This is my story. I’ve been developing various web applications for the past 5 years. Size and domain vary, but most of the time, my primary responsibility is to “ship features”.
Just at the beginning of this month, I transitioned into SRE (Site Reliability Engineer) role. The terminology and its practice were popularized by Google - https://sre.google/ I won’t try to explain what’s already best explained by them.
This blog is to share how my first week went.
I thought I could give u*nique insights into how a seasoned software developer can quickly ramp up himself when changing the course of his career*.
Can this happen in ONE WEEK?
How product developers can lose sight of a system’s runtime
First of all, a bit of justification on why this transition is not a trivial one.
Having been a web application engineer for some time, my focus has been mostly around the codebase; the static snapshot of the system without deep-dive into the runtime.
I’m not saying I didn’t pay attention to where the code is deployed, how to monitor them, etc. My point is that my “most important priority” has been to come up with a scalable “domain model” that’s separated from the underlying system.
Divide enables focus, takes away the holistic understanding.
This tendency is exacerbated by having worked for a bigger company.
What I code, will be deployed to some virtual machine owned by Tier 1 Cloud providers. They have their own abstractions on these machines. This is not inherent to the big companies, but due to the sheer scale of the system, new failure patterns emerge from the distributed architecture.
This is one of the reasons why I need to give myself a ramp-up time, to familiarize myself with the runtime.
Feature shipping mentality
There’s another, much more significant reason why this transition is hard.
In a company with more than thousands of employees, often times the department to own the “feature shipping speed” is different from the department which owns the Core SLOs (Service Level Objectives) of the underlying component. I won’t debate if that’s a good thing or not. This separation certainly enables the concentration and focus of each developer.
However, this has a hidden cost. If you develop too much of a “feature shipping mentality”, you might be cutting a scope that’ll actually save your day when the release happens.

Don’t just ship code. Duh.
Three steps to start your SRE journey
Enough about the background. Below are the three steps I discovered, to maximize the “throughput” of my learning.
1. Pick up the terminology
At this stage, focus on the two things:
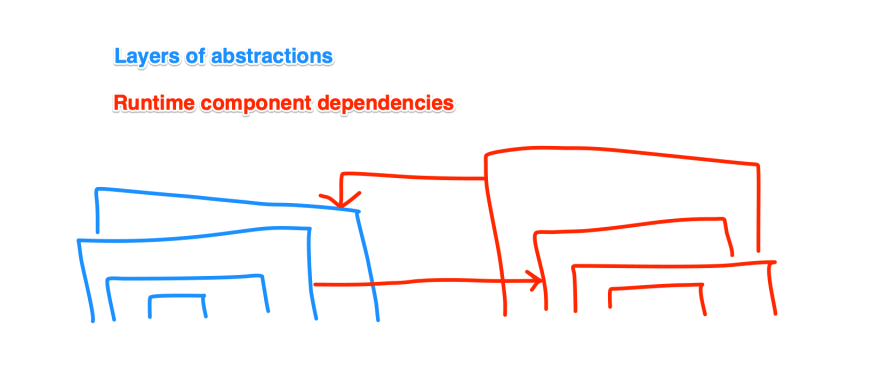
- What and how many layers of abstractions are there to deal with?
- What are the rough dependencies (topology) of each runtime, at various layers of abstractions?
One thing I find amusing is that libraries meant for infrastructure (non-end-user facing in general) sometimes have wild names I have no idea what it’s doing.
It’s not straightforward to unpack these random terminologies. In order not to get lost in its randomness, pay attention to the explanation by its layers.
2. Put yourself in the shoes of the incident responder.
Once your SRE life begins, you'll be paged for a wide variety of things; its breadth and depth vary significantly.
It's almost certain that nobody can prepare for all the possible causes. Then, the question becomes:
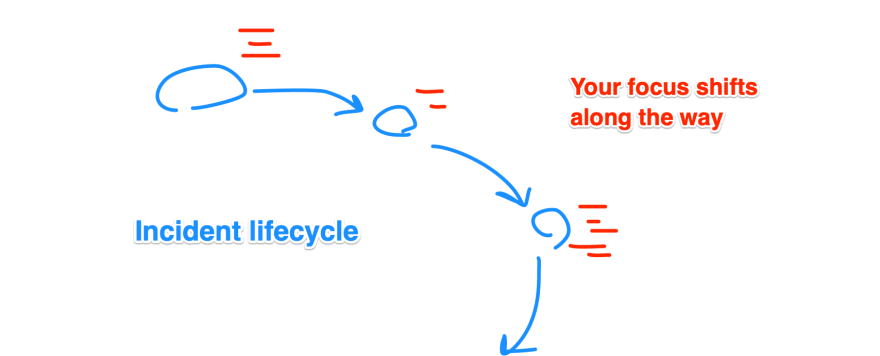
- What is the “incident lifecycle” you can generalize? (Detection, Early impact assessment, offending component identification, …) use your own words so that the learnings stick to your brain.
- In each stage of the incident unfolding, what’s the focus you have to have? Depending on the size/domain of your role, you might be wearing different hats during the lifecycle of an incident.
3. Know ways to keep filling the gaps
Finally, as it was the same for application development, nothing is set in stone. Industry’s practice, tooling, and even preferred incident response communication strategy might change.
- Lean on others. Ask them what they find most useful when they started this journey.
- Look for the industry's go-to books. Buy some to get you started, and buy some more for the reference you can use long-term.
Summary
In this article, I made an attempt to explain how one can transition himself to the SRE role. It turned out to be much more generic than I imagined. Though, I believe this is a good piece of advice 😇 Hope you find it useful too.
This article is written with Suiko, a note app that grows with your thoughts.
This article was first drafted using a note app called “Suiko”. If you’re interested in how to craft your writings, please join the app beta testing form below.
https://kenzan100.substack.com/p/ive-created-an-app-optimized-for





Top comments (0)