
Written by Manuel Vogel.
Introduction
This blog post is part of a series on the AWS Well-Architected Framework, what it is, why it makes sense, and how we at kreuzwerker do it. In this entry, we will focus on the Performance Efficiency Pillar.
What it is - A quick recap
Using their architects' and clients' collective knowledge and experience, AWS is continuously working on a Well-Architected Framework, which consists of key concepts, design principles, and best practices for architecting and running workloads in the AWS Cloud. AWS developed a Well-Architected Framework to understand what makes some customers succeed in the cloud while others fail. They also wanted to identify common problems, decisional and architectural patterns, and anti-patterns. In other words, what is Well-Architected and what is not, and to make this knowledge available to all, regardless of whether someone is just considering migrating to the cloud or is already running thousands of workloads there?
The Well-Architected Framework is built on six pillars
- operational excellence 👨🏽💻
- security 🔒
- reliability 💪🏾
- performance efficiency 🚀
- cost optimization 💵
- sustainability 🌳
The AWS Well-Architected Review process provides a consistent approach for customers and partners to evaluate architectures and implement scalable designs. It is based on the previously mentioned six pillars.
It's important to note that the Well-Architected Review is not an audit. It's nothing to be afraid of; there are no penalty points for not getting things right the first time. A Well-Architected Review is a way of working together to improve your architecture. The process leads through several foundational questions and checks. It has been derived from years of experience working with the AWS cloud regarding security, cost efficiency, and performance. Hence, it provides sound advice on improvements. It helps you to build secure, high-performing, resilient, and efficient infrastructures for your applications and workloads.
The hard facts about AWS Well-Architected reviews in 2022 are:
- it consists of 58 questions in total across all pillars
- it takes around 4-6 hours for one workload (without tool support)
- the goal is to remediate 45% of the high-risk findings with a minimum of 20 questions answered.
We describe the process from our perspective in more detail here.
How we do it at kreuzwerker
Why should you do it with us?
As a Well-Architected partner, we do at least 20 well-architected reviews per year and have built overall deep architectural expertise for every pillar and hands-on experience.
How do we perform such a review?
For us, it's an interactive process: we inspect and adapt every time we do it. We request feedback from our clients and do a short internal retrospective. As of now, we perform it as follows:
- We do it in 2 blocks from 09:00-12:00 and 13:00-15:00 with a lunch break. However, we can continually adapt if we are faster, e.g., we shift the gap, and we are also flexible whether doing it remotely or at your office.
- We do it in an interactive, story-telling mode. This means: you talk, we listen, and then dig deeper into specific areas while being able to cover multiple questions.
- Our process is supported by tools (more in the other part of the blog post series 🥳)
We do not just handle the questioning but give guidance to answering them. We can tell you how and why there could be improvements to be made.
Performance Efficiency Pillar
In a nutshell
The Performance Efficiency Pillar is about the efficient use of computing resources to meet requirements and how to maintain efficiency as demand changes and technologies evolve. A data-driven approach should be considered, meaning your choices should be based on data, not on a gut feeling. This approach is fed by data on all aspects of the architecture, from the high-level design (see also the Reliability pillar) to the selection and configuration of resource types. In order to keep up with the latest evolution of the AWS Cloud, regularly review your choices. Monitoring is crucial to ensure awareness of any deviance from expected performance.
After summarizing this pillar from our point of view, let's talk briefly about the design principles which navigate us through each pillar.
Design principles
All pillars have their design principles, and they guide us through them. For the performance efficiency pillar, they are as follows:
- Democratize advanced technologies: Use managed services that AWS provides, which delegate complex tasks to your cloud vendor. So they become services you consume, and you can focus on product development rather than resource provisioning and management.
- Go global in minutes: Quickly deploy your workload in multiple AWS regions worldwide, allowing you to provide lower latency and a better experience for your customers. If you also have your infrastructure defined as code with tools such as AWS CDK, you can quickly build the same infrastructure in another region.
- Use serverless architectures: They eliminate the need for you to run and maintain physical servers for traditional computing activities. It removes the operational burden of managing physical servers and can lower transactional costs because managed services operate at a cloud-scale.
- Experiment more often: Having virtual and automatable resources, you can quickly carry out comparative testing using different types of instances, storage, or configurations. Starting and terminating, for example, an EC2 instance is one click away.
- Consider mechanical sympathy: You need to understand how cloud services are consumed and always use the technology approach that aligns best with your workload goals. For example, consider data access patterns when you select database or storage approaches. For services such as S3, you can later examine the access pattern with the Access Analyzer and then define the correct storage classes and transitions between them.
Improvement process
The architectural improvement process includes understanding what you already have and what you can do to improve the current state of your workload architecture. It selects targets for improvement, tests and adapts them, and quantifies your success. Afterward, you share what you have learned so that it can be replicated elsewhere, and then you repeat the cycle ♻️
1 . Selection of resources
- We recommend using a reference architecture and documenting all the changes in Architecture Decision Records (ADR) to understand the WHYs at a later stage.
- Compute: choose instance types based on usage pattern (and data) and the types of hard disks. Using containers, use serverless or other managed container services depending on the existing knowledge. We will ask: how do you use this compute type, and do you constantly evaluate that they are still right-sized?
- Storage and Database: choose the type based on the need, access patterns, and metrics. How did you come to your choice?
- Network: are you aware of the network features and service?
2 . Review regularly
- It is crucial to stay up-to-date with new resources on AWS to benefit, for example, from cost-saving options.
- We also recommend implementing a process to improve workload performance and evolve it over time.
3 . Monitoring is crucial
- We already talked about KPIs in the Reliability pillar; however, in this pillar, we talk about technical metrics such as response times, throughput, etc.
- Review your monitoring metrics + thresholds regularly and alarm proactively.
4 . Tradeoffs that might have to be taken
- Which ones did you take and why? This might include using edge services, design patterns, caching services or database read-replicas, compression algorithms for Cloudfront, or buffering.
- Do you measure the impact of your improvements?
Conclusion
Based on the pillar principles and improvement process, our conclusion is:
- Most clients miss having decision records of their architecture (ADRs)
- Staying up-to-date with new resources on AWS, with media, such as AWS blogs, is highly encouraged; also, transfer this knowledge into the company and allocate engineering time to test it out.
- We recommend moving to serverless: we analyze your infrastructure and advise you. See our blogs for our opinions and case studies.
- We see that access or usage patterns are not measured. We highly recommend making data-driven decisions and documenting them accordingly.
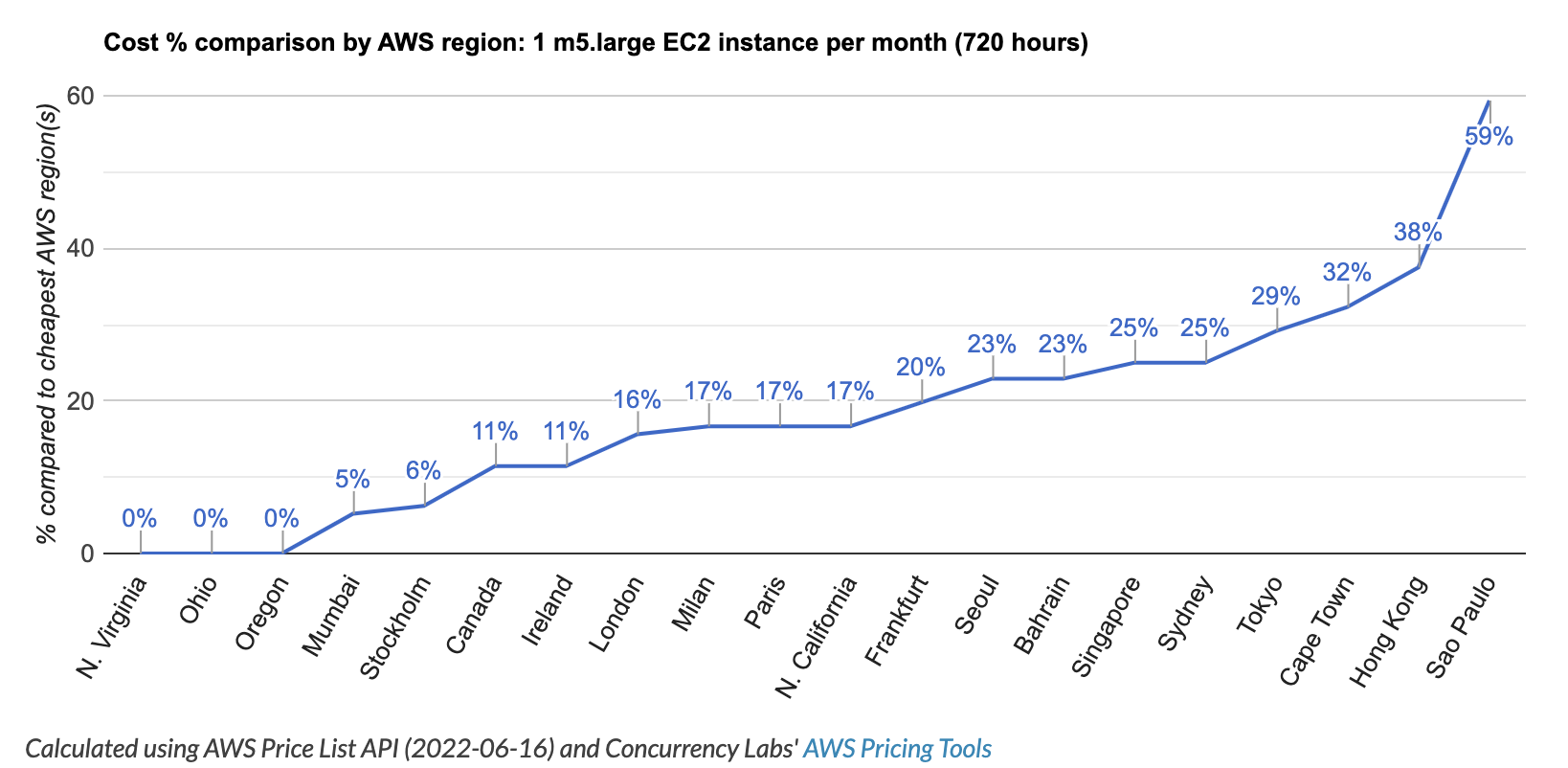
- Going global is recommended. Not only by serving your content quickly and cost-effectively to your user but also for your overall cloud spending. However, it should be chosen wisely, as the following graphic illustrates that, for example, a workload in Frankfurt (+13%) doubles in price compared to Stockholm (+6%).

Top comments (0)