
This blog’s title suggests that it may have arrived a month early. After all, reflections are mostly written at year-end with predictions and goals for the new year. But to those of us accustomed to compartmentalizing our lives around the festival called “KubeCon”, this doesn’t seem out of place. Also, the choice of six months is thanks to the fact that we have been a CNCF sandbox project for (nearly) this duration. While some of us have been lucky to witness first-hand the ongoings in the project from a vantage point as maintainers, we felt the need for us to share them with the larger litmus community. So, this article is going to be a mix of updates as well as opinions/trends we are observing in the cloud-native chaos engineering space, with generous references to specific docs/blog posts/videos highlighting them.
The Project Has Grown...
...And how! Thanks in no small part to being accepted as a CNCF sandbox project. While we were convinced of the need for a cloud-native chaos engineering solution (which is what motivated us to start Litmus in the first place), the reach and vibrant nature of the CNCF developer & end-user community amplified the interest in the project leading to increased contributions from developers across different organizations (including RedHat, Intuit, ContainerSolutions, Microsoft, etc.,) as well as new adopters (Okteto, WeScale, NetApp). It also paved the way for greater collaboration & integrations with other projects on the CNCF landscape that are focused on solving different kinds of challenges around application delivery (for ex: Okteto, Argo, Keptn, Spinnaker), about which we shall delve a bit more in subsequent sections. More importantly, it has helped generate more dialogue with diverse folks who are at various stages of the cloud-native journey - right from those that have crossed the chasm & have turned into mature/well-oiled adopters of the paradigm to those that are in the process of re-architecting their applications into microservices and migrating them onto their first Kubernetes staging clusters. The Litmus slack channel has never been more active (it saw a 70%+ increase in members), and we are also grateful for all those on-demand zoom calls and pages-worth slack conversations - it would be an understatement to say that more than 90% of the features/enhancements and fixes that went in during this period were direct end-results of this dialogue. Talk about being community-driven!!

Evolution Of (Cloud-Native) Chaos Engineering
While the principles around which we helped define the sub-category of cloud-native chaos engineering (a little over a year ago) continue to hold true (validated by the emergence of other projects sharing similar values), we have noticed some developments in this space since.
These are also things that influenced us as we developed and iterated on the litmus framework, resulting in several new features & integrations.
Prominent amongst those has been the call for “left-shift” of chaos - which is now being increasingly viewed as part of the delivery pipelines as against something run only in production environments, by SRE or Ops persona. This is definitely an interesting departure from traditionally held views about CE. While the “exploratory” model of chaos engineering with controlled failures on prod & well-defined hypotheses in a gameday setting is still the Nirvana of a mature devops practice, we found an urgent need amongst the community for doing it much earlier in an automated way (read CI/CD pipelines) in the wake of overhauls to application architecture (making it microservices oriented) & their impending/ongoing migration to Kubernetes.
Note that this is not to say chaos engineering doesn’t apply to monolithic apps or non-Kubernetes environments, just that the recent shift to a cloud-native mindset has brought about new practices.
Where do you use or intend to use Chaos Engineering in your Kubernetes architecture?#chaosengineering #Kubernetes #cncf #DevOps #k8s
— LitmusChaos (Chaos Engineering for Kubernetes) (@litmuschaos) June 22, 2020
A panel discussion we curated recently to dig more perspective around this topic and other trends in this space was especially enlightening. So have been the conversations with different users (the persona ranging from application developers to people classifying themselves as “devops engineers” focused on delivery tooling, QA architects, SREs, VPs & CTOs). Here is a summarization:
- Reliability verification is needed right from the earliest stages of application/platform development. Something that is being termed as the “Chaos First” principle
Chaos first is a really important principle. It’s too hard to add resilience to a finished project. Needs to be a gate for deployment in the first place. https://t.co/xi98y8JZpJ
— adrian cockcroft (@adrianco) December 3, 2019
Chaos to “test” or unearth issues in the observability frameworks is being increasingly seen as a way to lower the entry-barrier for chaos engineering in many organizations that are generally apprehensive about the idea. Litmus has seen adoption in multiple organizations with this use-case. In some cases, this is the main motivation too (for ex: testing log-based anomaly detection in Zebrium!)
There is a definite need identified to bring in methods to define steady-state of systems & hypothesize about the impact of chaos in a declarative way, without which the advantage of a Kubernetes-native/YAML based approach is nullified. This is a prerequisite for automated SLO validation.
Organic integrations emerge between cloud-native chaos toolsets & observability frameworks, with native support for chaos events, metrics (and other elements). Observability was & continues to be a prerequisite for chaos engineering.
The “run-everywhere” drive in chaos engineering has brought it to the developer’s doorstep and has become a much-used strategy in dev tests. This, combined with the self-service model where developers are provided “namespaces” with “quotas”, has resulted in the need for chaos frameworks to be “multi-tenant” aware, with implications right from RBACs needed for experimentation to the resource consumption at scale.
As a Kubernetes-native Chaos Engineering practitioner, how do you believe experiments should be?
— LitmusChaos (Chaos Engineering for Kubernetes) (@litmuschaos) July 21, 2020
.
.
Thoughts from @kubernauts ?#ChaosEngineering #Kubernetes #OSS #DevOps #SRE #CloudNative #Docker #k8s #k8sjp
The control offered by the chaos-frameworks is extremely important to the SRE. That encompasses the flexibility to choose security configuration, isolate chaos resources, abort/stop chaos when needed, and even simplicity in defining new experiments (Hear Andreas Krivas from Container Solutions talking about it based on prod experience in this user-interview)
Another trend, something that is nascent is the application of chaos engineering to the edge. Kubernetes for the edge is something that has caught on in recent times, and chaos engineering is a natural extension! This calls for newer experiments, multi-arch support & resource-optimized deployments. This adoption story from Michael Fornaro (founder/maintainer of Raspbernetes) is an early indicator! Something that has driven the litmus e2e team to prioritize platforms such as K3s as part of its e2e suite.
While Kubernetes native chaos is something that is appreciated and has caught on, the need to inject failures on infrastructure components falling “outside” the ambit of the Kube API continues to be in demand. And probably is ever-more important. This includes support for node-level and disk-level failures, with growing requests for interoperability with different cloud providers.
Which of these #Kubernetes Cluster would you prefer to use in your local development or CI?
— Udit Gaurav (@udit_gaurav15) September 18, 2020
---@LitmusChaos #kind #microk8s @kubernetesio #Docker
#k3s @Rancher_Labs
Integrations with Other Projects in the CNCF Landscape
With chaos engineering being accepted as an important cog in the application delivery process (Litmus is part of the App-Delivery SIG in CNCF), it was important that we interface with standard cloud-native mechanisms enabling it. Right from dev-test through CI pipelines, automated validation upon continuous deployment into pre-prod environments (CD) and eventually in production. This resulted in the following integrations, which are expected to undergo a formal release process just as the core chaos framework.
Okteto (DevTest): Okteto simplifies the application development experience and reduces the cycles spent in getting a test image validated on the Kubernetes cluster. It reduces this “inner loop of development” by allowing “in-cluster development”, i.e., helps spin-up a complete dev environment on the cluster itself with access to all the code in your workspace. It has a SaaS offering (Okteto Cloud) that provides Kubernetes namespaces with the option to pull in LitmusChaos control plane so that developers can right away gauge the impact of failures and fix them before hitting CI. You can leverage Okteto’s litmus-enabled preconfigured development environments to deploy Litmus along with your application with a single click. On the other hand, Okteto is also being actively used for the development of the chaos experiments themselves!
Gitlab (CI): Running chaos experiments, albeit with “stricter” validations, not unlike failure tests is something that is catching up. Litmus provides chaos templates for Gitlab, an abstraction over the chaos CRDs to extend your regular CI pipelines with new stages to inject various types of faults and validate for a specific application or infra behavior. The usage models here are varied, with some teams opting for quick litmus-based e2e on low-footprint ephemeral clusters such as KIND that can be brought up within the build environment itself, thereby not needing to push test images to a registry v/s more elaborate “retrospective” pipelines running against cloud/hosted K8s clusters after the images are pushed to a test repository. openebs.ci is a great example of the latter.
Argo (Workflows): Argo is an incubating project in CNCF with a suite of sub-projects under its banner (workflows, CD, events, rollouts). Amongst those, the community (notably Intuit) foresaw great value in creating what we are now calling “chaos workflows”, which are essentially argo workflows running one or more experiments, often in combination with tools to generate “real world load”. This enables the creation of complex chaos scenarios (for ex: you could simulate parallel multiple-component failures, chained chaos - i.e., cases where a sequence of certain failures can cause unique issues, etc.,) and imparts greater power to developers and SREs. The chaos workflows are different from vanilla argo workflows in the sense that the status of a workflow is determined by the success of the chaos experiments.
Keptn (CD): Keptn is an open-source cloud-native application life-cycle orchestration tool. An entrant into the CNCF sandbox alongside Litmus, a major use case of Keptn within Kubernetes involves defining a pipeline with one or more stages for deployment, testing, and remediation strategies. It provides a mechanism to implement a Quality Gate for the promotion of applications based on SLO validation. Litmus integrates with Keptn (via a dedicated litmus-service in the Keptn control plane) to inject chaos into any stage of the Keptn pipeline, especially with background load to simulate real-world behavior, thereby lending greater strength to the SLO eval process.
Spinnaker (CD): In recent times, Spinnaker has introduced the plugin model to extend the capabilities of this popular continuous delivery platform, while keeping a lean core. With an increasing number of organizations using spinnaker for the CD needs, we introduced the Litmus plugin that enables the creation of a custom stage for chaos, with the ability to inject different failures on the deployed application and creating opinionated exit checks.
Notable Features We Added
As mentioned earlier, a lot of the new enhancements & features that we added during this period were a result of community requests and roadmap items crafted based on the trends observed. Here is a high-level list of some notable improvements:
The existing experiments were migrated to golang, and (12) newer ones added (including node-level chaos experiments). We also simplified the experiment development process via the litmus-sdk
The ChaosEngine CRD schema has been upgraded significantly to support various properties for the chaos pods, leading to granular control of the experiment (including pod/container-security context, image overrides & secrets, resource requests-limits, pod scheduling via selectors & tolerations, ability to inject custom labels & annotations, etc.,)
Support for chaos on runtimes other than docker (containerd, crio)
Litmus Probes were introduced to enable declarative steady-state definition and construct hypotheses
The Chaos-Scheduler was made available to help with the execution of continuous background chaos.
Support for newer modes of operation (admin, namespaced) to enable centralization of chaos & operations in multi-tenant environments respectively
The CI & e2e practices in the litmus project have improved (though there is much more to be done) over time, with support for multi-arch builds, test runs for pull request validation as well as increased integration test coverage for the litmus control plane and chaos experiments.
Not least, we also introduced the chaos-bird as our new mascot !!
Hola k8s folks, Unveiling the brand new mascot for Litmus, the Chaos Bird in grand fashion @KubeCon_. The all new website (https://t.co/hDS6S1xp9d) and ChaosHub (https://t.co/BA4angVyNu) are all about the Chaos Bird unfurling its magic in the cloud-native world!#chaosengineering pic.twitter.com/B3tVsqzwGR
— Ishan Gupta (@code_igx) August 17, 2020
Introducing the Litmus Portal
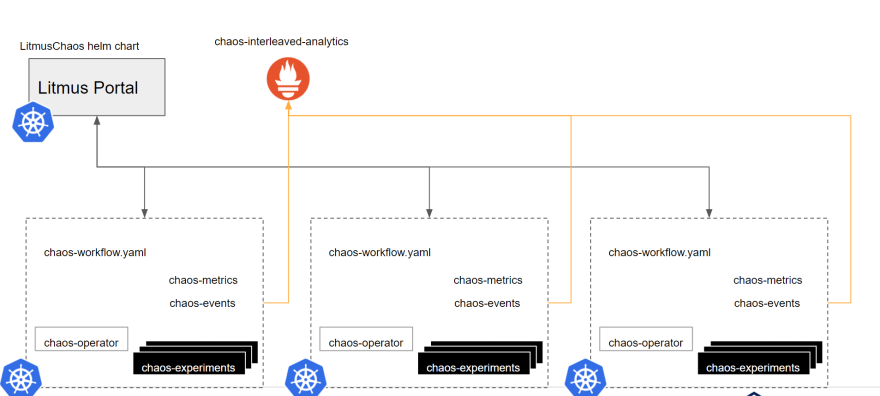
Once we established the fact to ourselves and the community that chaos workflows are the way forward in terms of “scaling” chaos (i.e., increase injections with different “ordering” schemes to form complex scenarios), we decided to simplify this experience for users. After all, constructing YAMLs spanning hundreds of lines by hand is something that is universally detested! Over time, we also learned that “scaling” chaos has other connotations too - such as being able to inject chaos across several “target” clusters from a single “control plane”, extending the chaos execution & analysis to a team or groups of engineers, etc., Not just that, chaos engineering is a lot about visualization, introspection, and analysis of results as against just fault-injection.
All this resulted in the creation of the Litmus Portal which offers a centralized management console to construct, schedule, and visualize chaos workflows on multiple clusters, connected to it via an agent/subscriber. It allows selecting chaos experiments from a trusted/specific git source and offers insights into application/infrastructure resiliency via a “resilience grading” mechanism that allows setting weights to experiment results. It also supports the generation of chaos reports and a git-based auth mechanism to aid chaos execution by teams. The portal is alpha-2 at the time of writing this article and is expected to evolve to include many other features over time.

State of Governance
One of the areas we made significant strides in this period was project governance. While Litmus had become collaborative and “truly” opensource when the maintainer/project leadership group grew to include Sumit Nagal (Intuit), Jayesh Kumar(AWS) & Maria Kotlyarevskaya (Wrike) apart from the team at MayaData, we were looking for ways to decentralize the planning & maintenance activities of the various sub-projects within Litmus. We also realized, that over time, Litmus was being perceived and used in a variety of use-cases - while some folks in the community were focused on integrations with other tools/frameworks, few were interested in improving observability hooks and yet others wanted to focus on improving the chaos orchestration logic to improve the chaos experience. We also gauged interest amongst some members in learning about and contributing to the project by improving the documentation.
This led us to create Special Interest Groups (SIGs) within the Litmus project (something that CNCF & Kubernetes has implemented to great effect) to allow the community members to align themselves with like-minded individuals and improve the project by defining the direction in which the area/sub-projects should go. Each SIG is composed of a group of community members led by at least two SIG-Chairs who also have the commit bits to a set of github repositories that come under the purview of the area/sub-projects. Each SIG has a set of well-defined Goals, Non-Goals & is also responsible for proposing deliverables for the monthly releases. The SIG teams typically meet once in two weeks to discuss progress, roadmap items and to engage in cool demos/presentations. While some SIGs are formally operational (Documentation, Observability, Orchestration, Integrations), a few others are yet to take off (Deployment, Testing, CI). We hope these will soon be functional!
Looking Ahead
We recognize the fact that there is increasing adoption of chaos engineering as a practice across organizations, and sustained improvement is key in ensuring the cloud-native world is able to leverage litmus for their resilience needs successfully. The project roadmap is continuously being upgraded to hold newer requirements and stability improvements. To this effect, we have been planning a steering committee composed of people from the resilience, observability & application delivery world that can help prioritize features, enrich project/product management practices, and generally help bring real-world experience to improve Litmus in becoming a well-rounded solution! If you are interested, do reach out to us on the litmus slack channel.
So, to summarize, we are looking at the community getting involved in a bigger way in driving the project - via feedback and contributions. Needless to say, we are also focused on moving further along the path as a CNCF project which would accelerate achieving these goals. The next Kubecon is 6 months away, but we will keep you all posted on what's new in Litmus.
Before we end this post, it is worth looking at what Liz Rice, the TOC (Technical Oversight Committee) chair at CNCF had to say about chaos engineering!
#CNCF TOC chair @lizrice is sharing the 5 technologies to watch in 2021 according to the TOC:
— CNCF (@CloudNativeFdn) November 20, 2020
1. Chaos engineering
2. @kubernetesio for the edge
3. Service mesh
4. Web assembly and eBPF
5. Developer + operator experience pic.twitter.com/aSRDTB0piN
Are you an SRE, developer, or a Kubernetes enthusiast? Does Chaos Engineering excite you? Join our community on Slack For detailed discussions & regular updates On Chaos Engineering For Kubernetes.
Check out the LitmusChaos GitHub repo and do share your feedback. Submit a pull request if you identify any necessary changes.





Top comments (0)