Last time we talked about the evolution of the data infrastructure, the whole evolution process is as follows.
- Stage 0: None
- Stage 1: Batching
- Stage 2: Streaming
- Stage 3: Integrated
- Stage 4: Automation
- Stage 5: Decentralization
But remember? The evolution from stage 1 to stage 2 was a bit weird in that we just dropped the batch processing we were using and built a new stream processing.
In fact, a product that is already on production environment not make such a drastic change, but would choose an incremental migration process instead.
Therefore, in this article, we will explain in detail how the migration from stage 1 to stage 2 will work in practice.
Stage 1: Batching
Let's review the batch architecture again.

Under this architecture, we have a batch processing role responsible for archiving data from various services to the data warehouse. And batch processing also performs data pre-processing to generate structured data for accelerated analysis purposes.
However, in order to support real-time analytics, we knew from the previous article that we had to introduce a streaming architecture, but at the same time we wanted to leave the original analytics functionality as is.
In other words, it was necessary to add additional real-time analytics capabilities while maintaining the existing architecture and functionality.
So, let's start trying to add streaming architecture.
Stage 1.5: Batching + Streaming
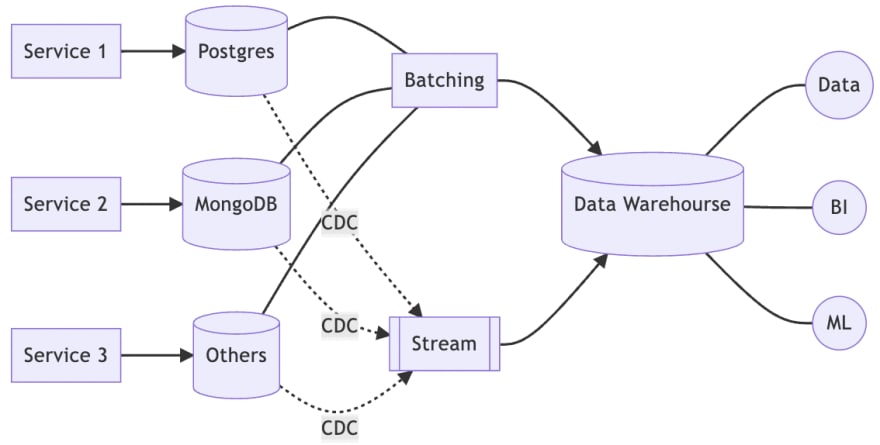
In the previous article, we took an aggressive approach by simply dropping batch processing and replacing it with streaming. This would make the architecture simple, but comes at the cost of a complete rewrite of all the analysis, since the data from streaming is not in the same format as the data from batch processing.
Therefore, we added an extra 1.5 stage to allow batch and streaming to coexist for a while until we could change the analysis framework to use streaming data sources for all subsequent analyses.
The advantage of this is of course that we don't need to do a Big Bang.
As Martin Fowler reportedly said, "the only thing a Big Bang rewrite guarantees is a Big Bang!".
However, the drawback is obvious, when there is any requirement for modification, we have to implement both batch processing and streaming processing, which greatly increases the difficulty of maintenance.
Therefore, although there is a 1.5 stage, it is important to realize that this is only a transition period and should not be considered as a solution.
Stage 2: Streaming
Once we have a transition period, we can evolve more smoothly from batch processing to streaming processing. In the previous stage, we will gradually move all the functionality from batch processing to streaming processing.
At the end, it's just easier to take away the batch processing.

But as I stated in my previous article, batch processing still has its value, so even if it is taken out of the main data pipeline, we will still have batch processing there.
It will just change from being the primary data producer to a secondary one, regularly reorganizing the data in the data warehouse to improve data utilization. Of course, batch processing can also be used to move out-of-date data from the data warehouse to cold storage, further saving storage costs.
Conclusion
The whole evolutionary process should be smooth and gradual.
In order to avoid a Big Bang, it is a difficult choice to move from one architecture to another. Each migration should have as small impact as possible, but at the same time, it should not be too small to make the pain period too long.
Overall, every organization has a different tempo. For an organization with sufficient human resources, this forward movement can be aggressive and fast, or on the contrary, measured.
But in any case, it is important to understand the dilemma and come up with a reasonable enough approach and, more importantly, a complete migration plan.
This planning process is actually as important as the architecture change.

Top comments (1)
The images are not visible for many of your posts, including this