
Amazon Kinesis is an AWS service that makes it easy to collect, process and analyze streaming data.
We can define streaming data as the contious flow of data generated by various sources. This can include real-time stock trades, up-to-the-minute retail inventory management, social media feeds, multiplayer games, and ride-sharing apps.
Amazon kinesis makes it easy to ingest real-time data such as application logs, metrics, website clickstreams and IOT telemetry data.
Amazon kinesis is comprised of four key offerings:
- Kinesis Data streams
- Kinesis Video Streams
- Kinesis Data Firehose
- Managed Service For Apache Flink (formerly Kinesis Data Analytics)
Now let's explore these services in more detail.
-
Kinesis Data Streams:
 Kinesis data streams provide you with an easy way to stream big data. They provide you with a platform for continuous processing of streaming data. It can be used to collect log events from servers and other mobile deployments.
A stream is made up of multiple shards. Shards are small partitions into which data can be broken up - in order to keep data across different resources. Shards are numbered numerically and have to be provisioned before hand. For example, if you create a stream with six shards, the data will be split across the different shards. The number of shards determine your stream capacity.
Kinesis data streams provide you with an easy way to stream big data. They provide you with a platform for continuous processing of streaming data. It can be used to collect log events from servers and other mobile deployments.
A stream is made up of multiple shards. Shards are small partitions into which data can be broken up - in order to keep data across different resources. Shards are numbered numerically and have to be provisioned before hand. For example, if you create a stream with six shards, the data will be split across the different shards. The number of shards determine your stream capacity.
Kinesis producers will send data (called records) into the data stream. Records consist of partition key and data blob.
Partition key defines which shard the record will go into. Data blob conatins the value. Producers can send records at a rate of up to 1MB or 1000 messages per second, per shard.
Kinesis consumers will then process the records in the stream. Consumers receive the partition key and sequence number - which represents the position of the record in the shard. Consumers can consume data at a rate of up to 2MB per shard, per consumer.
In a nutshell, producers send data to a data stream,it stays there for a while until it is read by consumers.
Kinesis data stream retention period can be set to between 1 and 365 days. Records that are ingested into the stream are immutable. Also, records that share the same partition go to the same shard. This can be used to provide ordering for your records.
Examples of kinesis producers include: AWS SDK, Kinesis producer library (KPL), kinesis agent, etc.
Examples of kinesis consumers include: AWS SDK, kinesis client library (KPL), Kinesis data firehose, kinesis data analytics, etc.
- Kinesis Video Streams:
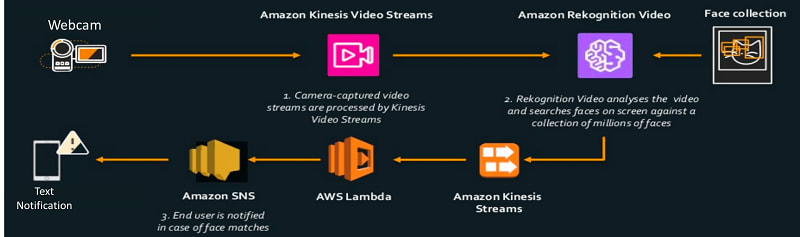
According to AWS, Kinesis Video Streams automatically provisions and elastically scales all the infrastructure needed to ingest streaming video data from millions of devices. It durably stores, encrypts, and indexes video data in your streams, and allows you to access your data through easy-to-use APIs.
Kinesis video streams allow you stream video from any device directly to the cloud, and build applications that process or analyze video content, either in real-time or in batches.
Amazon KVS (kinesis video streams) can be very useful for video surveillance, livestreaming and Internet of Things (IoT).
- Kinesis Data Firehose:

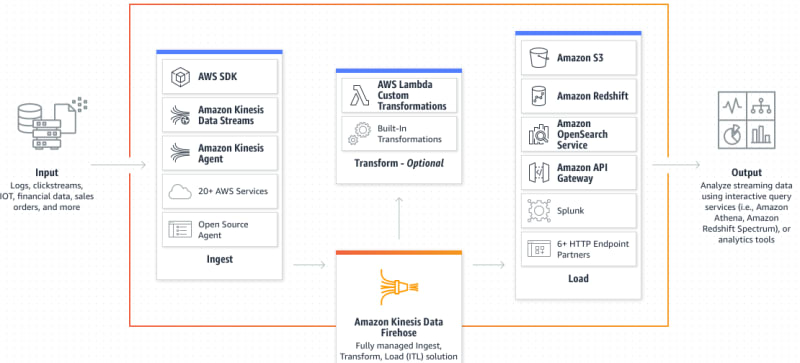
Kinesis Data Firehose allows you to easily capture, transform, and load streaming data. It is an extract, transform, and load (ETL) service that reliably captures, transforms, and delivers streaming data to data lakes, data stores, and analytics services.
Destinations can include Amazon S3, Amazon Redshift, and Elasticsearch. It is fully managed and serverless. Records that ware unsuccessfully consumed can be configured to be sent to a backup S3 bucket.
Producers for kinesis firehose include AWS SDK, kinesis agent, Kinesis data streams, Cloudwatch events and logs, AWs IoT etc. Producers will send records into firehose, firehose can optionally invoke your lambda function to transform incoming source data and deliver the transformed data to destinations.
Destinations are categorized into:
- AWS destinations: S3, Redshift, OpenSearch.
- Third-party destinations: Datadog, Splunk, MongoDB,, New Relic.
- Custom Destinations: HTTP Endpoint.
The picture below is an illustration from AWS that better explains this:
- Managed Service For Apache Flink (formerly Kinesis Data Analytics):

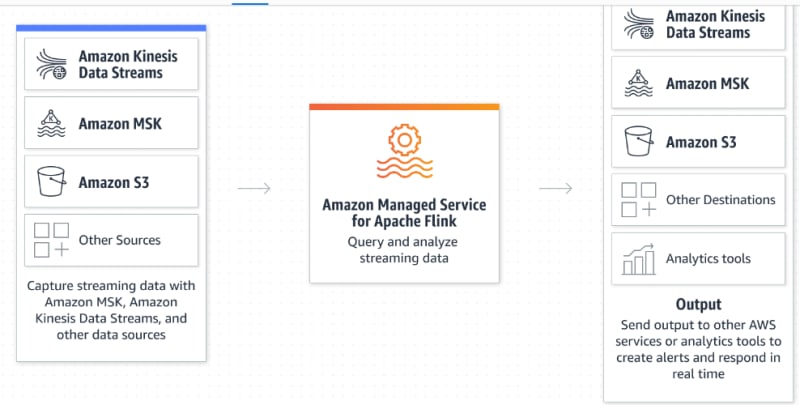
Managed Service for Apache Flink is a fully managed Amazon service that enables you to use an Apache Flink application to process streaming data.
Apache Flink is an open source framework and a distributed processing engine that offers connectors to multiple data sources. It does computations such as joins, aggregations, and extrat, transformation, and load (ETL) capabilities. It allows for advanced real-time techniques such as complex event processing.
With managed service for Apache flink, the producers include Kinesis Data Streams, Amazon S3, Amazon MSK, Kinesis Data Firehose, Amazon OpenSearch Service, CloudWatch etc. The records are received and can be queried and analyzed in real-time. They are then sent to various destinations which can include S3, MSK and Kinesis data streams.
Use cases for this include:
- Real-time analytics: You can interactively query and analyze data streams and continuously produce insights.
- Stateful processing: We can use long-running, stateful computations to initiate real-time actions - such as anomaly detection - based on historical data trends.
- Time-series analytics.
That will be all for now.
I hope this article has helped you gain valuable insights into the overall structure of Amazon Kinesis and how to distinguish between each of its key services.
Connect with me on LinkedIn.





Top comments (0)