the backend database, we choose a state persistence mechanism that can match the streaming processing framework, and RocksDB is the best choice for several common streaming processing frameworks.
In this way, we can also get the latest data, but from the query point of view, the query capability provided by the streaming processing framework is not comparable to streaming database.
The above three are common data replication methods, and it is worth mentioning that the components of each method can be exchanged or even extended to each other, so that different architectures can be built based on requirements.
However, there are potential problems with asynchronous data replication.
- If there is a wide range of data to be used, it is a big problem to define the data to be replicated. Just as it is difficult to determine the cleanup time for a read-aside cache, it is difficult to define the scope of data replication.
- In addition, whether it is pre-processing through streaming framework or defining query through streaming database, the complexity is obviously high when it comes to complex data structure and complicated computation.
- Among these three methods, ETL has the lowest complexity, but ETL loses data real-time.
Asynchronous requests/responses
We all know the traditional request/response model as follows.
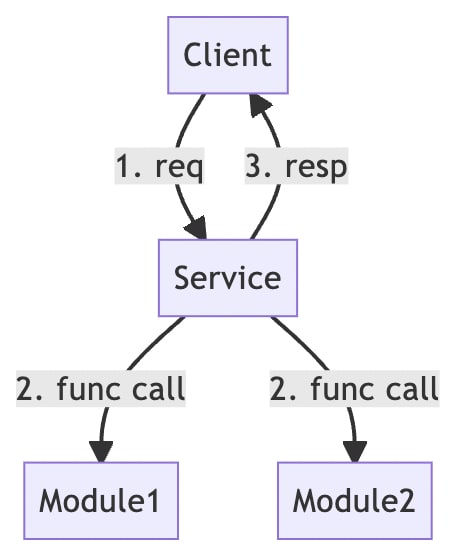
Although this is a function call here, it can also be a remote call across services.
After the client sends a request, the server responds to the request through a series of processing, which is the traditional approach. How can we do this asynchronously?
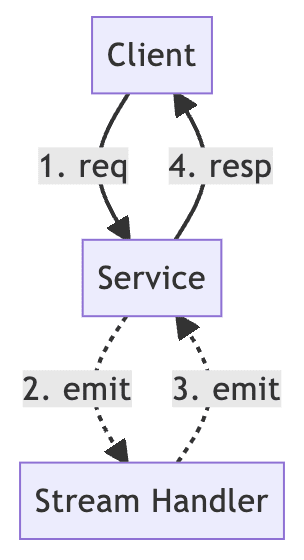
The answer is to make the implementation of the function behind the server asynchronous.
What are the benefits of doing this?
- Handle events by using event handlers, then we can control the number of handlers to determine the pressure on the backend system or database. In the synchronization model, when a large number of client requests come in, the server will fork threads accordingly and put pressure on the backend system. However, when the number of event handlers is controllable, the pressure on the backend system can be controlled as well.
- Request dedup. Since all requests from clients are entered into the message queue, event handlers have the ability to perform deduplication according to specific rules.
- Further, if a streaming framework is used, then the third approach from the previous section can be followed to achieve further denormalization.
However, such an architecture also has drawbacks.
- Such an architecture must be based on the assumption that users will refresh the page a lot in a short period of time in order to be able to play the benefits of dedup. This architecture does not mean that it is only applicable to this context, but if there is no matching context, then the implementation will be too much pain and too little gain.
- Implementation overhead. The server must have the ability to wait for asynchronous messages, which is simple to say, but there are many aspects of the implementation. For example, should we use a temporary queue or a permanent queue? How long should I wait? Questions like these need to be carefully considered.
- Starvation. In order to control the number of concurrent messages, we don't enable handlers unlimitedly, but this also means that some people can't wait for processing and time out.
Conclusion
This article describes some approaches to improve the elasticity of a database.
Unlike the approaches to improve scalability, scalability can be achieved through database-oriented approaches such as query optimization, indexing, and data sharding.
However, improving elasticity cannot be accomplished through databases alone, but must be accompanied by architectural adjustments, so this article lists some common approaches.
In fact, there are many more useful practices than that, and this article is aimed at small to medium-sized organizations. With a limited number of people and a limited budget, it is not possible to make large scale changes, so we can only optimize on the original practices.
Nevertheless, I believe these approaches should provide good insights for further evolution of the system, after all, all methodologies are similar.

Top comments (0)