
An Open Source Approach to Self Hosting a GitOps Platform
Kubernetes is one of the most transformative open source projects in the history of computing. It provides a straightforward framework for running software in containers and provides simple solutions to all of the complexities that arise from microservice architectures: load balancing, autoscaling, high availability, resource pooling, application inventory, configuration, fault tolerance, and observability. It also abstracts your software architecture from your cloud, allowing you to pick up your complex solution and run it in another cloud provider with very little impact to your software ecosystem.
Because Kubernetes is so efficient at managing containerized software, vendors have invested the last half decade adopting a “Cloud Native” architecture, meaning their software can run easily on Kubernetes. This has produced a thriving open source community that is heavily committed to running software in a consistent, predictable, manageable way with engineers that share a uniform vision. According to the CNCF, Kubernetes is now the second largest open source project in the world behind only Linux. The cloud native ecosystem is flourishing and it’s exciting to be a part of.
If you plan to self-host software, of any complexity, in 2022 then you should consider running it on Kubernetes. Managing Kubernetes used to be a challenging undertaking. These days, with cloud-managed Kubernetes distributions like GKE and EKS, cluster management is no longer a heavy burden. Cloud providers can now offload the management of the control plane from the engineers who are responsible for the cluster and the applications in it. This recent evolution, coupled with a cloud native landscape that provides a solution for almost every requirement you could imagine, makes the draw to Kubernetes undeniable.
One of the few challenges that remains for Kubernetes is how to get started. Kubernetes is a complex engine with a sizable learning curve. When you couple that complexity with such an enormous CNCF landscape of cloud native tools, it’s easy to understand why many Kubernetes teams struggle to get their initial platforms established quickly. Adding a cloud native tool to your existing Kubernetes infrastructure couldn’t be easier, but starting from scratch can be a lot to take on.
At Kubefirst, we’ve spent years helping startups get started with Kubernetes, and wanted to share our roadmap on how to get started when adopting Kubernetes for the first time.
Step 1 - Decide on your git provider

Your git provider is the home for your source code, and the starting point for any continuous integration and delivery you’ll have in your future. Typically, this boils down to a choice between GitHub and GitLab. Choosing the right one for your organization depends on what kind of source code you have and who needs to see it. GitHub tends to be the go-to git provider for open source repositories while self-hosted GitLab tends to be the go-to git provider for private source repositories and ultimate control of your Git source code uptime and access.
GitHub is a SaaS offering, meaning they host your public or private repositories in their cloud instead of yours. GitLab also has SaaS, but a lot of their popularity spawns from their open source offering with the ability to self-host your git server and repositories in your own cluster.
These are both great products - one or the other will fit your needs quite nicely.
Step 2 - Automate Your Infrastructure as Code

Infrastructure as Code (IaC) is the foundation of any modern organization’s cloud infrastructure. IaC is a way of describing the cloud resources that you need in simple declarative code. Establishing your infrastructure as code means it will be clearly defined, versioned in git, and repeatable for a good disaster recovery posture.Each public cloud has its own proprietary IaC implementation like AWS CloudFormation or GCP Deployment Manager, but you should avoid these. There are great IaC tools, such as Terraform, Pulumi, and Crossplane that don’t lock you in with a cloud provider. Terraform is currently the industry standard for IaC and supports a lot of technologies. When using Terraform, don’t treat it like a command line tool, treat it more like a managed control plane by automating it with a tool like Atlantis, which gives Terraform the superpower of being fully auditable and integrated with your engineers’ pull request workflows in their git provider.
Other technologies to consider are Pulumi which allows users to code their infrastructure in more popular programming languages, or Crossplane, which allows users to code their infrastructure in YAML. Crossplane is an up-and-coming technology in our view that works especially well with the GitOps discipline.
Step 3 - Choose Your GitOps Driver

GitOps is a discipline that has gotten a lot of attention over the last couple of years and proponents make a compelling argument that it is the right way to manage Kubernetes resources.
GitOps marries your git provider with your Kubernetes engine and serves as an application control plane for your desired state. If set up correctly, a GitOps workflow can provide a complete registry of all Kubernetes resources across your organization in a single git repository.The GitOps approach provides substantial value in securing your clusters, managing your application inventory, scaling your applications across clusters, all while avoiding a bunch of software delivery scripting that would otherwise be needed in your continuous integration layer.
Choosing the right GitOps driver for you is one of your most important architectural decisions when designing your new Kubernetes platform. OpenGitOps offers a set of principles that define the GitOps discipline in a vendor-agnostic way to help guide you through this decision making process. The ultimate goal is to have a single GitOps repository be the exclusive mechanism for how anything gets established across your entire system in an automated fashion.
Step 4 - Commit to a Secrets Manager

On the surface, secrets management seems like it’s something easy to understand and a problem that’s simple to solve. Your application needs a password for a database connection, and as long as you can store that secret someplace secure, good enough right? The problem is that secrets are everywhere and need to be revocable and replaceable. There are application secrets, system secrets, CI secrets, cloud access secrets, leasable secrets, certs, and SSH keys, and they all have their own lifecycles and access requirements. Establishing a secrets manager too late in a project can be a major producer of technical debt, as secrets will scatter through your cloud provider’s secret system, your serverless system, your CI tools, and your engineers’ localhosts in a way that makes credential leaks easy and rotation difficult.If you get your secrets manager in as a priority, your organization can establish a healthy secrets rotation policy up front. Hashicorp Vault is the best in class open source secrets manager and it runs extremely well in Kubernetes.
Step 5 - Set up an Artifact Repository
This step is a detail more likely to fluctuate from shop to shop, in part because you have to define the types of artifacts that your codebase will produce. In a cloud native environment, this will be, at minimum, the container registry. If you're also packaging your Kubernetes applications with helm, you’ll also need a chart repository. If you plan to have language-specific libraries like npm packages for Nodejs, you’ll need a place to store those packages as well.
In the olden days of 2020, DockerHub was the go-to for container storage, but with their recent decisions to rate limit image pulls, many organizations are starting to host their containers either in their own cloud provider’s registry, or in an artifact repository that they host themselves in a tool like Harbor, Artifactory, Nexus, or in git providers GitHub or GitLab which also have certain package artifact repositories built in.
Step 6 - Build Out a Continuous Integration Pipeline
Continuous integration is the cornerstone of DevOps. CI is the spot where application source code ends and its packaging, publishing, testing, and promotion through environments begins.
There are many great CI tools of old and new. In our view, you should look into a few different technologies:Kubernetes-native, git agnostic options:
- Tekton
- Argo Workflows Self-hosted, git provider specific options:
- GitLab Runner
-
GitHub Actions Runner Controller
# Step 7 - Establish Authentication and Authorization
As your project grows, authentication and authorization will require constant refinement and reassessment on a journey towards implementing the principle of least privilege. If you’re starting a new project, it is critical to start with some separation of duties between your team members. Roles should be established in your identity provider, your cloud, and your Kubernetes cluster. These roles should be leveraged by your platform tooling through configuration with your OIDC provider.To manage the assignment of these roles, many organizations will implement a user module in their infrastructure as code. Doing so affords you a consistent, transparent, and secure mechanism for controlling who has access to what. Engineering onboarding and offboarding becomes a matter of a simple Terraform pull request.
# Step 8 - Wire Up Your Cluster to Enable Observability
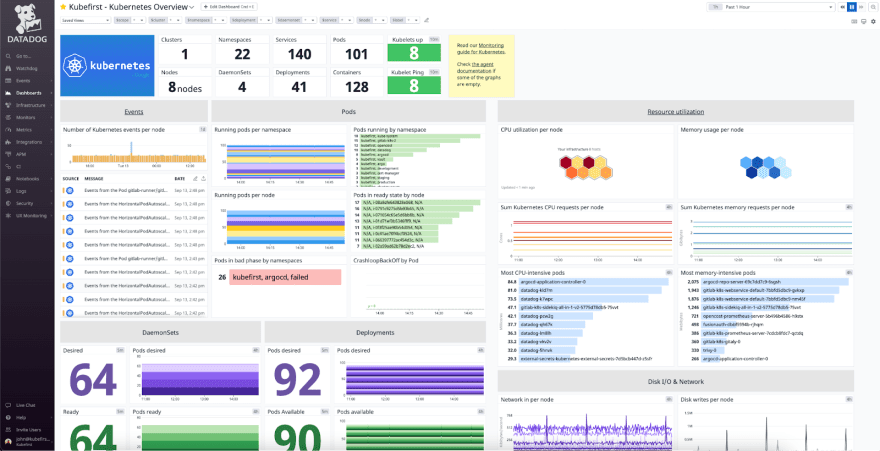 There are many open source options to build an observability platform, but it is tough to do it better or more affordably than a SaaS observability tool like Datadog. If running your observability in Datadog is within your budget, you should strongly consider doing it while you’re discovering and exploring your new cloud native needs. Datadog allows you to install an agent into your cluster that will enable application logging, container resource utilization, tracing, dashboarding, alerting, and an endless sea of evolving features that you just keep getting surprised by. Easy to use - single pane of glass - lets teams get good at Kubernetes fast.
Self hosting highly available observability throughout your infrastructure and applications is a complex undertaking where you're committing engineering hours to keep your observability tuned and monitored with well maintained log indices and good expiration policies. As you get further down the road of your cloud native journey, you’ll discover that there are indeed cloud native tools to solve each of the problems that datadog solves - Prometheus for metrics, Grafana for dashboarding, Jaeger for tracing and application performance monitoring, and many different options for logging. If the cost savings are compelling enough, transitioning to a self-hosted observability ecosystem is a great year two or three goal in your cloud native journey.
# The 1-Step Alternative
There are many open source options to build an observability platform, but it is tough to do it better or more affordably than a SaaS observability tool like Datadog. If running your observability in Datadog is within your budget, you should strongly consider doing it while you’re discovering and exploring your new cloud native needs. Datadog allows you to install an agent into your cluster that will enable application logging, container resource utilization, tracing, dashboarding, alerting, and an endless sea of evolving features that you just keep getting surprised by. Easy to use - single pane of glass - lets teams get good at Kubernetes fast.
Self hosting highly available observability throughout your infrastructure and applications is a complex undertaking where you're committing engineering hours to keep your observability tuned and monitored with well maintained log indices and good expiration policies. As you get further down the road of your cloud native journey, you’ll discover that there are indeed cloud native tools to solve each of the problems that datadog solves - Prometheus for metrics, Grafana for dashboarding, Jaeger for tracing and application performance monitoring, and many different options for logging. If the cost savings are compelling enough, transitioning to a self-hosted observability ecosystem is a great year two or three goal in your cloud native journey.
# The 1-Step Alternative
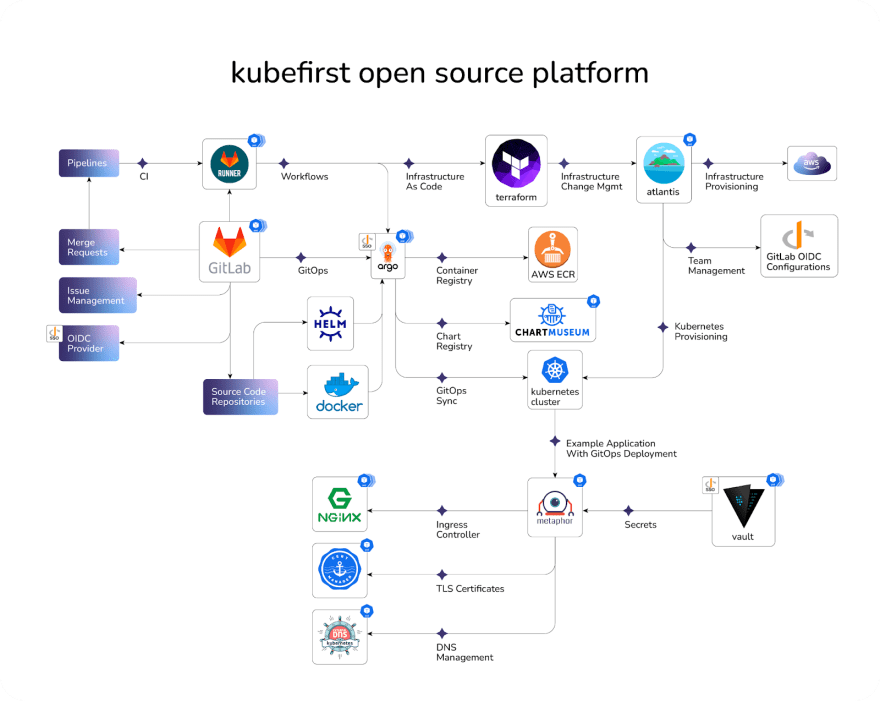 At Kubefirst, we’ve spent years refining the process of provisioning platforms from scratch with the most popular cloud native tools. Now, with our open source
At Kubefirst, we’ve spent years refining the process of provisioning platforms from scratch with the most popular cloud native tools. Now, with our open source kubefirstCLI you can have all these pieces automated, integrated, and self hosted in your cloud in under 25 minutes. You can remove any of our pieces and replace them with yours, or just expand from here and flourish in your new instant cloud native ecosystem. Whether you decide to build the platform yourself or not, these are the technologies that the Kubefirst community has adopted. Our users will be using these same tools this same way. If you think that’s valuable to your organization, we’d love for you to join our community. If you want to keep tabs on our project, throw us a Github star for our open source effort.


Top comments (0)