Left-Shift Of Chaos Engineering
The emergence of the cloud-native paradigm and an ever-increasing adoption of Kubernetes has brought with it the challenges of re-architecting applications: to be distributed, loosely coupled, and containerized (read: microservices). It has also brought in new ways of dealing with “operational” aspects such as deployments and upgrades, storage provisioning (in case of stateful components), maintaining high availability, scaling, recovery, etc., Kubernetes, as the overarching orchestration system provides multiple choices and approaches for implementing these. However, this brings in significant complexity.
Organizations migrating to Kubernetes typically face the need to test different kinds of failure scenarios and learn about their systems and processes deeply, through repeated experimentation - to build confidence before they hit production. This has contributed to a “shift-left” approach in chaos engineering, with increased usage of chaos within CI/CD pipelines.

LitmusChaos Improves Support For CI/CD
The litmus community has seen a significant upsurge in the usage of chaos experiments within pipelines, in some cases even before the build/deployment artifacts are merged into the main source of truth (executed on transient PR environments) and in most cases as part of the continuous deployment process, wherein the build artifacts are pushed to a staging environment wherein they are subject to “sanity chaos”.
While the project did provide some initial (limited) support and presented use cases around this area as part of its 1.x releases viz. Gitlab templates & Github chaos actions, there was still a pending need to support fully featured chaos scenarios which allows all experiment tunables along with hypothesis validation using Litmus probes in CI/CD pipelines. In other words, support for the execution of workflows that can be managed and viewed from the Chaos-Center.
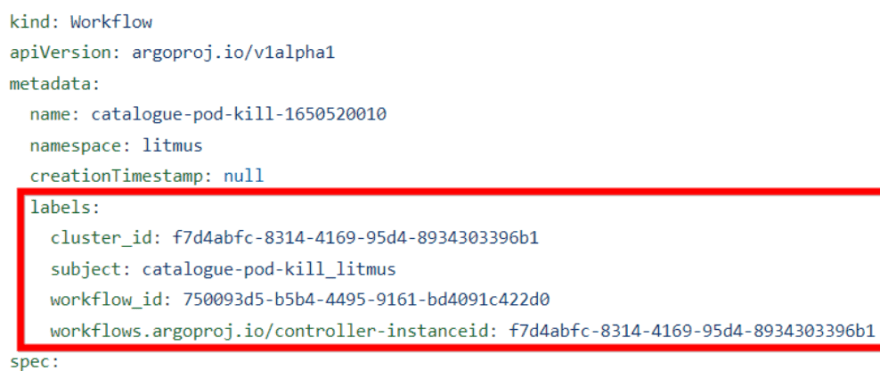
Recent versions of Litmus (v2.8.0+) provides a set of refactored/standardized APIs to trigger workflows from a pipeline, while also allowing the visualization and management of chaos workflows launched with specific metadata (cluster_id & controller-instanceid labels) in the Chaos-Center.
In this post, let's take a quick peek at an example of chaos being executed from a Harness CI/CD pipeline.
Harness CI/CD
Harness Continuous Delivery as a Service platform provides a simple and secure way for engineering and DevOps teams to release applications faster, safer, and more secure. Harness automates the entire CI/CD process, which helps build, test, and deploy improved features more quickly. It uses machine learning to detect the quality of deployments and automatically roll back failed ones, saving time, and reducing customer scripting and manual oversight. It provides enterprise-grade security at every step throughout the CI/CD pipeline.
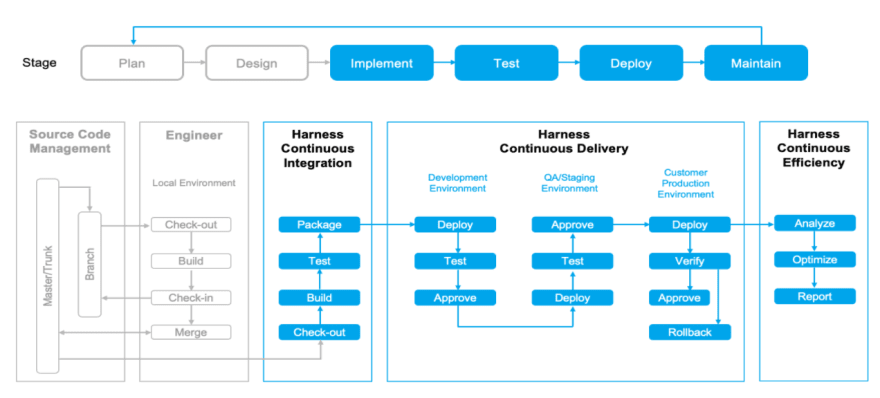
Here is a quick reference to how you can set up a build and deploy pipeline using Harness.
As explained in detail in the aforementioned reference, Harness carries out the build and deploy steps via jobs executed through a Delegate - a service you run in your VPC. It speaks to the Harness manager, the main control plane managing the individual pipeline instances. You could use the Harness SaaS platform or its on-premise installation to implement the pipelines.
Chaos Experiments In Harness Pipelines
Chaos within a Harness pipeline can be added as a dedicated stage post the deployment stage, with the results of the chaos experiment determining the success of your pipeline with an appropriately defined custom failure strategy:
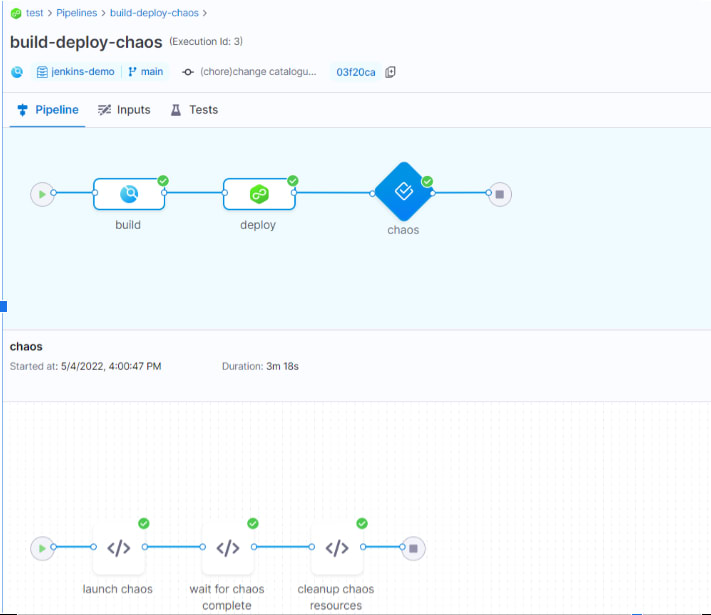

or as a step within the deployment stage itself, with the ability to rollback deployment in case a chaos run against it is not found to provide desired results.
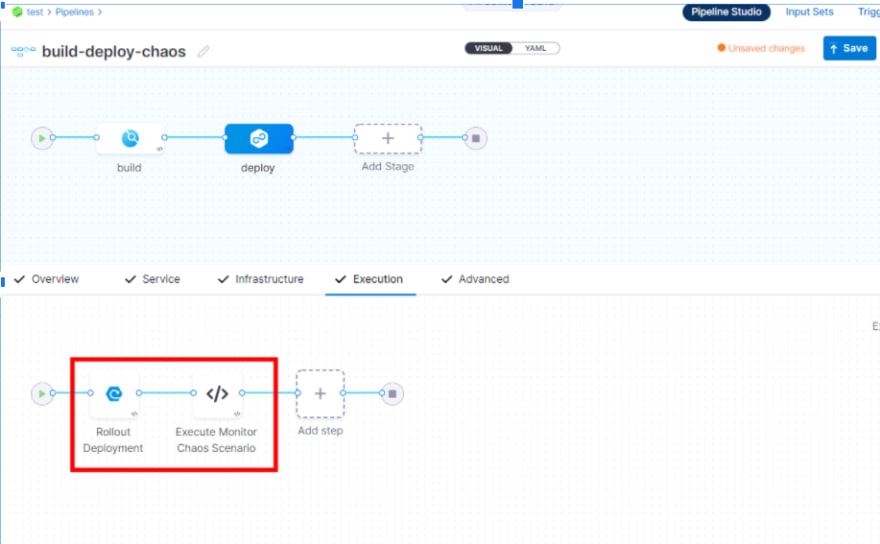

Within the chaos steps defined in the above pipelines, one could invoke the Litmus API to trigger a chaos workflow that is configured with the right fault (experiment) & validation (probes) combinations, apart from desired runtime properties (duration, node selectors, tolerations, resources, etc.,). The prerequisite is to have the authentication tokens extracted prior to the construction of the API invocation in the pipeline.
Such a chaos workflow template can either be hand-crafted and used as a payload within the API call, or, still simpler, be pre-constructed on the Chaos-Center so that it can be re-triggered from the pipeline using the workflow_id reference.
An alternative mechanism is to perform a kubectl apply operation of the workflow manifest downloaded after its creation from the Chaos-Center (this model is intended to support those users who prefer having a golden copy of the chaos scenario definition alongside the deployment artifacts). The status and success of such workflow executions can be tracked via kubectl commands or via litmus API.
Conclusion
While chaos experimentation as part of SRE-driven gamedays will continue to exist as the chaos engineering practice continues to get adopted by more organizations, its consumption is set to increase manifold in the developer community on account of its inclusion in the CI/CD pipelines, what with the culture of developers owning build-to-deploy for their code changes.
Through this post, we have shown an example of how popular CI/CD platforms like Harness are embracing the concept of chaos experimentation and bringing it into the ambit of the pipeline world. You can see the explanation in action in this demo by Neelanjan, provided during the Cloud Native Scale meetup.





Top comments (0)