This post is an introduction to Serverless computing - often called Functions-as-a-Service. I will explain, why this is indeed the Hot-Stuff(tm) and introduce you to AWS Lambda. We will build a completely serverless application that exposes 'Hello World' as a Lambda and as a REST service.
Serverless in a Nutshell
Defining Serverless is actually harder than one might think.
The name is rather unfortunate, as defining something by what it is not, seldom works.
I'll try to define the Serverless approach by looking at something, that was missing until now.
Let's talk about containers, yes - Docker. These are hyper-flexible, basically allowing you to do whatever you want. At least as long as it works with CGROUPS. There are no fixed rules or binding principles that you have to follow, only sets of common or so-called best practices. Going into production with containers implies thinking about scaling, provisioning, security, monitoring, deployment and so on. In some projects teams opt to introduce Kubernetes, which in turn can prove very challenging.
The 12 Factor App proves to be a rather useful guideline for cloud native applications. This set of guidelines describes which rules an application should follow to be easily deployed into the cloud. It covers topics like configuration, logging and building among others. This is taken directly form their site:
I. Codebase
One codebase tracked in revision control, many deploys
II. Dependencies
Explicitly declare and isolate dependencies
III. Config
Store config in the environment
IV. Backing services
Treat backing services as attached resources
V. Build, release, run
Strictly separate build and run stages
VI. Processes
Execute the app as one or more stateless processes
VII. Port binding
Export services via port binding
VIII. Concurrency
Scale out via the process model
IX. Disposability
Maximize robustness with fast startup and graceful shutdown
X. Dev/prod parity
Keep development, staging, and production as similar as possible
XI. Logs
Treat logs as event streams
XII. Admin processes
Run admin/management tasks as one-off processes
These are architectural questions you need to answer before you can be successful with you applications in the cloud.
In a sense, Serverless embodies these 12 Factor App principles and offers you a binding corset to plug your business code easily into the cloud. This means you trade flexibility for easy of development.
You basically need to ask yourself: would you rather spend 6 months building infrastructure or building actual applications (I do have to admit, that building infrastructure can be fun, of course).
For the rest of this post, let's assume we want to build applications.
AWS Lambda - 101
There are many platforms for building serverless applications. These range from cloud providers like Azure Functions and Google Cloud Functions to solutions based on Kubernetes like Kubeless and Fission
Here we focus on AWS Lambda, Amazon's offering for Serverless computing.
To give you an impression on what AWS Lambda is and how it works we will simplistic function. This allows us to concentrate on the essential basics of AWS Lambda. A future post, will expand on this and feature a far more complex scenario.
Before we get into the details, we need to look at the definition of a AWS Lambda function.
A Lambda function is any piece of code that gets executed by the AWS Lambda runtime. The code must follow certain guidelines.
- Single purpose: Each function should focus on a single task. For example converting a blog post to speech using AWS Polly.
- Event driven: A function is triggered by an event. That means, that in general you need to think about some outside event that the function should react to. For example, trigger a function if a document is uploaded to S3.
-
Stateless: All functions are executed in ephemeral containers. You cannot rely on any state such as in Node.JS
global. Containers may be reused but in general you must design as if you could not have any persistent state. State in that sense should be moved to a database or similar store. - Asynchronous: Functions support being called in a request/reply mode but also in an asynchronous mode. The function receives an event and processes the event, without any block to the event source.
Execution model and programming model
The execution model is the great strength of the Serverless approach. It is both simple on a conceptual level and powerful on what you can actual achieve with it. Functions are triggered by events.
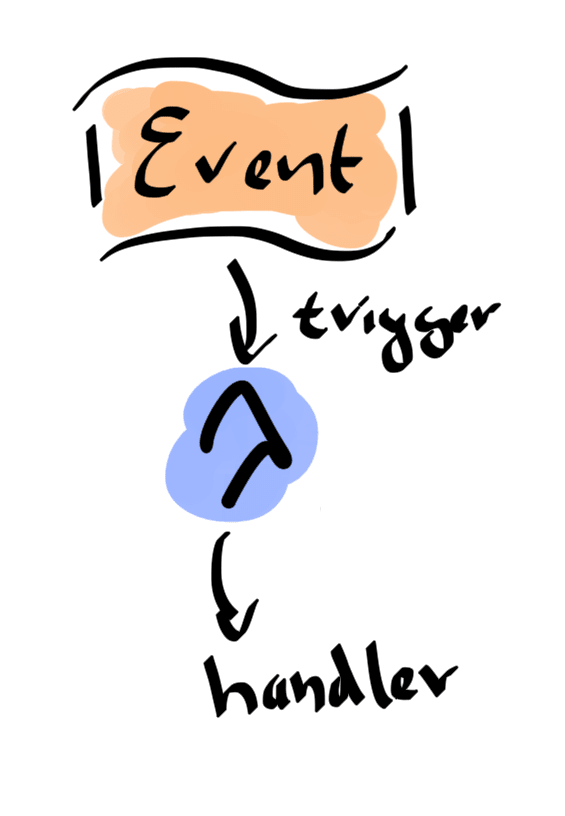
If a function is triggered, a new runtime container is instantiated. The event is passed to the function as an argument. The function can either be executed in a request-reply mode or purely asynchronously.
In the request-reply case the result of executing the function can be returned to the event-source using a callback function. Asynchronously means that no result is returned to the event-source. After the function finished executing, the runtime container is destroyed.
Actually, the last past is not completely true. AWS Lambda reuses runtime containers if possible. But you, as the developer, must never rely on that fact. Code as if the function is executed in a fresh environment each time.
In any case, you'll only be charged for the execution time of the function, currently rounded up to 100ms. If your function is just lying around, you won't be charged anything.
Events can be anything ranging from a direct call by a single page application to an object being uploaded to S3.
Hello Lambda
No demo is complete without 'Hello World', so here is the AWS Lambda version. AWS Lambda supports Python, Node, C# and JVM as its primary runtime of choice and you can add other stacks via some trickery, for example using APEX.
We'll just use Node as the runtime for the example code, just to make things easier.
Create a file called index.js and add the following Javascript code to it:
const Util = require('util')
exports.helloworld = (event, context, callback) => {
console.log('Called with', Util.inspect(event)) // (1)
const greeting = event.name || 'world' // (2)
callback(null, 'Hello ' + greeting) // (3)
}
This is a AWS Lambda function that just receives an event and logs that event to the console (1). If the event contains a field name, then we'll welcome that name otherwise a default world. Finally, we return the result by calling the callback function (3). Since we left null as the first argument, we indicate that no error occurred.
Deploying this function to AWS Lambda is easy. We Zip the source code and create a function using the command line...but before we can actually do this, we need to talk about security.
Secure Lambdas with IAM
Everything you try to do on AWS involves AWS Identity and Access Management (IAM). It is the Amazon way of restricting access to resources and handling privileges for executing operations on resources. This is not intended to be an introduction to IAM, so we keep things simple. The security involves roles and policies. A role is just some kind of identity with a permission policy. The policy in turn determines what is allowed and what is forbidden.
Our function needs a role with a policy that allows the function to at least write log files to Cloudwatch. Cloudwatch is Amazon's monitoring service for everything running on their platform. If we omit this, our function would not be able to write logs, and we would not be able to see any output.
Thus, create a role. First the policy:
$ cat trust-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com" // (1)
},
"Action": "sts:AssumeRole" // (2)
}
]
}
This simple policy allows all Lambdas (1) to assume the role (2). We can create the actual role now.
$ aws iam create-role --role-name basic-lambda-logging --assume-role-policy-document file://trust-policy.json
{
"Role": {
"Path": "/",
"RoleName": "basic-lambda-logging",
"RoleId": "AROAJ6G5L24C7UHHS6UHK",
"Arn": "arn:aws:iam::604370441254:role/basic-lambda-logging", // (1)
"CreateDate": "2017-11-16T10:19:30.905Z",
"AssumeRolePolicyDocument": { // (2)
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
}
}
Two things are of notice. First of all, the name of the role is basic-lambda-logging (1). Second of all, the attached trust-policy is stored as part of the role (2).
Instead of creating a policy ourselves, we'll use a pre-created (managed) policy, that fits perfectly: AWSLambdaBasicExecutionRole. This needs to be attached to the role, and then we are ready to role (sorry).
$ aws iam attach-role-policy --role-name basic-lambda-logging --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
$ aws iam get-role --role-name basic-lambda-logging
{
"Role": {
"Path": "/",
"RoleName": "basic-lambda-logging",
"RoleId": "AROAJ6G5L24C7UHHS6UHK",
"Arn": "arn:aws:iam::604370441254:role/basic-lambda-logging",
"CreateDate": "2017-11-16T10:19:30Z",
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
}
}
When developing Lambda functions it is always a Good Thing to start with the very least permissions needed to execute the function. Only add further policies if absolutely needed!
Creating the Lambda
Now create the Lambda by zipping the source code and creating the actual function.
$ zip index.zip index.js
$ aws lambda create-function
--function-name HelloWorld \
--runtime nodejs6.10
--role arn:aws:iam::604370441254:role/basic-lambda-logging
--handler index.helloworld
--zip-file fileb://index.zip
{
"FunctionName": "HelloWorld",
"FunctionArn": "arn:aws:lambda:eu-central-1:604370441254:function:HelloWorld",
"Runtime": "nodejs6.10",
"Role": "arn:aws:iam::604370441254:role/basic-lambda-logging",
"Handler": "index.helloworld",
"CodeSize": 320,
"Description": "",
"Timeout": 3,
"MemorySize": 128,
"LastModified": "2017-11-16T10:30:07.395+0000",
"CodeSha256": "nnU1bMJZOHRD1HSn8rYzaR0qNBGwoPJfA+f5No1o+N0=",
"Version": "$LATEST",
"TracingConfig": {
"Mode": "PassThrough"
}
}
I'll explain this command option by option.
-
--function-name HelloWorld: this sets the function name, obviously. -
--runtime nodejs6.10: sets the runtime to Node.JS in version 6.10. You can check the available runtimes online. -
--role arn:aws:iam::604370441254:role/basic-lambda-logging-permissions: The AWS id of the role, that this lambda function should use. -
--handler index.helloworld: Tells AWS Lambda that the functions entry point is the exported methodhelloworldin fileindex.js. So you could export multiple functions, and configure multiple Lambdas with different handlers. -
--zip-file fileb://index.zip: This defines the location of the code to be uploaded. Can be a S3 resource or like in this case a local file. Note thatfilebis not a typo, but tells AWS that this is binary data.
Invoking this function is rather easy.
$ aws lambda invoke --function-name HelloWorld out.txt
{
"StatusCode": 200
}
$ cat out.txt
"Hello world"
Note that the invoke command just returns a status code indicating a successful invocation. The actual output is stored in the file out.txt, whose name we passed when invoking the function.
You can also pass an event to the function. An event is just a JSON structure, in our case:
$ cat helloevent.json
{
"name": "David"
}
Depending on the event source, the event can be rather complex in nature.
Now invoke the function and pass the event as a payload:
$ aws lambda invoke --function-name HelloWorld --payload file://helloevent.json out.txt
{
"StatusCode": 200
}
$ cat out.txt
"Hello David"
Things get clearer, if we examine the log output of our function. I'll use AWSLogs for fetching the log output and I'll trim the output a little, so we can focus on the essential parts.
$ awslogs get /aws/lambda/HelloWorld
HelloWorld ... START RequestId: 347078b1-... Version: $LATEST
HelloWorld ... Called with { name: 'David' }
HelloWorld ... END RequestId: 347078b1-...
HelloWorld ... REPORT RequestId: 347078b1-... Duration: 47.58 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 19 MB
You can see the incoming request with the id RequestId: 347078b1-.... AWS Lambda creates a new container for our function, starts it and then invokes the function, as you can see by the logged output Called with { name: 'David' }. The function finishes (END RequestId: 347078b1-...), the container is destroyed and AWS Lambda logs the function invocation's statistics
REPORT RequestId: 347078b1-... Duration: 47.58 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 19 MB
This is the essential output. You can see the invocation duration (47.58 ms) and how much Amazon charges you for the execution 100 ms. As I mentioned you only pay what you use. Finally, Amazon reports the memory consumption (Memory Size: 128 MB Max Memory Used: 19 MB), which we'll explain below when talking about scale.
Updating the function
Let's say, we wanted to change the greeting from Hello to Bonjour. Updating the function only involves modifying the Javascript and then uploading an updated Zip file:
$ aws lambda update-function-code --function-name HelloWorld --zip-file fileb://index.zip
{
"FunctionName": "HelloWorld",
"FunctionArn": "arn:aws:lambda:eu-central-1:604370441254:function:HelloWorld",
"Runtime": "nodejs6.10",
"Role": "arn:aws:iam::604370441254:role/basic-lambda-logging",
"Handler": "index.helloworld",
"CodeSize": 321,
"Description": "",
"Timeout": 3,
"MemorySize": 128,
"LastModified": "2017-11-16T10:54:56.244+0000",
"CodeSha256": "qRDc0Z/bLZ9fhcqZEePdRe7LQiTKmk88u7fppDWhDuU=",
"Version": "$LATEST",
"TracingConfig": {
"Mode": "PassThrough"
}
}
We can invoke the new version directly after uploading.
$ aws lambda invoke --function-name HelloWorld --payload file://helloevent.json out.txt
{
"StatusCode": 200
}
$ cat out.txt
"Bonjour David"
As you can see, the output has changed to Bonjour.
About scale
AWS Lambda takes care of scaling you functions. That means, you do not worry if 1 user accesses your functions or 100. AWS Lambda will just create enough instances of your function, as needed. And it will destroy all instances that are not needed any longer.
That said, you as a developer must size the runtime appropriately. That means, you have to configure the available RAM and CPUs you want for each instance of you Lambda function. Let's look at an example. You remember the log output from above:
REPORT RequestId: 347078b1-... Duration: 47.58 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 19 MB
The essential part is Memory Size: 128 MB Max Memory Used: 19 MB. When creating a Lambda function, you can configure the maximum available memory for the underlying runtime, in this case the default 128 MB. The more memory you allow for your runtime, the more CPUs are assigned to the function when executing.
Imagine the possibilities. We could deploy the same function code twice, creating two different Lambdas: standard and premium. Whereas standard uses the default 128 MB RAM and corresponding CPU, we assign 512 MB to premium along with the additional CPUs. This allows for an easy way to configure a certain quality-of-service.
'REST' with Lambdas
Although you can invoke an AWS Lambda function using the commandline like above and via the AWS SDK (which I do not cover here), sometimes it makes sense to expose a function via 'REST'. Why do I write 'REST' and not REST? Well, REST is an architectural style, far more complex than what I am going to do here. In this example, I'll expose the function using HTTP/JSON, which can be used to build REST-systems using Lambdas. (Splitting hairs, I know).
Back to the topic.
The Amazon API Gateway is used to easily expose functions via HTTP. Consider the following diagram.
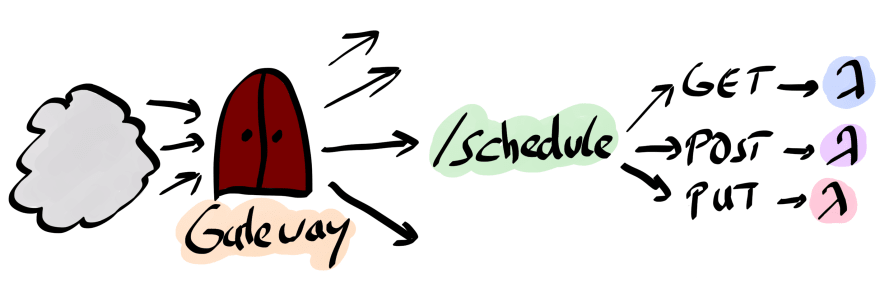
The API Gateway maps requests to resources (in the diagram /schedule) based on the request-method (again in the diagram GET, PUT, POST) to the invocation of a Lambda function. You can either map the interaction explicitly, or use a shorthand notation called proxy integration. We'll use the latter approach.
Creating an API Gateway is rather cumbersome and involves quite a bit commandline magic. We need take the following steps:
- Create a policy and role that allows the API Gateway to invoke our function
- Create the API
- Create a proxy resource below the root resource that gets dispatched to our Lambda function
- Map the method that integrates a call to the method to a Lambda function
- Deploy the API
Creating the policy and role is similar to above, I expect ACCOUNT_ID to hold your AWS account id. The referenced policy and trust files can be found on Github.
$ aws iam create-role \
--role-name hello-world-api-gateway-role \
--assume-role-policy-document file://gw_trustpolicy.json
$ aws iam create-policy
--policy-name hello-world-invoke-lambda-policy \
--policy-document file://gw_invokelambda_policy.json
$ aws iam attach-role-policy
--role-name hello-world-api-gateway-role \
--policy-arn arn:aws:iam::${ACCOUNT_ID}:policy/hello-world-invoke-lambda-policy
I'll just dump the script that executes the steps above. API_GW_ROLE_ARN should contain the AWS id of the role you created above. If you forgot the ARN, just query it again using:
$ aws iam get-role --role-name hello-world-api-gateway-role | jq -r '.Role.Arn'
arn:aws:iam::604370441254:role/hello-world-api-gateway-role
Create the rest api gateway and store the id:
REST_API_ID=$(aws apigateway create-rest-api --name 'Hello World Api' | jq -r '.id' )
Fetch the id of the root resource ('/'):
ROOT_RESOURCE_ID=$(aws apigateway get-resources --rest-api-id $REST_API_ID | jq -r '.items[0].id')
Create a proxy resource below the root-resource:
RESOURCE_ID=$(aws apigateway create-resource --rest-api-id $REST_API_ID --parent-id $ROOT_RESOURCE_ID --path-part '{hello+}' | jq -r '.id')
Create a HTTP-method mapping - in this case for all HTTP-methods (ANY):
aws apigateway put-method --rest-api-id $REST_API_ID \
--resource-id $RESOURCE_ID \
--http-method ANY \
--authorization-type NONE
Remember the invoke uri for calling the hello world lambda function:
LAMBDA_URI=arn:aws:apigateway:${AWS_DEFAULT_REGION}:lambda:path/2015-03-31/functions/arn:aws:lambda:${AWS_DEFAULT_REGION}:${ACCOUNT_ID}:function:HelloWorld/invocations
Setup the integration between the resource and the lambda using a proxy approach:
aws apigateway put-integration --rest-api-id $REST_API_ID \
--resource-id $RESOURCE_ID \
--http-method ANY \
--type AWS_PROXY \
--integration-http-method POST \
--uri $LAMBDA_URI \
--credentials arn:aws:iam::${ACCOUNT_ID}:role/hello-world-api-gateway-role
Deploy the api to the test stage:
aws apigateway create-deployment --rest-api-id $REST_API_ID --stage-name test
The API is now accessible to https://${REST_API_ID}.execute-api.${AWS_DEFAULT_REGION}.amazonaws.com/test/hello. If you try to call this URL now, you will get an internal server error.
$ http https://${REST_API_ID}.execute-api.${AWS_DEFAULT_REGION}.amazonaws.com/test/hello
HTTP/1.1 502 Bad Gateway
Connection: keep-alive
Content-Length: 36
Content-Type: application/json
Date: Thu, 16 Nov 2017 16:23:58 GMT
Via: 1.1 7a9704009fed6d69f12d66623336dfc3.cloudfront.net (CloudFront)
X-Amz-Cf-Id: ayOk1c7HpUQdCY3638spelps8l4GqQgreyBYbfVz0hSeAsagD3hgXg==
X-Cache: Error from cloudfront
x-amzn-RequestId: 8c01416b-caea-11e7-a641-ad0271e6c3cd
{
"message": "Internal server error"
}
The AWS API Gateway proxy integration requires us to change the actual function code. The returned payload must follow a specific format:
{
headers: {},
body: ""
}
In our case this means we need to change the function callback code to:
callback(null, { body: 'Hello ' + greeting })
And of course we need to upload the new function code. Finally, we are able to call the Lambda function using plain old HTTP.
$ http https://${REST_API_ID}.execute-api.${AWS_DEFAULT_REGION}.amazonaws.com/test/hello
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 13
Content-Type: application/json
Date: Thu, 16 Nov 2017 16:27:51 GMT
Via: 1.1 5f27ca52729763588bba68f65c5cb11d.cloudfront.net (CloudFront)
X-Amz-Cf-Id: zykuAcpvxZZ2vIxXAe2vbYk6birjixcTvnJAQ8LMyLPRMWa0K6ENEQ==
X-Amzn-Trace-Id: sampled=0;root=1-5a0dbc87-4198d3de68dd058a32367dee
X-Cache: Miss from cloudfront
x-amzn-RequestId: 171b4e2a-caeb-11e7-b863-3d72645e1f57
Bonjour world
Obviously, the API Gateway is a beast. In a follow up to this post, I'll introduce Claudia.JS, which makes things far easier.
12 Factor Lambdas
Going back to the 12 Factor App principles, let's take a look at how Serverless computing matches these principles.
Codebase
This not directly related to AWS Lambda, of course you can use Amazon's offering. You can deploy the same function multiple times and version your deployments easily.
Dependencies
Lambda functions are self-contained. If your Node application has module requirements, then you need to add them to the code-archive, i.e. Zip everything. You function cannot rely on external tools, that are not part of your deployment.
Config
Configuration is handled via environment variables, similar to what you would do on other PaaS.
Backing services
Lambda functions are attached to resources only via typical AWS mechanism. For example, is the function is reading from a S3 bucket, then the connection is just via the name of the bucket, thus locality is not an issue.
Build, release, run
Lambda deployments are versioned and API Gateways support staging out of the box. Using your own delivery pipeline or Amazon's offering is easy and straightforward.
Processes
Lambdas share nothing - at least from a developer perspective. Data needs to be stored in external data-stores like Dynamo.
Port binding
Lambda functions do not rely on any external server that needs explicit configuration. You only rely on the Lambda container, everything else is abstracted away.
Concurrency
Lambda functions are scaled by request. They are concurrent in nature.
Disposability
Lambda containers are ephemeral. They only exist during the execution of the function. You cannot (easily) ssh into a deployed Lambda. Containers are started, executed, destroyed.
Dev/prod parity
You deploy the Zip onto the AWS Lambda environment. Gaps between environments do not exist, unless you take really effort.
Logs
AWS Lambda logs are streamed via CloudWatch. The functions themselves use console.log and everything else is taken care of by the AWS Lambda runtime.
Admin processes
All Lambda related tasks are possible using the commandline. It is up to the user to use the toolset appropriately.
Finally, one could argue that the Lambda approach fits the 12 Factor App manifest perfectly.
Summary and what's next
Although the 'business logic' might be super trivial, we have actually achieved quiet a lot. Think about what we have build: a super-scalable and secure REST service, that is also extremely cheap. We did not need to provision any servers, install any infrastructure or similar tasks.
Of course, this was not a free lunch.
The ceremony involved for example in creating a simple API Gateway seems rather baroque.
Finally, you need to be at least aware of the risk of vendor lock-in. From my point of view, vendor lock-in is often used as an excuse to build a piece of complex service yourself. But clearly, this cannot be answered for all projects. You need to weigh your options and risks yourself.
In a follow up post, I'll show you how to simplify things using Claudia.JS and how to test your functions using SAM local and we'll dig into an complex example and discuss some architectural patterns.

Top comments (5)
Hi! Great read. One of the authors of arc.codes which is built to make the API Gateway setup/delivery a bit smoother. Just an FYI!
Nice. I am writing a follow up. Maybe I can include your approach.
lmk if you wanna hand getting setup/going (any email to brian.io will find me ;)
Is there something like Heroku for FaaS?
I like the idea, but AWS wants much more from you than simply writing a few functions.
Sure. You can build your own FaaS using Kubeless for example. Auth0 offers WebTask, which may also be worth looking at. (webtask.io/)
In my follow up, I'll look at some of the alternatives.
My issue with Heroku is their billing strategy. As I said with AWS you pay only for the execution time.