From Monolith to Self-service Platform
All systems start as a small monolith. In the beginning, when resources and manpower are not sufficient, the monolith is the choice we have to make, even the data infrastructure is no exception.
But as requirements increase, there are more and more scenarios that cannot be achieved by the current architecture, and the system must therefore evolve. Each time the system evolves, it is to solve the problems encountered, so it is necessary to understand the different aspects that need to be considered, and to use the most efficient engineering methods to achieve the goal.
In this article, we will still start with a monolith, as we have done before.
But this time, our goal is not to serve a production environment, but to provide the data infrastructure behind all production environments.
A data infrastructure is a "place" where all kinds of data are stored, either structured data or time series data or even raw data. The purpose of this big data (and they are really big) is to provide material for data analysis, business intelligence or machine learning.
In addition to internal uses, there may also be user-facing functions, for example, a list of recommended products on an e-commerce website. The recommendation function is the most commonly used customer scenario for big data, such as recommended products in e-commerce websites and recommended videos in video platforms like Youtube. All of these are the result of analyzing, aggregating, and compiling after storing various user actions.
After knowing today's topic, let's get to work.
Monolithic architecture
Let's begin with a monolithic architecture.
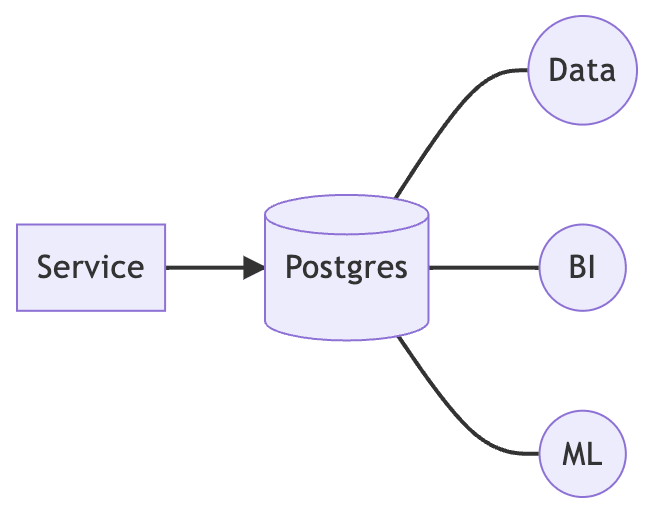
Whatever the service is, a typical monolithic architecture is a service paired with a database. All data analysis, business intelligence and machine learning run directly on this database.
This is the simplest practice, but it is also the beginning of all products.
Why do we show it in monolithic style? Wouldn't it be better to do more?
Well, if the product dies before it is popular, then the monolith will be enough to maintain full features. In order to avoid over-engineering and the investment cost getting exploded, we prefer to start with the easiest proof-of-concept monoliths.
Of course, this architecture is sure to encounter problems. There are three common problems.
- The analysis affects the production performance.
- If the microservices are introduced, running analysis on each microservice's database is suffered.
- It is very difficult to perform cross-service analysis.
Various analyses inevitably take up a lot of database resources, so customers directly feel the poor performance during that time.
In addition, when product requirements increase, we usually adopt microservices for rapid iteration, which means many service and database pairings are created. In order to be able to analyze various product requirements, it is necessary to build an analysis framework on every database.
Moreover, even if each service can be analyzed individually, we cannot easily obtain a global view because the analytics are independent of each other.
Therefore it is necessary to perform the first evolution.
Batch processing
We have two goals, firstly to have independent data storage so it does not directly affect the production environment, and secondly to be able to perform cross-service analysis.
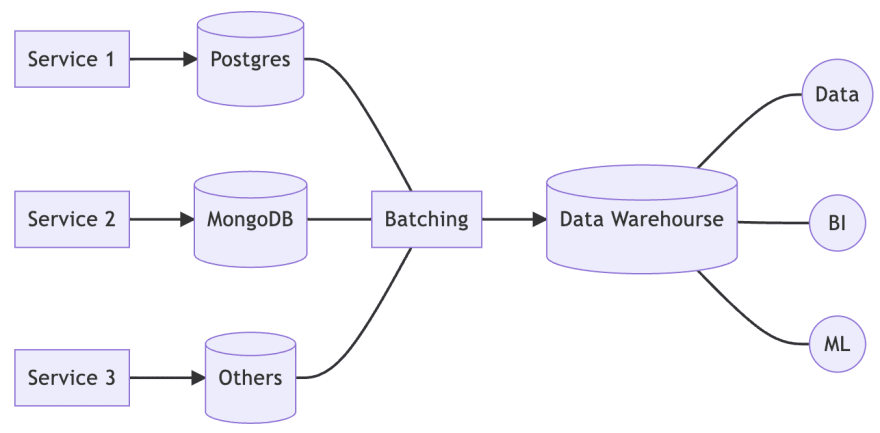
To achieve these goals, we set up a centralized data warehouse so that all data can be stored in one place. All analyses were migrated from the databases of each service to the data warehouse.
We also need a batch processing role to collect data and even pre-process data periodically so that the data warehouse contains not only raw data but also structured data to speed up the analysis.
For batch processing, I recommend using Apache Airflow, which is easy to manage and easy to script for various DAGs to address the needs of multiple batch processing scenarios.
Such an architecture is simple but powerful enough to handle a wide range of analysis and reporting scenarios. Nevertheless, there are two drawbacks that cannot be easily solved.
- lack of real time
- lack of schema
Due to the periodic batch tasks, we can't do real-time analysis. If we run the task once an hour, then the data we see in the data warehouse is a snapshot of the previous hour's data.
In addition, batch tasks require knowledge of the data schema of each service in order to get the data correctly and save it to the corresponding warehouse table. Assuming our data warehouse is GCP BigQuery, the schema in the warehouse table also needs to be created and modified manually.
When the number of services is very large, just knowing the schema can take a lot of time, not to mention managing it.
So, let's do a second evolution.
Stream processing
To solve the real-time problem, the most straightforward idea is to use a streaming architecture.
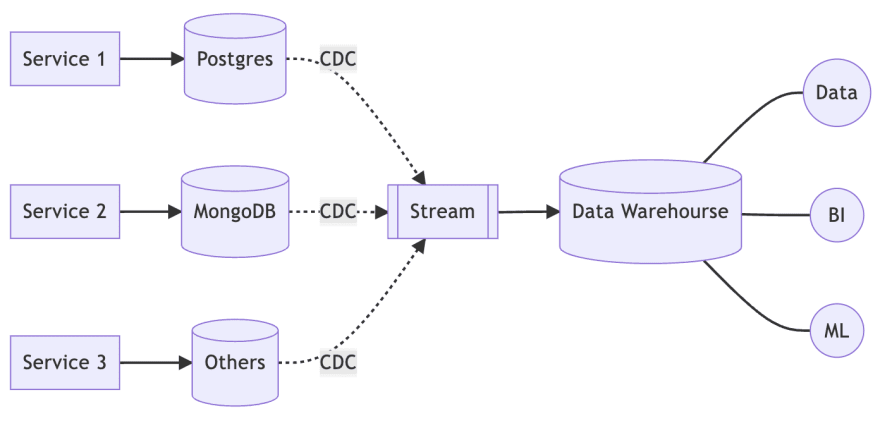
First, all the database changes of the service are captured, then the changes are sent to the stream, and finally the stream is archived to the warehouse.
But is there a way to solve the schema problem? The answer is, yes, through KCBQ.
Let's take a closer look at the internal architecture of streaming.

We use Debezium to capture changes to each database and send the streams to Kafka, and later KCBQ subscribes to the Kafka streams and archives them to BigQuery.
It is worth noting that KCBQ can automatically update the internal schema of BigQuery (setting needs to be enabled).
At this stage, we have a complete data set for analysis, and we have enough data to process for all kinds of data analysis, both real time and batch. However, in the previous stage, we were able to accelerate the analysis by batching pre-processing to generate structured data, and we still want to retain this capability.
In addition, although the data analysis is working properly, we are currently unable to support external customers to access the data. The main reason is the slow response time of data warehouse, which is a big problem when we need to interact with external customers. For example, if a recommendation list takes 5 minutes to be generated, the effectiveness of the recommendation will be close to zero.
Furthermore, when the number of features to be provided to external customers increases, data warehouse can be difficult to handle. For example, search is a common feature, but the search performance of data warehouse is very poor.
Therefore, we have to integrate batch processing and streaming processing so that this data infrastructure can flexibly support various customer-oriented functions.
Integrated architecture
We already have a batch architecture and a streaming architecture, now let's integrate them properly.
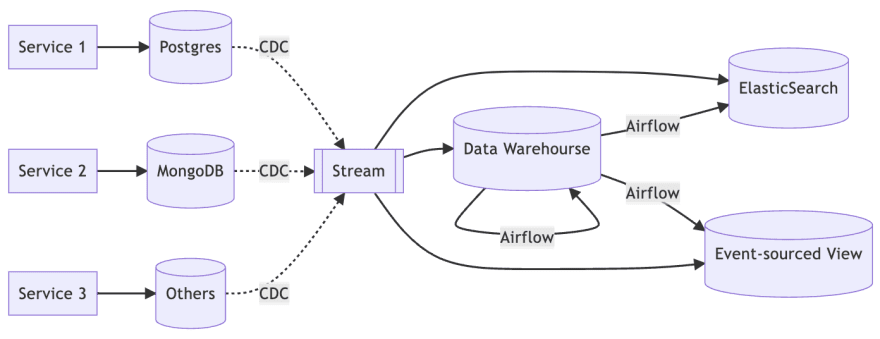
We still archive the changes from each database to the data warehouse through streaming, but we periodically use batch processing to pre-process the raw data for data analysis.
At the same time, the streaming framework not only archives, but also aggregates the streams to generate real-time customer-facing data storage. For example, ElasticSearch is often used in search contexts, while the event-sourced view is used to provide customer-facing functions, e.g., recommendation lists.
But these functions usually also require fact tables, which can be migrated from data warehouses if they are static, otherwise, they need to be implemented through stream enrichment.
So let's further have a look at the internals of streaming architecture.
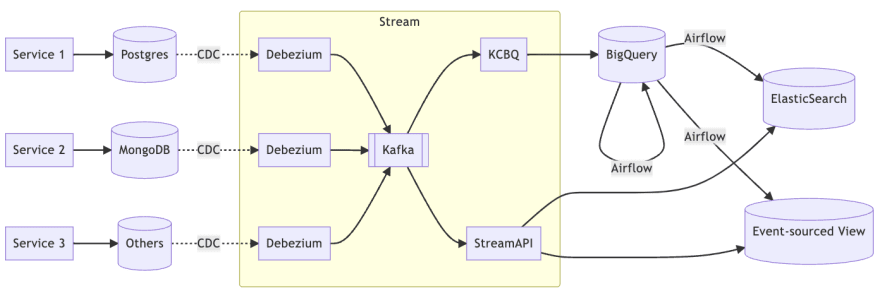
The framework is basically the same as the previous one, but with a new role, StreamAPI.
There is no specific framework specified in StreamAPI, even if using Kafka's native library is fine.
But if using the stream processing framework can save a lot of implementation efforts, such as data partitioning, fault tolerance, state persistence, and so on.
Therefore, I still recommend using a streaming framework such as Apache Flink or Apache Kafka Streams.
At this point, the entire data infrastructure is fully functional. Whether it is for internal data analysis or for external customers, this framework can meet the requirements.
However, this architecture doesn't mean that it's done once and for all.
The next problem is the management problem. So far, the most common task we need to do is not feature development, but the configuration and operation of so many middleware. For each new service, we need to build Debezium, add Kafka topic, configure the streaming framework, and determine the final sink. This process also applies to a new feature request.
In addition, managing the permissions between all data stores is also a problem. When a new person comes into the organization, each participant in the framework has to grant some permissions. Similarly, when a new service or feature is launched, the permissions between services need to be managed.
What's more, when all the data is dumped into the data warehouse, we have to encrypt or mask the PII (personally identifiable information) to be compliant with legal requirements, such as GDPR.
These tasks rely on a lot of manual work or semi-automatic scripts, which undoubtedly add a heavy load to a busy organization.
Automation (Self-service Platform)
Therefore, it is necessary to establish a fully automated mechanism to solve all management issues of the data infrastructure.
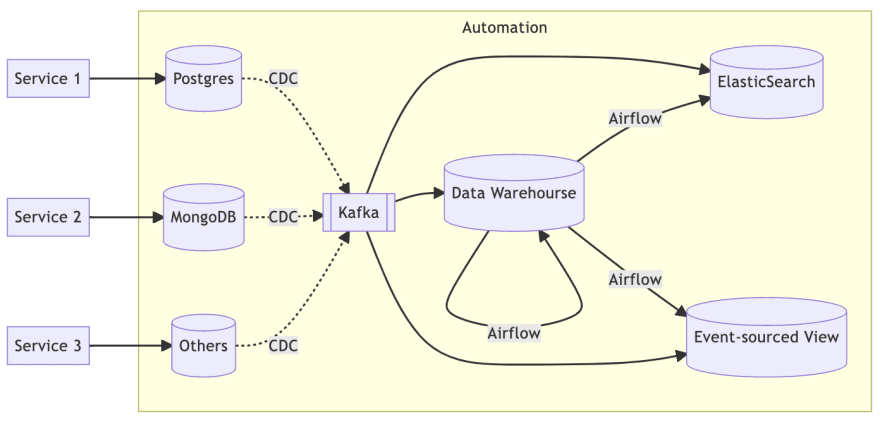
Of course, this automation mechanism should ideally be self-service, and the most successful example I have seen is Netflix's Keystone.
This automation platform involves very deep technical details, not an article can simply explain, so I only provide the features of this platform should have, as for the implementation details will depend on the practice of each organization.
At the infrastructure level, in order to automate the establishment of settings and monitoring, it is necessary to achieve fully automated deployment through IaC (Infrastructure as Code).
In order to address the issue of data ownership, there are three permission-related controls that should also be included in the IaC as follows.
- Identity Access Management, IAM
- Role Based Access Control, RBAC
- Access Control List, ACL
Privacy issues require an easy-to-use interface that can be configured to determine what data must be masked. Data Loss Prevention, aka DLP, is also a very popular data privacy topic nowadays.
As you can see from the above description, there are a lot of implementation details to achieve a fully automated management platform, and there are no shortcuts - implementation, implementation and lots of implementation.
Conclusion
This article is about the evolution of a monolithic architecture into a fully automated and fully functional data platform through continuous problem solving.
However, there are still a lot of detailed technical selections in the evolution process, such as what data storage to use, what batch processing, and what real-time processing are all worthy of attention.
Such an evolution requires a lot of human resources and time, so it is unlikely to be achieved in one step. If and only if we encounter a problem that cannot be solved, we will be forced to move to the next stage.
In fact, even if we achieve an automated platform, the evolution is still not over.
When all kinds of business requirements and all kinds of products and services have to rely on a single data engineer department, then human resources will encounter a bottleneck. How to solve it?
Since we have a fully automated management platform, we can let each product department maintain its own data warehouse and data pipeline. The data engineer becomes the provider of the platform solution, not the owner of the data.
The Data Mesh is born.
However, there are many different approaches to the Data Mesh implementation, and there is no one-size-fit-all architecture pattern.
This is all about the evolution of data infrastructure. If you have any special practices, please feel free to share with me.

Top comments (0)